CUDA编程 | 5.6 线程束洗牌指令
本文介绍线程束洗牌指令的一些用法,不需要通过内存进行线程间数据交换,具有非常高的性能。
目录
注:此博客是对谭升的博客的一些学习感悟,详细内容请移步谭升的博客进行学习
5.6 线程束洗牌指令
线程束洗牌指令的不同形式
线程束洗牌指令有两组:一组用于整形变量,另一组用于浮点型变量。一共有四种形式的洗牌指令。
在线程束内交换整形变量,其基本函数如下:
int __shfl(int var,int srcLane,int width=warpSize);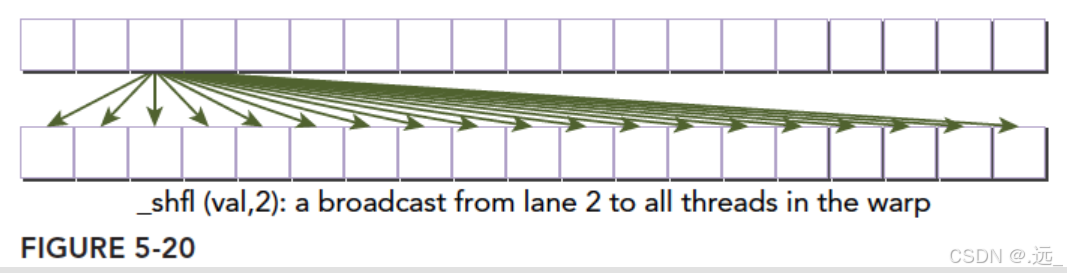
下面是对个指令的详细解释:
-
函数签名解释:
int __shfl(int var, int srcLane, int width=warpSize);- 这个函数接受三个参数:
int var:当前线程中的一个整型变量,从另一个线程中获取这个变量的值。int srcLane:源线程的位置(或称为束内线程ID),从哪个线程的var中获取值。注意,这里的位置是基于width参数来计算的。int width=warpSize:warp的大小,即warp中线程的数量。默认值是warp的大小,对于大多数NVIDIA GPU,这个值是32。这个参数决定了srcLane的有效范围。
-
参数的作用:
- var:
var不是简单地传递它的值,而是作为一个标识符,你想从另一个线程中获取这个标识符所代表的变量的值。每个线程都有自己的var变量,它们可能存储不同的值。 - srcLane:这个参数指定了你想从哪个线程获取
var的值。它不是基于当前线程的,而是基于warp的全局视角来计算的。例如,如果width=16,并且你想获取第3个线程的var值,那么对于warp中的每个线程组(0-15, 16-31,...),你会分别获取到第3个和第19个线程的var值。
- var:
-
width参数的重要性:
- 当
width等于warp的大小时(默认为32),srcLane参数直接对应于warp内的线程ID。 - 如果
width被设置为小于warp大小的值,那么srcLane的计算会基于当前的warp被划分成的更小的“虚拟warp”或“分段”来进行。这增加了__shfl指令的灵活性,但也可能导致理解上的复杂性。
- 当
从与调用线程相关的线程中复制数据:
int __shfl_up(int var,unsigned int delta,int with=warpSize);
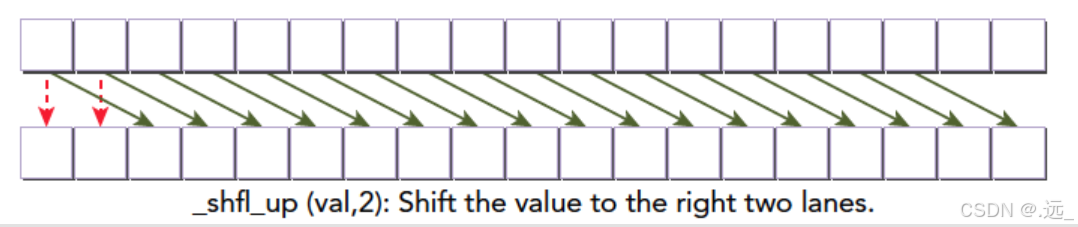
下面是对__shfl_up函数内容的详细解释:
函数签名解释
int var:这是当前线程中的一个整型变量,希望获取相对于当前线程位置向上(向左,如果我们按照线程ID递增的顺序从左到右排列线程的话)偏移delta个位置的线程的var变量的值。unsigned int delta:这是希望向上(向左)移动的线程数量。换句话说,它指定了想要从哪个更“左边”的线程中获取var的值。int width=warpSize:这指定了warp的大小,或者更具体地说,是考虑用于shuffle操作的线程组的宽度。默认值是warpSize,对于大多数NVIDIA GPU来说,这个值是32。这个参数决定了delta参数的有效范围,并且影响了shuffle操作如何跨越线程。
