triton inference server的backend插件机制代码流程梳理、模型加载代码梳理
triton inference server代码流程梳理、模型加载代码梳理
目录
1.3 从TritonBackendManager和TritonBackend分析backend的机制
1.3.1 class TritonBackendManager
2 backend代码的细节、模型加载流程、上层调用流程、疑问、以及补充说明
2.1 class TritonBackendManager类的创建代码在哪里被调用的
2.2 class TritonBackend类的创建代码在哪里被调用的
2.5 模型实例初始化ModelInstanceInitFn的代码在哪里被调用的
2.6 一个重要、承上启下的函数--TritonModel::Create()
2.7 应该有个循环遍历所有的目录然后分析出来所有backend .so的代码吧,在哪里
2.8 看代码时无意看到了new triton::common::ThreadPool,这个线程池在哪里用了
3.1 class ModelRepositoryManager是做什么的
3.3.1 class ModelState 是做什么的--其实就是实际干活的类
3.4 class TritonModelInstance 是做什么的
3.4.1 class ModelInstanceState 是做什么的--其实就是实际干活的
1 阅读代码整体了解下backend机制
1.1 backend机制介绍
我在大体了解完了backend的机制后,把backend机制的通俗理解先写到这里来,具体代码细节在后面,
-
后端目录扫描
Triton Server 启动时,会扫描默认后端目录/opt/tritonserver/backends/下的子目录,每个子目录对应一个后端。通过目录名称和其中的配置文件确定后端信息。 -
读取后端配置
在每个后端目录下,Triton 读取并解析config.pbtxt配置文件,获取后端的元数据信息和运行参数,如支持的模型格式、执行策略等。 -
加载后端共享库
Triton 通过dlopen(Linux)或LoadLibrary(Windows)接口动态加载后端共享库文件(如libonnxruntime.so)。加载成功后,后端相关的代码与资源被映射到进程空间。 -
查找并绑定后端接口函数
后端共享库必须实现并暴露一组标准接口函数(API),例如:-
TRITONBACKEND_Initialize -
TRITONBACKEND_Finalize -
TRITONBACKEND_GetBackendAttribute -
TRITONBACKEND_ModelInitialize -
TRITONBACKEND_ModelFinalize -
TRITONBACKEND_ModelInstanceInitialize -
TRITONBACKEND_ModelInstanceFinalize -
TRITONBACKEND_ModelInstanceExecute
Triton 通过
dlsym或GetProcAddress等机制获取这些函数入口地址,并保存到后端管理结构中。 -
-
后端初始化
如果后端实现了TRITONBACKEND_Initialize函数,Triton 会调用它执行后端级的初始化操作,如分配资源、初始化第三方库环境等。
其中后端目录结构一般来说如下,这里以onnxruntime为例
/opt/tritonserver/backends/onnxruntime/ # Triton 默认后端目录之一,路径可定制,但默认通常在这里
├── config.pbtxt # ONNX Runtime 后端的配置文件,定义后端相关属性
├── libonnxruntime.so # ONNX Runtime 后端的动态库(共享库)
└── 其他依赖文件 # 后端可能依赖的其他库或资源文件<模型仓库路径>/ # 由启动 Triton 时命令行参数 --model-repository= 指定,用户自定义路径
├── resnet50/
│ ├── config.pbtxt # 模型配置文件,定义模型输入输出、实例数量、调度等信息
│ ├── 1/ # 模型版本目录(版本号为 1)
│ │ └── model.onnx # 该版本的模型文件(此处以 ONNX 格式为例)
│ └── 2/
│ └── model.onnx # 另一个版本的模型文件(版本号为 2)
└── bert/
├── config.pbtxt
├── 1/
│ └── model.onnx
└── ...
1.2 dlopen和dlsym动态库加载机制简介
在真正看代码之前,先普及一点小知识:
在 Linux 系统中,提供了一套用于动态加载共享库(.so 文件)的 API,这些函数允许程序在运行时加载动态库、获取库中符号(函数或变量)的地址,并在不需要时卸载动态库。Triton Inference Server 正是利用这套接口来动态加载各个 Backend 的共享库,实现灵活的插件式架构。
这套 API 主要包括以下几个函数:
#include <dlfcn.h>
// 以指定模式打开动态库文件,返回句柄
void* dlopen(const char* filename, int flag);
// 在动态库中查找指定符号(函数或变量)的地址
void* dlsym(void* handle, const char* symbol);
// 关闭动态库,释放资源
int dlclose(void* handle);
// 返回上一次 dlopen、dlsym 或 dlclose 操作的错误信息字符串
char* dlerror(void);
函数说明:
-
dlopen:打开一个动态库文件(如libonnxruntime.so),并返回一个句柄供后续操作使用。参数flag用于指定加载模式,如RTLD_LAZY(延迟解析符号)或RTLD_NOW(立即解析符号)等。 -
dlsym:利用dlopen返回的句柄,在动态库中查找指定符号的地址。该符号可以是函数,也可以是全局变量,灵活方便。 -
dlclose:关闭动态库,释放加载时占用的资源。调用后,句柄不再有效。 -
dlerror:返回最近一次调用dlopen、dlsym或dlclose出错时的错误信息字符串,便于调试。
另外,这里记住几个单词就能记住这两个接口的名字了,dl是Dynamic Linking,然后open不用说了,然后sym是symbol也就是符号指函数名字或者变量名字。
1.3 从TritonBackendManager和TritonBackend分析backend的机制
在triton中,backend机制的主要代码其实就是在ritonBackendManager和TritonBackend这两个类中,代码路径是core/src/backend_manager.h和core/src/backend_manager.cc。
1.3.1 class TritonBackendManager
先看一下头文件中的声明
//
// Manage communication with Triton backends and their lifecycle.
