1、安装cuda驱动,cuda toolkit和cuDNN
CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程模型,旨在利用GPU(图形处理器)的强大计算能力加速通用计算任务。CUDA驱动是支撑这一生态系统的核心组件之一,它作为操作系统、应用程序与GPU硬件之间的桥梁,直接影响CUDA程序的运行效率和功能支持。CUDA驱动的基本作用硬件通信:管理操作系统对GPU的识别和控制,例如显存分配
1、关键概念区分
CUDA版本通常指的是 CUDA Toolkit(CUDA开发工具包)的版本,而不是显卡驱动的版本。CUDA Toolkit包含编译器、调试工具、库和头文件等开发资源,用于在GPU上进行并行计算。
| 术语 | 含义 | 查看命令 | 重要性 |
|---|---|---|---|
| CUDA Toolkit | NVIDIA 官方提供的开发套件,包含编译器 (nvcc)、库文件 (cuBLAS, cuDNN 等)、运行时环境 |
nvcc --version 或 /usr/local/cuda/version.json |
⭐⭐⭐⭐ (开发/运行必须) |
| Driver API 版本 | 显卡驱动支持的最高 CUDA Runtime API 版本 | nvidia-smi |
⭐⭐ (驱动兼容性参考) |
| CUDA Driver | 显卡驱动程序,负责与 GPU 硬件交互 | nvidia-smi 或 cat /proc/driver/nvidia/version |
⭐⭐⭐ (基础运行环境) |
- 显卡驱动支持的CUDA版本决定了GPU硬件能运行的最高CUDA版本。
- 驱动版本需与CUDA Toolkit版本兼容(驱动版本需大于等于CUDA Toolkit的最低要求)。
2、CUDA驱动
2.1、介绍
CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程模型,旨在利用GPU(图形处理器)的强大计算能力加速通用计算任务。CUDA驱动是支撑这一生态系统的核心组件之一,它作为操作系统、应用程序与GPU硬件之间的桥梁,直接影响CUDA程序的运行效率和功能支持。以下从多个维度对CUDA驱动进行解析:
CUDA驱动的基本作用
CUDA驱动是NVIDIA GPU的底层软件接口,主要功能包括:
-
硬件通信:管理操作系统对GPU的识别和控制,例如显存分配、任务调度、电源管理等。
-
API支持:为上层CUDA Runtime API和CUDA Driver API提供支持,使开发者能够通过代码直接操作GPU。
-
兼容性保障:确保不同版本的CUDA工具包(Toolkit)与GPU硬件之间的兼容性,例如新版本CUDA功能需要特定驱动版本支持。
CUDA驱动的组成与版本管理
-
驱动组件:CUDA驱动包含内核模式驱动(如NVIDIA Linux内核模块
nvidia.ko)和用户模式驱动(如libcuda.so或nvcuda.dll),共同实现硬件资源的安全访问。 -
版本兼容性:
-
驱动版本号:格式为
XXX.XX(例如535.154.02),可通过终端命令nvidia-smi或nvidia-settings查看。 -
CUDA Toolkit依赖:每个CUDA Toolkit版本要求最低驱动版本(如CUDA 12.x需驱动535+),版本不匹配可能导致程序无法运行。
-
向后兼容性:高版本驱动通常支持旧版CUDA Toolkit,反之则受限。
-
核心功能与开发支持
CUDA驱动通过API为开发者提供关键能力:
-
设备管理:枚举GPU设备、查询硬件属性(如计算能力、显存大小)。
-
显存操作:分配/释放设备内存、主机与设备间的数据传输(如
cudaMemcpy)。 -
核函数执行:加载并启动GPU上运行的并行计算内核(Kernel)。
-