函数的作用
__shfl_up函数允许在一个warp内的不同线程之间高效地交换数据。它特别适用于需要线程间通信的并行算法,比如前缀和、归约操作等。
- 当调用
__shfl_up(var, delta, width)时,函数会返回当前warp内相对于当前线程向上(向左)偏移delta个位置的线程的var变量的值。 - 如果
delta的值大于或等于当前线程在其warp内的ID,那么函数将返回未定义的值,因为不存在这样的“左边”线程。 width参数允许您指定一个更小的线程组大小来执行shuffle操作。如果width小于warpSize,那么warp会被划分成更小的块,每个块独立地执行shuffle操作。
特殊情况处理
- 最左边的线程(即线程ID为0,
width,2*width, ...的线程)没有“左边”的线程来提供var的值,因此对于这些线程,__shfl_up函数将返回它们自己的var值。换句话说,这些线程不会从其他线程获取任何值。 - 如果
delta的值大于或等于warp内线程的总数(或者,如果指定了width,则大于或等于每个块内的线程数),那么对于所有线程来说,__shfl_up也将返回未定义的值。
示例说明
假设我们有一个warp,其中包含8个线程(为了简化说明,尽管通常warp大小为32),并且我们调用__shfl_up(var, 2, 8):
- 线程0和线程1没有“左边”的两个线程,因此它们将返回它们自己的
var值。 - 线程2将从线程0获取
var的值(因为它向左移动了2个位置)。 - 线程3将从线程1获取
var的值。 - 线程4将从线程2获取
var的值。 - 以此类推,直到线程7,它尝试从线程5获取
var的值(尽管在这个简化的例子中,线程7实际上会超出边界,但因为我们假设了width=8,所以这里不会发生未定义行为)。
下一个指令是上面的反转版本
int __shfl_down(int var,unsigned int delta,int with=warpSize);
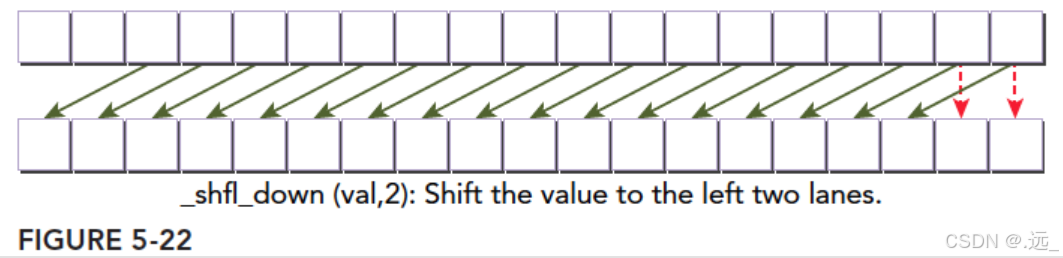
最后一个洗牌指令
int __shfl_xor(int var,int laneMask,int with=warpSize);
xor是异或操作,二元操作,只要两个不同就会得到真,否则为假
如果我们输入的laneMask是1,其对应的二进制是 000⋯001000⋯001 ,当前线程的索引是0~31之间的一个数,那么我们用laneMask与当前线程索引进行抑或操作得到的就是目标线程的编号了,这里laneMask是1,那么我们把1与0~31分别抑或就会得到:
000001^000000=000001;
000001^000001=000000;
000001^000010=000011;
000001^000011=000010;
000001^000100=000101;
000001^000101=000100;
.