//
class TritonBackendManager {
public:
static Status Create(std::shared_ptr<TritonBackendManager>* manager);
Status CreateBackend(
const std::string& name, const std::string& dir,
const std::string& libpath,
const triton::common::BackendCmdlineConfig& backend_cmdline_config,
bool is_python_based_backend, std::shared_ptr<TritonBackend>* backend);
Status BackendState(
std::unique_ptr<
std::unordered_map<std::string, std::vector<std::string>>>*
backend_state);
private:
DISALLOW_COPY_AND_ASSIGN(TritonBackendManager);
TritonBackendManager() = default;
std::unordered_map<std::string, std::shared_ptr<TritonBackend>> backend_map_;
};然后从cpp文件中分别大体看下这三个函数的具体定义
//
// TritonBackendManager
//
static std::weak_ptr<TritonBackendManager> backend_manager_;
static std::mutex mu_;
Status
TritonBackendManager::Create(std::shared_ptr<TritonBackendManager>* manager)
{
std::lock_guard<std::mutex> lock(mu_);
// If there is already a manager then we just use it...
*manager = backend_manager_.lock();
if (*manager != nullptr) {
return Status::Success;
}
manager->reset(new TritonBackendManager());
backend_manager_ = *manager;
return Status::Success;
}
Status
TritonBackendManager::CreateBackend(
const std::string& name, const std::string& dir, const std::string& libpath,
const triton::common::BackendCmdlineConfig& backend_cmdline_config,
bool is_python_based_backend, std::shared_ptr<TritonBackend>* backend)
{
std::lock_guard<std::mutex> lock(mu_);
const auto python_based_backend_path = JoinPath({dir, kPythonFilename});
std::vector<std::string> paths = {libpath, python_based_backend_path};
for (const auto& path : paths) {
const auto& itr = backend_map_.find(path);
// If backend already exists, re-use it.
if (itr != backend_map_.end()) {
*backend = itr->second;
// Python based backends use the same shared library as python backend.
// If libpath to libtriton_python.so is already found, we need to check
// if backend names match. If not, we create a new python based backend.
if ((*backend)->Name() == name) {
return Status::Success;
}
}
}
RETURN_IF_ERROR(TritonBackend::Create(
name, dir, libpath, backend_cmdline_config, backend));
(*backend)->SetPythonBasedBackendFlag(is_python_based_backend);
if (is_python_based_backend) {
backend_map_.insert({python_based_backend_path, *backend});
} else {
backend_map_.insert({libpath, *backend});
}
return Status::Success;
}
Status
TritonBackendManager::BackendState(
std::unique_ptr<std::unordered_map<std::string, std::vector<std::string>>>*
backend_state)
{
std::lock_guard<std::mutex> lock(mu_);
std::unique_ptr<std::unordered_map<std::string, std::vector<std::string>>>
backend_state_map(
new std::unordered_map<std::string, std::vector<std::string>>);
std::vector<std::string> python_backend_config{};
bool has_python_backend = false;
for (const auto& backend_pair : backend_map_) {
auto& libpath = backend_pair.first;
auto backend = backend_pair.second;
if (backend->Name() == kPythonBackend) {
has_python_backend = true;
}
const char* backend_config;
size_t backend_config_size;
backend->BackendConfig().Serialize(&backend_config, &backend_config_size);
backend_state_map->insert(
{backend->Name(), std::vector<std::string>{libpath, backend_config}});
if (backend->IsPythonBackendBased() && python_backend_config.empty()) {
python_backend_config.emplace_back(backend->LibPath());
python_backend_config.emplace_back(std::string(backend_config));
}
}
if (!has_python_backend && !python_backend_config.empty()) {
backend_state_map->insert({kPythonBackend, python_backend_config});
}
*backend_state = std::move(backend_state_map);
return Status::Success;
}主要就是三个函数
- TritonBackendManager::CreateBackend:这个函数其实就是创建了一个TritonBackendManager实例,然后只不过里面加了个互斥锁,还有就是用了个静态弱指针,这个静态弱指针有点类似于单例模式::如果已经存在实例,则复用;否则新建并缓存。保证只有一个TritonBackendManager实例。
- TritonBackendManager::CreateBackend函数:先根据lib库的路径再backend_map_中查找,找到了那说明已经有了,没找到就TritonBackend::Create创建TritonBackend对象,然后insert进这个map中。
- TritonBackendManager::BackendState:用于收集当前所有已加载后端的状态信息。它遍历
backend_map_,提取每个后端的名称、动态库路径及序列化后的后端配置,并将这些信息存入一个 map 中返回。
1.3.2 class TritonBackend
然后也是先看一下头文件中的相关声明
//
// Proxy to a backend shared library.