异步控制:通过CUDA流(Streams)和事件(Events)实现任务流水线与异步执行。
-
多GPU协同:支持多卡并行计算(如NCCL库)或显存共享(如MIG技术)。
兼容性与硬件支持
-
GPU架构限制:不同GPU架构(如Kepler、Volta、Ampere)对CUDA版本的支持范围不同。例如,Ampere架构(如A100)需CUDA 11.0+驱动。
-
操作系统适配:CUDA驱动支持Windows、Linux和macOS(截至2023年,NVIDIA已停止对macOS的CUDA驱动更新)。
-
图形与计算共存:驱动同时支持图形渲染(如OpenGL/DirectX)和计算任务,可通过
CUDA_VISIBLE_DEVICES隔离GPU用途。
安装与维护
-
安装方式:
-
手动安装:从NVIDIA官网下载驱动包(
.run文件或.exe安装程序)。 -
包管理器:Linux下可通过
apt(Ubuntu)或yum(RHEL)安装。 -
自动化工具:使用
cuda-toolkit包或容器镜像(如NVIDIA Docker)简化环境部署。
-
-
常见问题:
-
版本冲突:安装新驱动前需卸载旧版本,避免残留文件导致异常。
-
内核签名:Linux系统需禁用Secure Boot或签名内核模块。
-
依赖缺失:如Linux下的
gcc或kernel-devel包未安装可能引发编译错误。
-
典型应用场景
-
深度学习框架:TensorFlow/PyTorch依赖CUDA驱动加速模型训练。
-
科学计算:如流体模拟(FEM)、分子动力学(LAMMPS)利用GPU并行计算。
-
图形渲染混合:结合OptiX实现光线追踪与通用计算混合工作流。
未来演进方向
-
统一驱动架构:NVIDIA正推动GPU驱动向开源(如Nouveau驱动协作)和标准化发展。
-
虚拟化增强:对云环境(如vGPU、MIG)的支持优化,提升资源利用率。
-
安全与能效:引入硬件级安全特性(如TEE)和动态功耗管理(DVFS)。
总结
CUDA驱动是NVIDIA GPU计算生态的基石,其版本管理与功能支持直接影响开发效率和程序性能。开发者需根据硬件架构、操作系统和CUDA Toolkit版本选择合适的驱动,并通过持续更新以兼容新技术(如Hopper架构、CUDA动态并行)。理解其工作原理与兼容性规则,是优化GPU加速应用的关键一步。
2.2、安装驱动
Nouveau 和英伟达驱动冲突,如运行,需禁用:
# 检查 Nouveau驱动 是否已启用
lsmod | grep nouveau
# 如果输出包含 nouveau 相关的条目(例如 nouveau, nvidia, 等),说明 Nouveau 驱动正在运行。
# 如果没有任何输出,说明 Nouveau 驱动未加载。# 禁用 Nouveau 驱动
echo "blacklist nouveau" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
echo "options nouveau modeset=0" | sudo tee -a /etc/modprobe.d/blacklist-nouveau.conf
sudo update-initramfs -u
sudo reboot如果只是需要安装英伟达驱动,或者是应用于生产环境,可继续查看本节。如果需要安装cuda toolkit进行AI开发,请直接跳到安装cuda toolkit部分。
2.2.1、通过 Ubuntu 官方仓库安装(更简单)
sudo apt update
sudo apt install nvidia-driver-570
sudo reboot更新驱动:
ubuntu-drivers autoinstall # 自动安装推荐驱动2.2.2、通过官网安装
到官网NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA搜索对应系统和显卡的驱动版本。