.
.
000001^011110=011111;
000001^011111=011110;这就是当前线程的束内线程编号和目标线程束内县城编号之间的对应关系
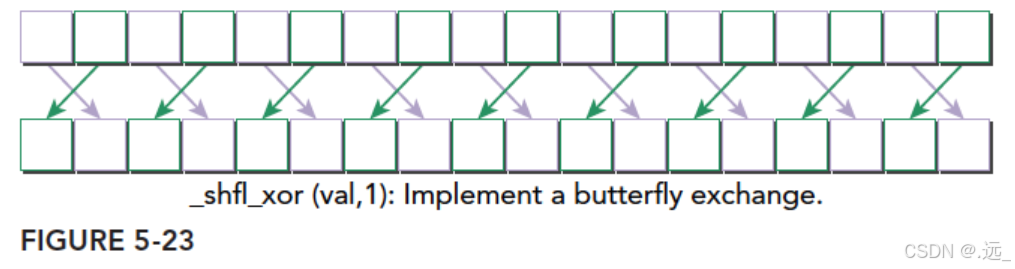
这就是4个线程束洗牌指令对整形的操作了。对应的浮点型不需要该函数名,而是只要把var改成float就行了,函数就会自动重载了。
线程束内的共享内存数据
洗牌指令可以用于下面三种整数变量类型中:
- 标量变量
- 数组
- 向量型变量
跨线程束值的广播
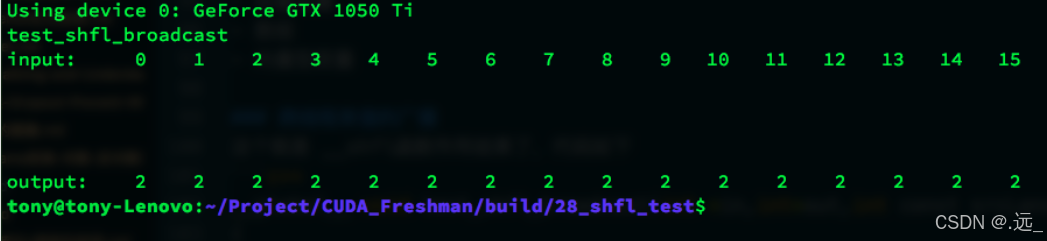
__global__ void test_shfl_broadcast(int *in,int*out,int const srcLans)
{
int value=in[threadIdx.x];
value=__shfl(value,srcLans,BDIM);
out[threadIdx.x]=value;
}var参数对应value就是我们要找的目标,srcLane这里是2,所以,我们取得了2号书内线程的value值给了当前线程,于是所有束内线程的value都是2了
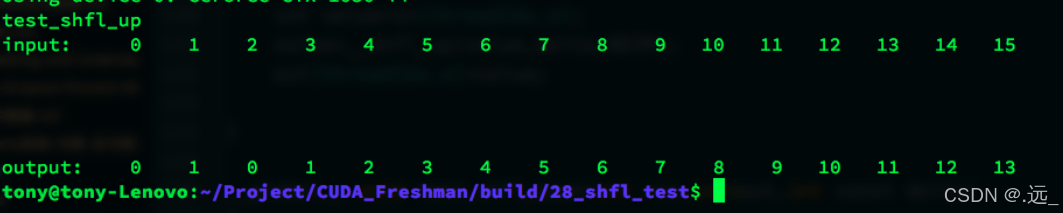
线程束内上移
__global__ void test_shfl_up(int *in,int*out,int const delta)
{
int value=in[threadIdx.x];
value=__shfl_up(value,delta,BDIM);
out[threadIdx.x]=value;
}
线程束内下移
__global__ void test_shfl_down(int *in,int*out,int const delta)
{
int value=in[threadIdx.x];
value=__shfl_down(value,delta,BDIM);
out[threadIdx.x]=value;
}
线程束内环绕移动
__global__ void test_shfl_wrap(int *in,int*out,int const offset)
{
int value=in[threadIdx.x];
value=__shfl(value,threadIdx.x+offset,BDIM);
out[threadIdx.x]=value;