//
class TritonBackend {
public:
struct Attribute {
Attribute()
: exec_policy_(TRITONBACKEND_EXECUTION_BLOCKING),
parallel_instance_loading_(false)
{
}
TRITONBACKEND_ExecutionPolicy exec_policy_;
std::vector<inference::ModelInstanceGroup> preferred_groups_;
// Whether the backend supports loading model instances in parallel
bool parallel_instance_loading_;
};
typedef TRITONSERVER_Error* (*TritonModelInitFn_t)(
TRITONBACKEND_Model* model);
typedef TRITONSERVER_Error* (*TritonModelFiniFn_t)(
TRITONBACKEND_Model* model);
typedef TRITONSERVER_Error* (*TritonModelInstanceInitFn_t)(
TRITONBACKEND_ModelInstance* instance);
typedef TRITONSERVER_Error* (*TritonModelInstanceFiniFn_t)(
TRITONBACKEND_ModelInstance* instance);
typedef TRITONSERVER_Error* (*TritonModelInstanceExecFn_t)(
TRITONBACKEND_ModelInstance* instance, TRITONBACKEND_Request** requests,
const uint32_t request_cnt);
static Status Create(
const std::string& name, const std::string& dir,
const std::string& libpath,
const triton::common::BackendCmdlineConfig& backend_cmdline_config,
std::shared_ptr<TritonBackend>* backend);
~TritonBackend();
const std::string& Name() const { return name_; }
const std::string& Directory() const { return dir_; }
const std::string& LibPath() const { return libpath_; }
const TritonServerMessage& BackendConfig() const { return backend_config_; }
const Attribute& BackendAttributes() const { return attributes_; }
TRITONBACKEND_ExecutionPolicy ExecutionPolicy() const
{
return attributes_.exec_policy_;
}
void SetExecutionPolicy(const TRITONBACKEND_ExecutionPolicy policy)
{
attributes_.exec_policy_ = policy;
}
void* State() { return state_; }
void SetState(void* state) { state_ = state; }
bool IsPythonBackendBased() { return is_python_based_backend_; }
void SetPythonBasedBackendFlag(bool is_python_based_backend)
{
is_python_based_backend_ = is_python_based_backend;
}
TritonModelInitFn_t ModelInitFn() const { return model_init_fn_; }
TritonModelFiniFn_t ModelFiniFn() const { return model_fini_fn_; }
TritonModelInstanceInitFn_t ModelInstanceInitFn() const
{
return inst_init_fn_;
}
TritonModelInstanceFiniFn_t ModelInstanceFiniFn() const
{
return inst_fini_fn_;
}
TritonModelInstanceExecFn_t ModelInstanceExecFn() const
{
return inst_exec_fn_;
}
private:
typedef TRITONSERVER_Error* (*TritonBackendInitFn_t)(
TRITONBACKEND_Backend* backend);
typedef TRITONSERVER_Error* (*TritonBackendFiniFn_t)(
TRITONBACKEND_Backend* backend);
typedef TRITONSERVER_Error* (*TritonBackendAttriFn_t)(
TRITONBACKEND_Backend* backend,
TRITONBACKEND_BackendAttribute* backend_attributes);
TritonBackend(
const std::string& name, const std::string& dir,
const std::string& libpath, const TritonServerMessage& backend_config);
void ClearHandles();
Status LoadBackendLibrary(const std::string& additional_dependency_dir_path);
Status UpdateAttributes();
// The name of the backend.
const std::string name_;
// Full path to the directory holding backend shared library and
// other artifacts.
const std::string dir_;
// Full path to the backend shared library.
const std::string libpath_;
bool is_python_based_backend_;
// Backend configuration as JSON
TritonServerMessage backend_config_;
// backend attributes
Attribute attributes_;
// dlopen / dlsym handles
void* dlhandle_;
TritonBackendInitFn_t backend_init_fn_;
TritonBackendFiniFn_t backend_fini_fn_;
TritonBackendAttriFn_t backend_attri_fn_;
TritonModelInitFn_t model_init_fn_;
TritonModelFiniFn_t model_fini_fn_;
TritonModelInstanceInitFn_t inst_init_fn_;
TritonModelInstanceFiniFn_t inst_fini_fn_;
TritonModelInstanceExecFn_t inst_exec_fn_;
// Opaque state associated with the backend.
void* state_;
};接着看一下cpp文件中的几个函数的定义,这里不全复制源文件了,太多了,重点只看这一个函数就行了
//
// TritonBackend
//
Status
TritonBackend::Create(
const std::string& name, const std::string& dir, const std::string& libpath,
const triton::common::BackendCmdlineConfig& backend_cmdline_config,
std::shared_ptr<TritonBackend>* backend)
{
// Create the JSON representation of the backend configuration.