消费级显卡都是采用相同的驱动,下载地址:驱动程序
查询ubantu系统架构:
$ uname -m x86_64 # Intel/AMD 64位架构(常规PC或服务器) aarch64 # ARM 64位架构(如基于ARM的服务器或树莓派等设备)
赋予可执行权限
chmod +x ~/NVIDIA-Linux-x86_64-570.153.02.run以 root 权限运行驱动安装程序:
sudo ./NVIDIA-Linux-x86_64-570.153.02.run2.2.3、查看安装的驱动版本
nvidia-smi(llm) wangqiang@wangqiang:~$ nvidia-smi Wed May 21 23:38:04 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.133.07 Driver Version: 570.133.07 CUDA Version: 12.8 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:18:00.0 Off | N/A | | 41% 36C P8 17W / 350W | 18MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA GeForce RTX 3090 Off | 00000000:C3:00.0 On | N/A | | 41% 40C P8 11W / 350W | 172MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 2016 G /usr/lib/xorg/Xorg 4MiB | | 1 N/A N/A 2016 G /usr/lib/xorg/Xorg 103MiB | | 1 N/A N/A 2134 G /usr/bin/gnome-shell 13MiB | +-----------------------------------------------------------------------------------------+驱动版本,Driver Version: 570.133.07
CUDA Version: 12.8。表示当前驱动支持的最高 CUDA 版本为 12.8。
2.2.4、卸载驱动
# 卸载 NVIDIA 驱动及相关包
sudo apt-get purge nvidia*
# 清理残留配置
sudo apt-get autoremove
sudo apt-get autoclean停止所有使用 GPU 的进程
sudo systemctl stop gdm.service # 停止图形界面服务
sudo systemctl stop lightdm # 如果使用 LightDM
sudo systemctl stop nvidia-persistenced # 停止 NVIDIA 持久化服务卸载 NVIDIA 内核模块
sudo rmmod nvidia_uvm
sudo rmmod nvidia_drm
sudo rmmod nvidia_modeset
sudo rmmod nvidia如果提示模块正在使用(rmmod: ERROR: Module nvidia_uvm is in use)
sudo lsof /dev/nvidia* # 查看占用 GPU 的进程
sudo kill -9 <PID> # 杀掉占用进程(替换 <PID> 为实际进程号)3、CUDA Toolkit
3.1、介绍
CUDA Toolkit 是 NVIDIA 为开发者提供的一套完整的并行计算平台和编程工具集,专为利用 GPU(图形处理器)的并行计算能力而设计。CUDA Toolkit 提供了从底层硬件接口到高层开发库的全栈工具,使开发者能够高效地将计算密集型任务迁移到 GPU 上执行,显著提升性能。