}当offset=2的时候,得到结果:

前14个元素的值是可以预料到的,但是14号,15号并没有像shfl_down那样保持不变,而是获得了0号和1号的值,那么我们有必要相信,shfl中计算目标线程编号的那步有取余操作,对with取余,我们真正得到的数据来自
1 |
srcLane=srcLane%width; |
这样就说的过去了,同理我们通过将srclane设置成-2的话就能得到对应的向上的环绕移动。
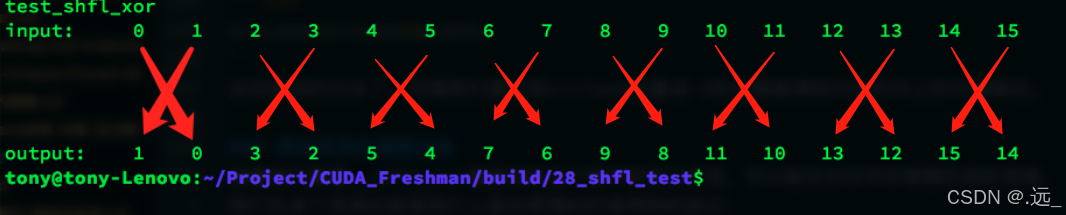
跨线程束的蝴蝶交换
__global__ void test_shfl_xor(int *in,int*out,int const mask)
{
int value=in[threadIdx.x];
value=__shfl_xor(value,mask,BDIM);
out[threadIdx.x]=value;
}
跨线程束交换数组值
__global__ void test_shfl_xor_array(int *in,int*out,int const mask)
{
//1.
int idx=threadIdx.x*SEGM;
//2.
int value[SEGM];
for(int i=0;i<SEGM;i++)
value[i]=in[idx+i];
//3.
value[0]=__shfl_xor(value[0],mask,BDIM);
value[1]=__shfl_xor(value[1],mask,BDIM);
value[2]=__shfl_xor(value[2],mask,BDIM);
value[3]=__shfl_xor(value[3],mask,BDIM);
//4.
for(int i=0;i<SEGM;i++)
out[idx+i]=value[i];
}这里的代码运行结果如下
这里我对博主的解释并不是特别理解,个人画图得出的解释是将0-15在8的位置划分成两组,0-7和8-15,然后对第一组的开头和结尾两个数据进行交换,第二组也是一样的操作,具体的示意图如下:当然这只是我的理解,不知道是否正确
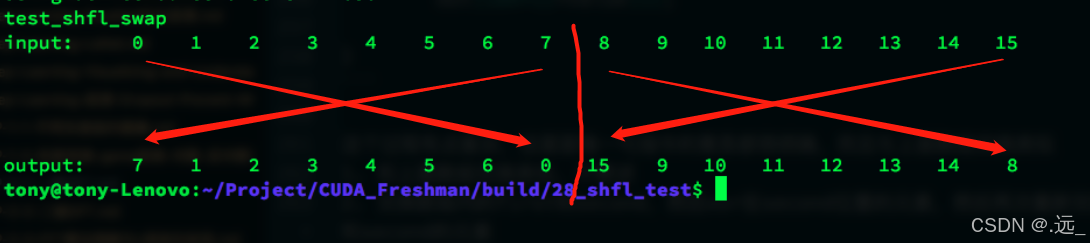
跨线程束不是跨越线程束,而是横跨当前线程束的意思
跨线程束使用数组索引交换数值
__inline__ __device__
void swap(int *value,int laneIdx,int mask,int firstIdx,int secondIdx)