triton::common::TritonJson::Value backend_config_json(
triton::common::TritonJson::ValueType::OBJECT);
if (!backend_cmdline_config.empty()) {
triton::common::TritonJson::Value cmdline_json(
backend_config_json, triton::common::TritonJson::ValueType::OBJECT);
for (const auto& pr : backend_cmdline_config) {
RETURN_IF_ERROR(cmdline_json.AddString(pr.first.c_str(), pr.second));
}
RETURN_IF_ERROR(
backend_config_json.Add("cmdline", std::move(cmdline_json)));
}
TritonServerMessage backend_config(backend_config_json);
auto local_backend = std::shared_ptr<TritonBackend>(
new TritonBackend(name, dir, libpath, backend_config));
auto it = find_if(
backend_cmdline_config.begin(), backend_cmdline_config.end(),
[](const std::pair<std::string, std::string>& config_pair) {
return config_pair.first == "additional-dependency-dirs";
});
std::string additional_dependency_dir_path;
if (it != backend_cmdline_config.end()) {
additional_dependency_dir_path = it->second;
}
// Load the library and initialize all the entrypoints
RETURN_IF_ERROR(
local_backend->LoadBackendLibrary(additional_dependency_dir_path));
// Backend initialization is optional... The TRITONBACKEND_Backend
// object is this TritonBackend object. We must set set shared
// library path to point to the backend directory in case the
// backend library attempts to load additional shared libraries.
if (local_backend->backend_init_fn_ != nullptr) {
std::unique_ptr<SharedLibrary> slib;
RETURN_IF_ERROR(SharedLibrary::Acquire(&slib));
void* directory_cookie = nullptr;
RETURN_IF_ERROR(
slib->AddLibraryDirectory(local_backend->dir_, &directory_cookie));
TRITONSERVER_Error* err = local_backend->backend_init_fn_(
reinterpret_cast<TRITONBACKEND_Backend*>(local_backend.get()));
RETURN_IF_ERROR(slib->RemoveLibraryDirectory(directory_cookie));
RETURN_IF_TRITONSERVER_ERROR(err);
}
local_backend->UpdateAttributes();
*backend = std::move(local_backend);
return Status::Success;
}
这个函数其实用到了工厂模式(从头文件这个函数的声明那里可以看到,前面有个static),这个函数的作用是创建一个 TritonBackend 实例,并完成后端共享库的加载与初始化,整体逻辑如下:
-
首先将命令行配置参数转为 JSON 结构,构造
TritonServerMessage类型的backend_config_。 -
接着用
new TritonBackend(...)创建一个TritonBackend对象并用shared_ptr管理。 -
如果配置项中包含
"additional-dependency-dirs",就提取该路径作为依赖库的额外查找目录。 -
调用
LoadBackendLibrary()加载对应的后端.so动态库。 -
如果动态库中定义了
backend_init_fn_(即实现了TRITONBACKEND_Initialize),就调用它完成后端初始化,这一步还会暂时将后端目录加入到共享库加载目录。 -
最后调用
UpdateAttributes()获取后端的调度策略等属性,并将TritonBackend实例返回给调用方。
1.3.3 加载库的具体代码
前面说过用dlopen去打开so库,在LoadBackendLibrary这个函数中 。
Status
TritonBackend::LoadBackendLibrary(
const std::string& additional_dependency_dir_path)
{
TritonBackendInitFn_t bifn;
TritonBackendFiniFn_t bffn;
TritonBackendAttriFn_t bafn;
TritonModelInitFn_t mifn;
TritonModelFiniFn_t mffn;
TritonModelInstanceInitFn_t iifn;
TritonModelInstanceFiniFn_t iffn;
TritonModelInstanceExecFn_t iefn;
{
std::unique_ptr<SharedLibrary> slib;
RETURN_IF_ERROR(SharedLibrary::Acquire(&slib));
if (!additional_dependency_dir_path.empty()) {
RETURN_IF_ERROR(
slib->SetAdditionalDependencyDirs(additional_dependency_dir_path));
}
RETURN_IF_ERROR(slib->OpenLibraryHandle(libpath_, &dlhandle_));
// Backend initialize and finalize functions, optional
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_Initialize", true /* optional */,
reinterpret_cast<void**>(&bifn)));
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_Finalize", true /* optional */,
reinterpret_cast<void**>(&bffn)));
// Backend attribute function, optional
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_GetBackendAttribute", true /* optional */,
reinterpret_cast<void**>(&bafn)));
// Model initialize and finalize functions, optional
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_ModelInitialize", true /* optional */,
reinterpret_cast<void**>(&mifn)));
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_ModelFinalize", true /* optional */,
reinterpret_cast<void**>(&mffn)));
// Model instance initialize and finalize functions, optional
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_ModelInstanceInitialize", true /* optional */,
reinterpret_cast<void**>(&iifn)));
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_ModelInstanceFinalize", true /* optional */,
reinterpret_cast<void**>(&iffn)));
// Model instance execute function, required
RETURN_IF_ERROR(slib->GetEntrypoint(
dlhandle_, "TRITONBACKEND_ModelInstanceExecute", false /* optional */,
reinterpret_cast<void**>(&iefn)));
}
backend_init_fn_ = bifn;
backend_fini_fn_ = bffn;
backend_attri_fn_ = bafn;
model_init_fn_ = mifn;
model_fini_fn_ = mffn;
inst_init_fn_ = iifn;
inst_fini_fn_ = iffn;
inst_exec_fn_ = iefn;
return Status::Success;
}这里面其实使用SharedLibrary这个类做的,而这个类其实就是对dlopen和dlsym的封装,
比如,SharedLibrary::OpenLibraryHandle就是对dlopen的封装
Status
SharedLibrary::OpenLibraryHandle(const std::string& path, void** handle)
{
LOG_VERBOSE(1) << "OpenLibraryHandle: " << path;
#ifdef TRITON_ENABLE_GPU
// This call is to prevent a deadlock issue with dlopening backend shared
// libraries and calling CUDA APIs in other threads. Since CUDA API also
// dlopens some libraries and dlopen has an internal lock, it can create a
// deadlock. Intentionally ignore the CUDA_ERROR (if any) for containers
// running on a CPU.