核心架构
CUDA 的核心思想是将计算任务分解为大量并行线程,通过 GPU 的数千个计算核心同时执行。CUDA 扩展了 C/C++ 语言,引入了 __global__、__device__ 等关键字,允许开发者在代码中定义 GPU 核函数(Kernel)。通过 nvcc 编译器,这些混合了 CPU(主机)和 GPU(设备)代码的程序可以被编译为可在 NVIDIA GPU 上执行的二进制文件。CUDA 的编程模型基于 SIMT(单指令多线程)架构,支持数千个线程并行执行,并通过网格(Grid)、线程块(Block)和线程(Thread)的层级结构管理并行任务。
工具包组件
CUDA Toolkit 包含以下关键组件:
-
编译器(NVCC):将 CUDA 代码编译为 GPU 可执行的二进制文件,同时支持与主机端 CPU 代码的混合编译。
-
数学库:如 cuBLAS(线性代数)、cuFFT(傅里叶变换)、cuRAND(随机数生成)等,提供高度优化的 GPU 加速函数。
-
调试与分析工具:
-
Nsight 系列:集成开发环境支持代码调试(Nsight Visual Studio/VSCode)和性能分析(Nsight Systems/Compute)。
-
nvprof/nvvp:性能分析器,帮助定位计算瓶颈和内存访问问题。
-
-
多 GPU 通信库:如 NCCL(集合通信)和 NVSHMEM,优化分布式计算场景下的数据传输。
-
运行时 API 与驱动:管理 GPU 设备、内存分配和任务调度。
应用场景
-
深度学习:与 TensorFlow、PyTorch 等框架集成,利用 GPU 加速模型训练。
-
科学模拟:加速流体力学、分子动力学等计算密集型任务。
-
实时渲染:结合 OptiX 光线追踪引擎,提升图形渲染效率。
-
数据分析:加速大数据处理、数据库查询等操作。
优势与生态
-
性能提升:相比 CPU,GPU 在并行任务中可实现数十至数百倍加速。
-
跨平台支持:兼容 Windows、Linux 和 macOS(部分功能受限),支持 x86、ARM 等架构。
-
开放生态:与 OpenACC、OpenCL 等标准互补,并通过 cuDNN、TensorRT 等工具链扩展 AI 应用。
-
社区资源:NVIDIA 开发者社区提供丰富的文档、代码示例和培训课程。
系统要求
CUDA Toolkit 需搭配 NVIDIA GPU(计算能力 3.5 及以上)和对应驱动程序。最新版本(如 CUDA 12.x)支持安培架构(如 A100、RTX 40系列)的新特性,如异步复制、张量内存增强等。
总结
CUDA Toolkit 是 GPU 加速计算的基石技术,通过软硬件协同设计释放并行计算潜力。其成熟的工具链和广泛的应用生态,使其成为高性能计算和人工智能领域的核心开发平台。随着异构计算的发展,CUDA 持续推动着科学研究和工业应用的性能边界。开发者可通过 NVIDIA 官方文档和社区资源快速入门,将 GPU 的算力转化为实际生产力。
3.2、CUDA Toolkit 安装和卸载
安装包中的驱动是 开发版本,主要用于开发和调试 CUDA 应用程序,不建议在生产环境中使用。生产环境应使用 NVIDIA 官方推荐的独立显卡驱动。
3.2.1、通过 APT 安装
注意:通过此方式安装的 CUDA 版本可能较旧(如 7.5),如果需要最新版本,请通过官网安装。
# 安装 nvidia-cuda-toolkit
sudo apt update
sudo apt install nvidia-cuda-toolkit
# 验证安装
nvcc --version3.2.2、通过官网安装
查看cuda 12.8支持的版本:1. CUDA 12.8 Release Notes — Release Notes 12.8 documentation