{
bool pred=((laneIdx%(2))==0);
if(pred)
{
int tmp=value[firstIdx];
value[firstIdx]=value[secondIdx];
value[secondIdx]=tmp;
}
value[secondIdx]=__shfl_xor(value[secondIdx],mask,BDIM);
if(pred)
{
int tmp=value[firstIdx];
value[firstIdx]=value[secondIdx];
value[secondIdx]=tmp;
}
}
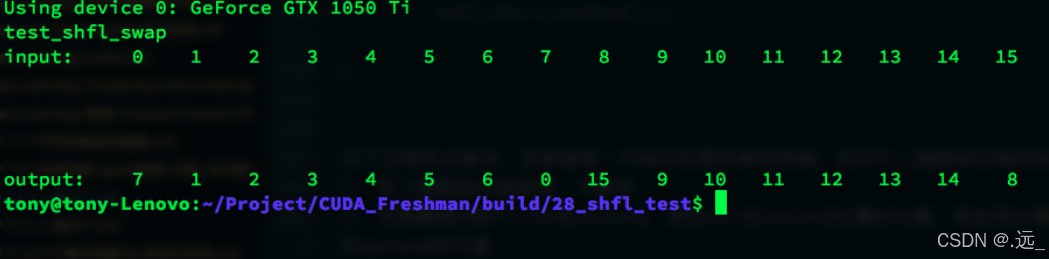
__global__ void test_shfl_swap(int *in,int* out,int const mask,int firstIdx,int secondIdx)
{
//1.
int idx=threadIdx.x*SEGM;
int value[SEGM];
for(int i=0;i<SEGM;i++)
value[i]=in[idx+i];
//2.
swap(value,threadIdx.x,mask,firstIdx,secondIdx);
//3.
for(int i=0;i<SEGM;i++)
out[idx+i]=value[i];
}下面的图对交换的过程进行了非常详细的解释
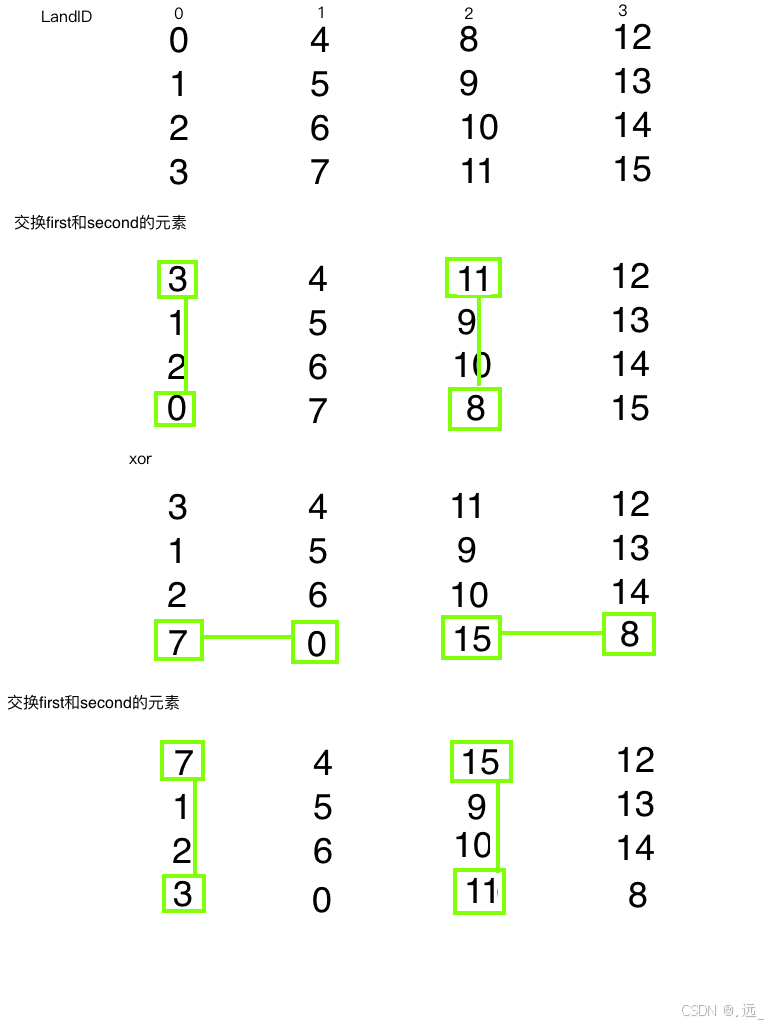
代码运行结果如下

这里很神奇的一点是与上一次我个人理解的运行结果相同,所以我很怀疑上面我个人的理解是不是有点问题。
使用线程束洗牌指令的并行规约
使用线程束洗牌指令完成归约,主要目标就是减少线程间数据传递的延迟,达到更快的效率:
我们主要考虑三个层面的归约:
- 线程束级归约
- 线程块级归约
- 网格级归约
一个线程块有5个线程束,每个执行自己的归约,每个线程束不适用共享内存,而是使用线程束洗牌指令,代码如下:
__inline__ __device__ int warpReduce(int localSum)
{
localSum += __shfl_xor(localSum, 16);
localSum += __shfl_xor(localSum, 8);
localSum += __shfl_xor(localSum, 4);