int device_count;
cudaGetDeviceCount(&device_count);
#endif
#ifdef _WIN32
//win32的代码先删了,不放笔记里面了,占地方
#else
*handle = dlopen(path.c_str(), RTLD_NOW | RTLD_LOCAL);
if (*handle == nullptr) {
return Status(
Status::Code::NOT_FOUND,
"unable to load shared library: " + std::string(dlerror()));
}
#endif
return Status::Success;
}还有SharedLibrary::GetEntrypoint就是对dlsym的封装
Status
SharedLibrary::GetEntrypoint(
void* handle, const std::string& name, const bool optional, void** befn)
{
*befn = nullptr;
#ifdef _WIN32
......
#else
dlerror();
void* fn = dlsym(handle, name.c_str());
const char* dlsym_error = dlerror();
if (dlsym_error != nullptr) {
if (optional) {
return Status::Success;
}
std::string errstr(dlsym_error); // need copy as dlclose overwrites
return Status(
Status::Code::NOT_FOUND, "unable to find required entrypoint '" + name +
"' in shared library: " + errstr);
}
if (fn == nullptr) {
if (optional) {
return Status::Success;
}
return Status(
Status::Code::NOT_FOUND,
"unable to find required entrypoint '" + name + "' in shared library");
}
#endif
*befn = fn;
return Status::Success;
}1.3.4 8个接口对外的名字是什么
每个动态库中的接口名字是下面的
-
TRITONBACKEND_Initialize -
TRITONBACKEND_Finalize -
TRITONBACKEND_GetBackendAttribute -
TRITONBACKEND_ModelInitialize -
TRITONBACKEND_ModelFinalize -
TRITONBACKEND_ModelInstanceInitialize -
TRITONBACKEND_ModelInstanceFinalize -
TRITONBACKEND_ModelInstanceExecute
但是,从前面分析可以看到,通过dlopen和dlsym这两个函数从so库中获取了8个api,然后是
Status
TritonBackend::LoadBackendLibrary(
const std::string& additional_dependency_dir_path)
{
......
backend_init_fn_ = bifn;
backend_fini_fn_ = bffn;
backend_attri_fn_ = bafn;
model_init_fn_ = mifn;
model_fini_fn_ = mffn;
inst_init_fn_ = iifn;
inst_fini_fn_ = iffn;
inst_exec_fn_ = iefn;
return Status::Success;
}而在TritonBackend类里面又有这几行
TritonModelInitFn_t ModelInitFn() const { return model_init_fn_; }
TritonModelFiniFn_t ModelFiniFn() const { return model_fini_fn_; }
TritonModelInstanceInitFn_t ModelInstanceInitFn() const
{
return inst_init_fn_;
}
TritonModelInstanceFiniFn_t ModelInstanceFiniFn() const
{
return inst_fini_fn_;
}
TritonModelInstanceExecFn_t ModelInstanceExecFn() const
{
return inst_exec_fn_;
}所以,其实最终对外放开的接口或者说函数名字是。
- ModelInitFn
- ModelFiniFn
- ModelInstanceInitFn
- ModelInstanceFiniFn
- ModelInstanceExecFn
另外,前面不是说了有8个api,这五个是公开的,另外三个是private私有的。
2 backend代码的细节、模型加载流程、上层调用流程、疑问、以及补充说明
2.1 class TritonBackendManager类的创建代码在哪里被调用的
我那会想看一下这个class TritonBackendManager是在哪里被创建的,如果我用vscode调试,一边调试一边看函数调用速度最快,但是现在先不去配置调试环境了,这个代码我大体找下吧,
先倒着往前找
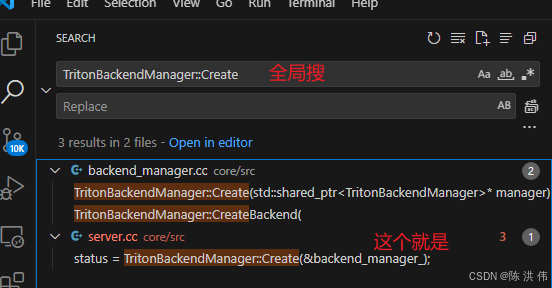
然后在InferenceServer::Init()里面。然后我觉得这个类被创建的时候大概率是用指针,那么搜->init()看到
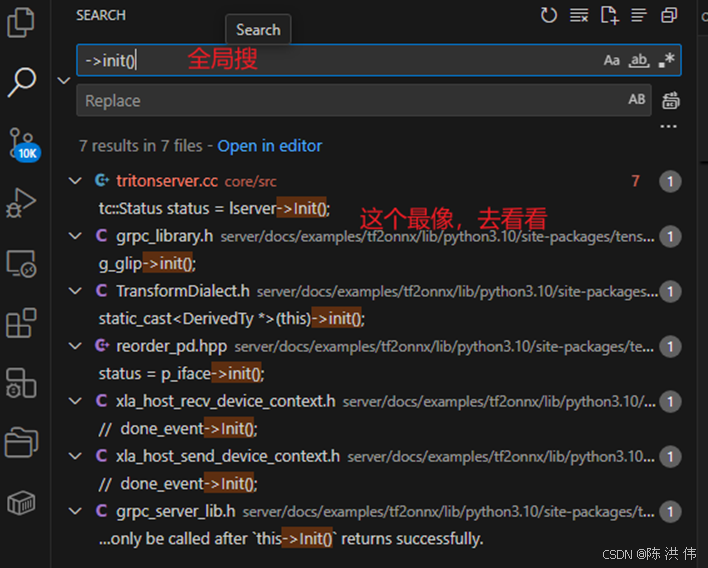
是在这里
TRITONSERVER_ServerNew(
TRITONSERVER_Server** server, TRITONSERVER_ServerOptions* options)
{
tc::InferenceServer* lserver = new tc::InferenceServer();
TritonServerOptions* loptions =
..........