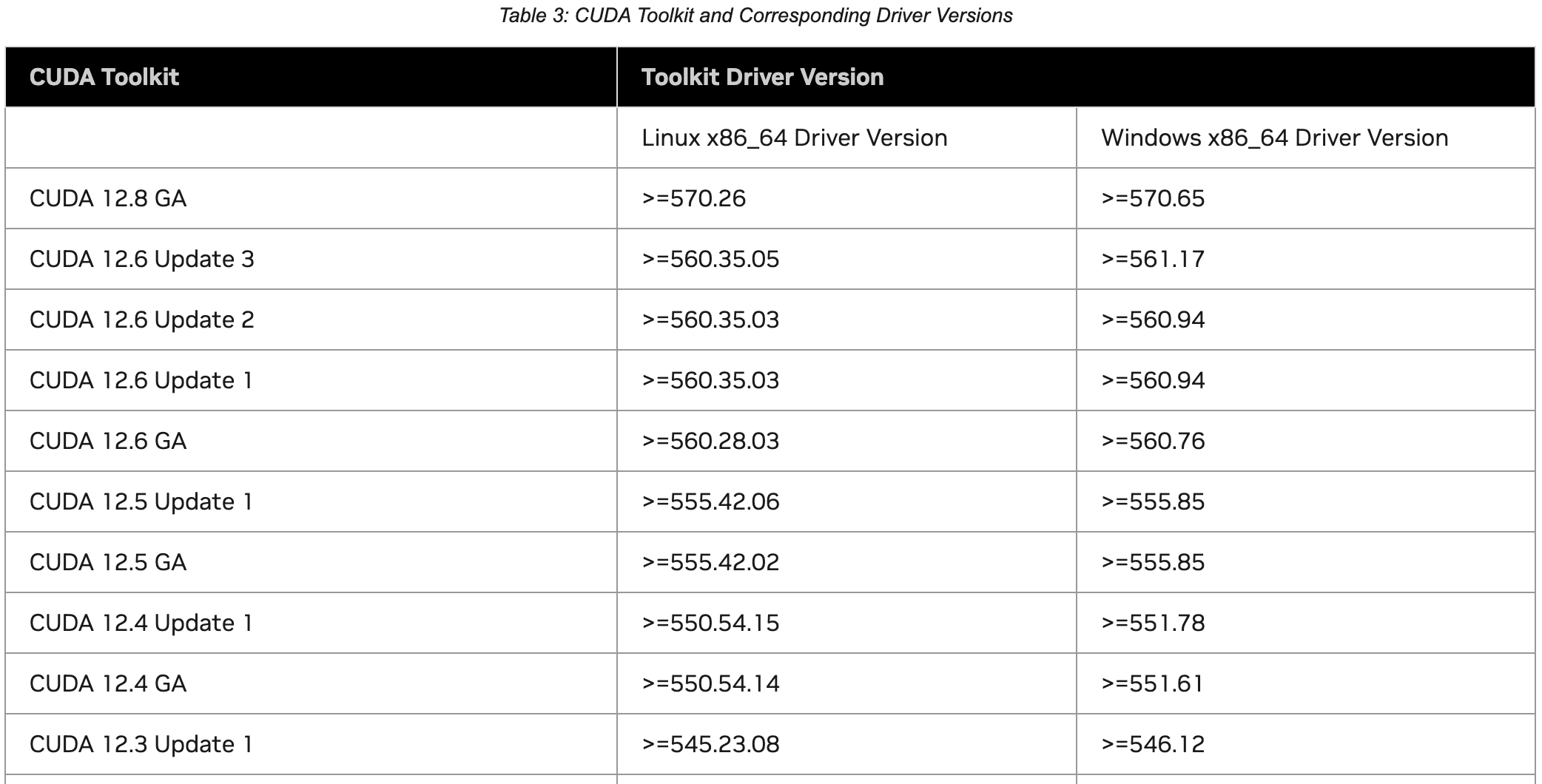
通过官网下载:CUDA Toolkit Archive | NVIDIA Developer
deb (local)
- 核心特点:本地离线安装
- 适用条件:已下载.deb文件 + 无网络环境
- 典型场景:企业内网部署、应急修复系统
deb (network)
- 核心特点:在线自动更新
- 适用条件:Ubuntu/Debian系统 + 稳定网络
- 典型场景:日常软件更新、依赖自动管理
runfile (local)
- 核心特点:自包含安装包
- 适用条件:跨平台需求 + 复杂部署
- 典型场景:NVIDIA驱动安装、定制化部署

wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
sudo sh cuda_12.8.0_570.86.10_linux.run安装成功:
(llm) wangqiang@wangqiang:~$ sudo sh cuda_12.8.0_570.86.10_linux.run
===========
= Summary =
===========Driver: Installed
Toolkit: Installed in /usr/local/cuda-12.8/Please make sure that
- PATH includes /usr/local/cuda-12.8/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-12.8/lib64, or, add /usr/local/cuda-12.8/lib64 to /etc/ld.so.conf and run ldconfig as rootTo uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-12.8/bin
To uninstall the NVIDIA Driver, run nvidia-uninstall
Logfile is /var/log/cuda-installer.log
配置环境变量
方式1:用户级永久生效
# 编辑 ~/.bashrc 文件:
sudo nano ~/.bashrc
# 在文件末尾添加以下内容:
export PATH=/usr/local/cuda-12.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH
# 使配置生效:
source ~/.bashrc
方式2:对所有用户(系统级)永久生效
# 编辑 /etc/profile
sudo nano /etc/profile
# 添加环境变量
export PATH=/usr/local/cuda-12.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH
# 使配置生效:
source /etc/profile3.2.3、验证安装
# 检查 CUDA 工具链
nvcc --version
# 检查 NVIDIA 驱动状态
nvidia-smi通过官网安装的cuda toolkit(开发环境版本)
wangqiang@wangqiang:~$ nvidia-smi
Sat May 24 22:52:18 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.10 Driver Version: 570.86.10 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:18:00.0 Off | N/A |