localSum += __shfl_xor(localSum, 2);
localSum += __shfl_xor(localSum, 1);
return localSum;
}
__global__ void reduceShfl(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
__shared__ int smem[DIM];
unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x;
//convert global data pointer to the
//1.
int mySum=g_idata[idx];
int laneIdx=threadIdx.x%warpSize;
int warpIdx=threadIdx.x/warpSize;
//2.
mySum=warpReduce(mySum);
//3.
if(laneIdx==0)
smem[warpIdx]=mySum;
__syncthreads();
//4.
mySum=(threadIdx.x<DIM)?smem[laneIdx]:0;
if(warpIdx==0)
mySum=warpReduce(mySum);
//5.
if(threadIdx.x==0)
g_odata[blockIdx.x]=mySum;
}代码解释:
- 从全局内存读取数据,计算线程束ID和当前线程的束内线程ID
- 计算当前线程束内的归约结果,使用的xor,这里需要动手计算下每个线程和这些2的幂次计算的结果因为每个线程束只有32个线程,所以二进制最高位就是16,那么xor 16 是计算0+16,1+17,2+18,这些位置的和,计算完成后前16位是结果,16到31是一样结果,重复了一边,同理xor 8是计算0+8,1+9,2+10,…,前8位结果有效,后面是复制前面的答案,最后就得到当前线程束的归约结果。
- 然后把线程束结果存储到共享内存中
- 然后继续2中的过程计算3中得到的数据,完整的重复
- 将最后结果存入全局内存
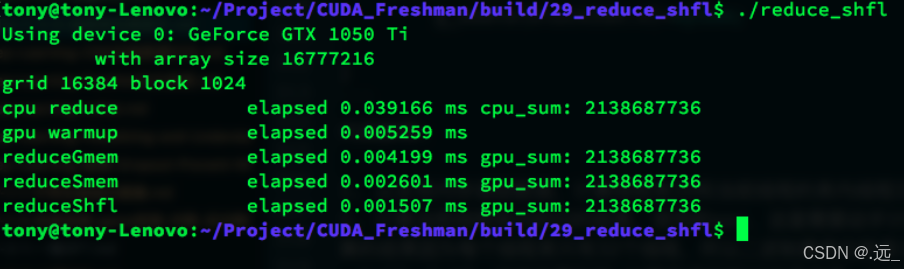
使用线程束洗牌指令进行的归约效率最高。主要原因是使用寄存器进行数据交换而不需要任何位置的内存介入。

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)