// Initialize server
tc::Status status = lserver->Init();然后继续
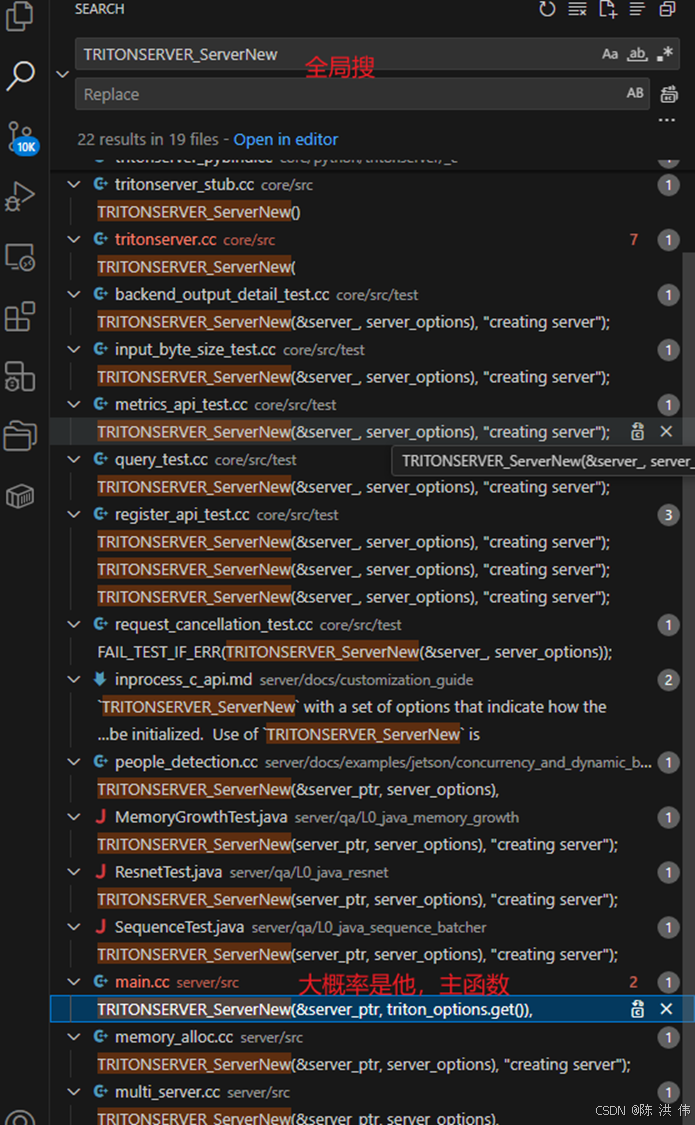
那么流程就是
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
├── new tc::InferenceServer()
└── lserver->Init()
└── InferenceServer::Init()
└── TritonBackendManager::Create(&backend_manager_)
└── new TritonBackendManager() #在这里被创建的,这个函数这就结束了。
2.2 class TritonBackend类的创建代码在哪里被调用的
TritonBackend::Create是在TritonBackendManager::CreateBackend(里面被调用的,
搜索->CreateBackend发现它是在TritonModel::Create(里面被调用的。
搜索TritonModel::Create发现它是在ModelLifeCycle::CreateModel(里面被调用的
搜索ModelLifeCycle::CreateModel( 发现 它是在 ModelLifeCycle::AsyncLoad(这里面被调用的
ModelLifeCycle::AsyncLoad( 是在 ModelRepositoryManager::LoadModelByDependency(里面被调用的。
LoadModelByDependency(是在ModelRepositoryManager::LoadUnloadModels( 或者PollAndUpdateInternal里面被调用的。
而ModelRepositoryManager::LoadUnloadModels( 或者PollAndUpdateInternal其实都是在ModelRepositoryManager::Create(函数里面被调用的。
InferenceServer::Init()中调用ModelRepositoryManager::Create(函数
然后往上就是inferenceserver::init,
再往上就是Iserver->init
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
├── new tc::InferenceServer()
└── lserver->Init()
└── InferenceServer::Init()
所以汇总就是
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
└── new tc::InferenceServer()
└── lserver->Init()
└── InferenceServer::Init()
└── ModelRepositoryManager::Create(...)