| 30% 47C P0 114W / 350W | 1MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:C3:00.0 Off | N/A |
| 30% 51C P0 108W / 350W | 1MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
wangqiang@wangqiang:~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:20:09_PST_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0
3.2.4、卸载
# 删除 nvidia-cuda-toolkit 及其依赖项
sudo apt remove nvidia-cuda-toolkit
sudo apt autoremove # 删除依赖包
# 如果卸载后仍有残留文件(如 /usr/local/cuda 路径或环境变量配置),可手动清理
# 删除 CUDA 安装目录(如通过 .run 文件安装过 CUDA):
sudo rm -rf /usr/local/cuda*
# 清理环境变量:
# 编辑 ~/.bashrc 或 /etc/profile.d/cuda.sh,删除以下行:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# 保存文件后执行:
source ~/.bashrc4、cuDNN
4.1、介绍
cuDNN(CUDA Deep Neural Network Library)是由NVIDIA推出的专为深度学习任务设计的高性能GPU加速库。作为CUDA生态系统的核心组件之一,cuDNN通过高度优化的算法实现,显著提升了深度神经网络训练和推理的效率,已成为AI开发领域的行业标准工具。
核心功能与特性
cuDNN专注于为常见深度学习操作提供底层加速支持,其主要功能包括:
-
基础算子优化:提供卷积、池化、归一化(BatchNorm)、激活函数(ReLU、Sigmoid等)和注意力机制的高效GPU实现,针对不同数据尺寸和硬件架构自动选择最优算法。
-
张量运算加速:支持4D/5D张量的高效内存布局管理,优化矩阵乘法和张量变换(如转置、填充)操作,尤其擅长处理图像、视频等高维数据。
-
动态算法选择:通过内置的自动调优器(Auto-Tuner),实时分析输入数据和硬件配置,动态匹配最佳计算策略以最大化吞吐量。
-
混合精度支持:集成FP16、TF32和INT8等低精度计算模式,结合Tensor Core技术实现4-8倍性能提升,同时保持模型精度。
技术优势
cuDNN通过以下设计实现性能突破:
-
硬件感知优化:针对NVIDIA各代GPU架构(如Volta、Ampere)进行指令级优化,充分利用Tensor Core和共享内存特性。
-
内存复用策略:采用智能内存预分配和复用机制,减少显存分配开销,降低延迟。
-
跨框架兼容性:提供C/C++ API接口,无缝支持TensorFlow、PyTorch、MXNet等主流框架,开发者无需修改模型代码即可获得加速。
-
版本迭代演进:持续更新算法库(如支持分组卷积、稀疏卷积等新型网络结构),保持与前沿研究的同步。
应用场景
cuDNN广泛应用于计算机视觉(ResNet、YOLO)、自然语言处理(BERT、GPT)、科学计算等领域,支撑从云端超算到边缘设备的全场景AI部署。典型应用案例包括:
-
训练千亿参数大语言模型时优化Transformer层计算
-
加速医疗影像分析中的3D卷积运算
-
提升自动驾驶系统的实时目标检测帧率
生态系统定位
作为NVIDIA计算堆栈的关键层级,cuDNN与CUDA驱动层、cuBLAS数学库及TensorRT推理引擎协同工作,构成完整的GPU加速开发生态。其闭源特性促使开发者通过框架接口调用,而开源替代方案(如MIOpen)则在特定场景展开竞争。