├── ModelRepositoryManager::LoadUnloadModels(...) ←───┐
└── ModelRepositoryManager::PollAndUpdateInternal(...) ←───┘
└── ModelRepositoryManager::LoadModelByDependency(...)
└── ModelLifeCycle::AsyncLoad(...)
└── ModelLifeCycle::CreateModel(...)
└── TritonModel::Create(...)#这里是通过线程池中load_pool_->Enqueue实现异步加载的。
└── TritonBackendManager::CreateBackend(...)
└── TritonBackend::Create(...)
├── new TritonBackend(name, dir, libpath, backend_config)
├── local_backend->LoadBackendLibrary(...) # 用 dlopen 和 dlsym 加载动态库,获取库中 8 个接口
└── local_backend->backend_init_fn_(...) # 调用 TRITONBACKEND_BackendInit(如果非空)
2.3 模型加载过程
2.3.1 初始化时的批量加载
在 ModelRepositoryManager::Create() 函数中,会调用 ModelRepositoryManager::LoadUnloadModels() 或者 PollAndUpdateInternal() 来批量加载模型,这个过程发生在 Triton 启动初始化阶段,会扫描指定的模型仓库路径,将所有模型加载进服务器。
这个模型加载的代码流程其实就是下面的这个
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
└── new tc::InferenceServer()
└── lserver->Init()
└── InferenceServer::Init()
└── ModelRepositoryManager::Create(...)
├── ModelRepositoryManager::LoadUnloadModels(...) ←───┐
└── ModelRepositoryManager::PollAndUpdateInternal(...) ←───┘
└── ModelRepositoryManager::LoadModelByDependency(...)
└── ModelLifeCycle::AsyncLoad(...)
└── ModelLifeCycle::CreateModel(...)
└── TritonModel::Create(...)#这里是通过线程池中load_pool_->Enqueue实现异步加载的。
└── TritonBackendManager::CreateBackend(...)
└── TritonBackend::Create(...)
├── new TritonBackend(name, dir, libpath, backend_config)
├── local_backend->LoadBackendLibrary(...) # 用 dlopen 和 dlsym 加载动态库,获取库中 8 个接口
└── local_backend->backend_init_fn_(...) # 调用 TRITONBACKEND_BackendInit(如果非空)
2.3.2 运行时的单次加载
其实,除了ModelRepositoryManager::Create会调用到LoadUnloadModels以外,在LoadUnloadModel(是model,没有s)里面也调用到LoadUnloadModels加载模型,这其实是在InferenceServer::LoadModel(和InferenceServer::UnloadModel(中单次加载模型的时候用的,这两个都会调用到LoadUnloadModel进一步调用到LoadUnloadModels从而加载模型。
riton 运行后,如果用户通过 HTTP/gRPC 接口手动加载或卸载模型,最终会调用:
InferenceServer::LoadModel()
InferenceServer::UnloadModel()
└── ModelRepositoryManager::LoadUnloadModel()
└── ModelRepositoryManager::LoadUnloadModels()
└── LoadModelByDependency()
这里的 LoadUnloadModel() 是提供给外部接口用于动态控制单个模型加载/卸载的入口,内部依然会调用 LoadUnloadModels() 以复用相同的依赖解析和异步加载流程。
2.4 模型初始化代码ModelInitFn在哪里被调用的
当加载完so之后,那么模型加载在哪里呀,那就继续看下代码吧,要想找这个代码不能直接去找TRITONBACKEND_ModelInitialize函数,这个函数只是so库里面的名字,但是其实dlopen和dlsym处理完之后函数名字变成了
- ModelInitFn
- ModelFiniFn
- ModelInstanceInitFn
- ModelInstanceFiniFn
- ModelInstanceExecFn
所以直接需要找ModelInitFn函数,再加上这里肯定也是用类的指针去调用的,那么就搜->ModelInitFn(就肯定能找到被调用的地方。其实就在TritonModel::Create函数中,至于TritonModel::Create再往上层的调用流程前面分析过,不用重复了。
std::shared_ptr<TritonBackend> backend;
RETURN_IF_ERROR(server->BackendManager()->CreateBackend(
backend_name, backend_libdir, backend_libpath, config,
is_python_based_backend, &backend));
......
if (backend->ModelInitFn() != nullptr) {
......
TRITONSERVER_Error* err = backend->ModelInitFn()(
reinterpret_cast<TRITONBACKEND_Model*>(raw_local_model));
......
RETURN_IF_TRITONSERVER_ERROR(err);
}加上前面的函数调用,最终的调用关系如下
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
// 创建 Triton 服务器实例的入口,对外 C 接口
└── new tc::InferenceServer()
// 实例化 InferenceServer 类,分配内部结构
└── lserver->Init()
// 初始化 server,包括 backend、repository 等模块
└── InferenceServer::Init()
└── ModelRepositoryManager::Create(...)