cuDNN通过持续优化深度学习的计算密集型操作,大幅降低了AI模型的开发门槛和训练成本,已成为推动深度学习技术进步的基础设施级工具。其价值不仅体现在性能提升,更在于为复杂算法创新提供了可靠的底层支撑,加速了AI技术从研究到产业落地的进程。
4.2、安装cuDNN
cuDNN是基于 CUDA 的深度神经网络加速库,专为卷积、池化、归一化等深度学习操作优化。它不包含在 CUDA Toolkit 中,需单独安装。
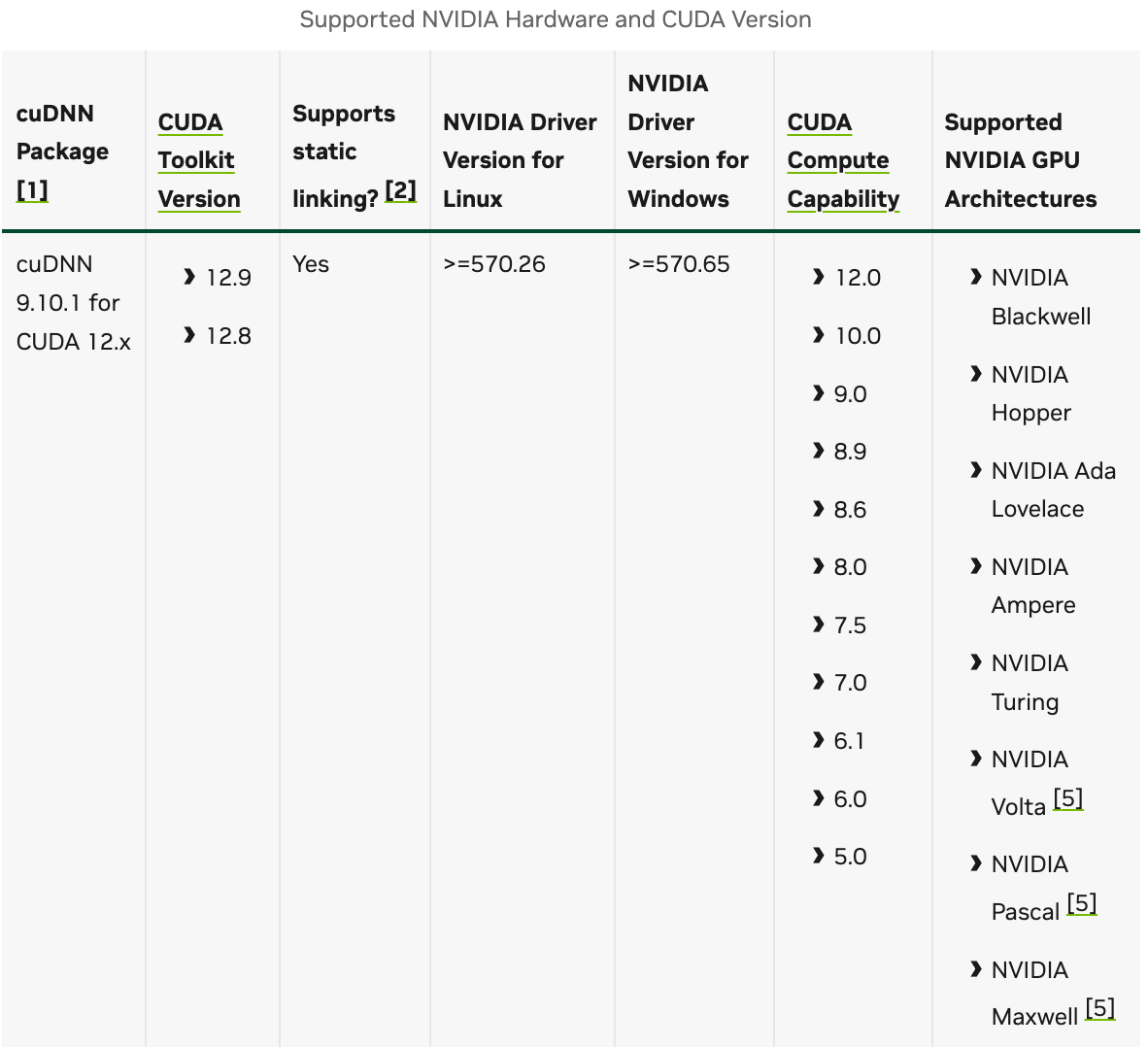
cuDNN 的版本需要与 CUDA Toolkit 版本严格匹配。
到官网查看版本兼容性:Support Matrix — NVIDIA cuDNN Backend
查询cuda toolkit版本:
wangqiang@wangqiang:~$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Wed_Jan_15_19:20:09_PST_2025 Cuda compilation tools, release 12.8, V12.8.61 Build cuda_12.8.r12.8/compiler.35404655_0 # nvcc:NVIDIA CUDA 编译器驱动程序,用于编译 CUDA 程序(.cu 文件) # 12 表示 CUDA 的大版本(如 11.x、12.x)。8 表示该主版本下的迭代版本。61 是补丁版本。查看 NVIDIA 驱动版本:
wangqiang@wangqiang:~$ nvidia-smi Sun May 25 11:48:12 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.86.10 Driver Version: 570.86.10 CUDA Version: 12.8 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 Off | 00000000:18:00.0 Off | N/A | | 30% 46C P0 113W / 350W | 1MiB / 24576MiB | 2% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA GeForce RTX 3090 Off | 00000000:C3:00.0 Off | N/A | | 30% 51C P0 107W / 350W | 1MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
- NVIDIA-SMI 版本:
570.86.10是nvidia-smi工具的版本号,通常与 NVIDIA 驱动版本一致。- Driver Version:
570.86.10是当前安装的 NVIDIA 驱动程序版本。- CUDA Version:
12.8表示该驱动支持的最高 CUDA 版本(非当前安装的 CUDA Toolkit 版本)。
- 注意:
nvidia-smi显示的 CUDA 版本是驱动支持的版本,而nvcc -V显示的是 CUDA Toolkit 版本。两者需满足兼容性要求(驱动版本 ≥ CUDA Toolkit 的最低要求)。- GPU ID:
0表示第一块 GPU(系统中有 2 块 GPU)。- GPU 名称:
NVIDIA GeForce RTX 3090是显卡型号。- Persistence-M(持久模式):
Off表示未启用持久模式。持久模式在无任务时保持驱动加载,减少启动延迟。- Bus-Id:
00000000:18:00.0是 GPU 在 PCIe 总线上的物理地址。- Display Active(Disp.A):
Off表示该 GPU 未连接显示器。- Volatile Uncorr. ECC:
N/A表示未启用 ECC(错误纠正代码),RTX 3090 不支持 ECC。- Fan:
30%表示风扇转速为 30%(0%-100%)。- Temp:
46C表示 GPU 温度为 46°C(正常范围通常为 30-85°C)。- Perf:
P0表示性能状态为最大性能(P0-P12,P0 最高)。- Pwr:Usage/Cap:
- Usage:
113W表示当前功耗。- Cap:
350W表示 GPU 的最大功耗限制(TDP)。- Memory-Usage:
1MiB / 24576MiB表示当前显存使用量为 1MiB(几乎未使用),总显存为 24576MiB(约 24GB)。- GPU-Util:
2%表示 GPU 当前利用率(计算任务使用率)。- Compute M.:
Default表示计算模式为默认模式(允许多个进程共享 GPU)。- MIG M.:
N/A表示不支持 MIG(多实例 GPU 虚拟化)。查看ubuntu系统版本:
wangqiang@wangqiang:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 22.04.5 LTS Release: 22.04 Codename: jammy
通过官网下载:
CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
需要直接使用GPU加速功能(如深度学习框架开发/模型训练)
→ 下载 cuDNN Library(包含完整函数和优化库)需要简化cuDNN调用接口(尤其是复杂神经网络场景)
→ 下载 cuDNN Frontend(提供用户友好型高级API)不确定需求或需要指导
→ 先查阅 Documentation(含安装指南/API说明/示例代码)
cuDNN 9.10.1下载 地址:cuDNN 9.10.1 Downloads | NVIDIA Developer
特性 deb (local)deb (network)网络需求 仅需下载阶段联网 安装全程需联网 依赖管理 需手动解决依赖问题 自动通过 apt解析依赖安装灵活性 可离线使用 依赖网络环境 操作复杂度 较高(分步操作) 较低(一键安装) 适用场景 离线环境、定制化部署 快速安装、在线环境
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb sudo dpkg -i cuda-keyring_1.1-1_all.deb sudo apt-get update sudo apt-get -y install cudnn查看安装的版本:
wangqiang@wangqiang:~$ find /usr -name "cudnn_version.h" # 查找安装的位置 find: ‘/usr/share/ollama/.nv’: 权限不够 /usr/include/x86_64-linux-gnu/cudnn_version.h wangqiang@wangqiang:~$ cat /usr/include/x86_64-linux-gnu/cudnn_version.h | grep CUDNN_MAJOR -A 2 # 查看安装的版本 #define CUDNN_MAJOR 9 #define CUDNN_MINOR 10 #define CUDNN_PATCHLEVEL 1 -- #define CUDNN_VERSION (CUDNN_MAJOR * 10000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL) /* cannot use constexpr here since this is a C-only file */


欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)