├── ModelRepositoryManager::LoadUnloadModels(...) ←───┐
└── ModelRepositoryManager::PollAndUpdateInternal(...) ←───┘
└── ModelRepositoryManager::LoadModelByDependency(...)
└── ModelLifeCycle::AsyncLoad(...)
└── ModelLifeCycle::CreateModel(...)
└── TritonModel::Create(...) // 通过线程池 load_pool_->Enqueue 异步加载
├── TritonBackendManager::CreateBackend(...)
│ └── TritonBackend::Create(...)
│ ├── new TritonBackend(name, dir, libpath, backend_config)
│ ├── local_backend->LoadBackendLibrary(...)
│ │ └── 用 dlopen 和 dlsym 加载动态库,获取库中 8 个接口函数指针(例如 ModelInitFn)
│ └── local_backend->backend_init_fn_(...)
│ └── 调用 TRITONBACKEND_BackendInit(如果非空)
│
├── backend->ModelInitFn()(raw_local_model) // 调用 TRITONBACKEND_ModelInitialize(...)
│ └── TRITONBACKEND_ModelInitialize(...)
│ ├── TRITONBACKEND_ModelName(...) / TRITONBACKEND_ModelVersion(...)
│ ├── DeviceMemoryTracker::TrackThreadMemoryUsage(...)
│ ├── ModelState::Create(model, &model_state)
│ │ └── 加载模型级 config.pbtxt、tokenizer、共享资源等
│ ├── TRITONBACKEND_ModelSetState(model, model_state)
│ └── DeviceMemoryTracker::Untrack / Serialize / ReportMemoryUsage(...)2.5 模型实例初始化ModelInstanceInitFn的代码在哪里被调用的
当加载完so之后,那么模型加载在哪里呀,那就继续看下代码吧,要想找这个代码不能直接去找TRITONBACKEND_ModelInitialize函数,这个函数只是so库里面的名字,但是其实dlopen和dlsym处理完之后函数名字变成了
- ModelInitFn
- ModelFiniFn
- ModelInstanceInitFn
- ModelInstanceFiniFn
- ModelInstanceExecFn
所以直接需要找ModelInstanceInitFn函数,这个其实也是从TritonModel::Create函数中能一层层的找到,在TritonModel::Create函数中有下面一行。
RETURN_IF_ERROR(local_model->PrepareInstances(model_config, &added_instances, &removed_instances));然后在TritonModel::PrepareInstances(中能看到
RETURN_IF_ERROR(TritonModelInstance::CreateInstance(
this, instance_name, signature, is.kind_, is.device_id_,
profile_names, passive, is.policy_name_,
*is.rate_limiter_config_, secondary_devices, &new_instance));然后CreateInstance中能看到
auto err = ConstructAndInitializeInstance(
model, name, signature, kind, device_id, profile_names, passive,
host_policy_name, *host_policy, rate_limiter_config, secondary_devices,
triton_model_instance);然后ConstructAndInitializeInstance函数中可以看到
Status
TritonModelInstance::ConstructAndInitializeInstance(
TritonModel* model, const std::string& name, const Signature& signature,
const TRITONSERVER_InstanceGroupKind kind, const int32_t device_id,
const std::vector<std::string>& profile_names, const bool passive,
const std::string& host_policy_name,
const triton::common::HostPolicyCmdlineConfig& host_policy,
const inference::ModelRateLimiter& rate_limiter_config,
const std::vector<SecondaryDevice>& secondary_devices,
std::shared_ptr<TritonModelInstance>* triton_model_instance)
{
......
std::unique_ptr<TritonModelInstance> local_instance(new TritonModelInstance(
model, name, signature, kind, device_id, profile_names, passive,
host_policy, host_policy_message, secondary_devices));
TRITONBACKEND_ModelInstance* triton_instance =
reinterpret_cast<TRITONBACKEND_ModelInstance*>(local_instance.get());
......
TRITONSERVER_Error* err =
model->Backend()->ModelInstanceInitFn()(triton_instance);
......
}这不就找到了吗。
所以这个的树状调用关系流程图如下
TritonModel::Create()
└── TritonModel::PrepareInstances()
└── TritonModelInstance::CreateInstance()
└── TritonModelInstance::ConstructAndInitializeInstance()
├── new TritonModelInstance(...) // 实例化 ModelInstance
├── reinterpret_cast<TRITONBACKEND_ModelInstance*>(...)
└── model->Backend()->ModelInstanceInitFn()(triton_instance)
└── 实际调用 .so 中的 TRITONBACKEND_ModelInstanceInitialize()
如果再把前面理的上层就是TritonModel::Create()往上的调用关系加载前面,那么得到下面的额流程图
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
// 创建 Triton 服务器实例的入口,对外 C 接口
└── new tc::InferenceServer()
// 实例化 InferenceServer 类,分配内部结构
└── lserver->Init()
// 初始化 server,包括 backend、repository 等模块
└── InferenceServer::Init()
└── ModelRepositoryManager::Create(...)
├── ModelRepositoryManager::LoadUnloadModels(...) ←───┐
└── ModelRepositoryManager::PollAndUpdateInternal(...) ←───┘
└── ModelRepositoryManager::LoadModelByDependency(...)
└── ModelLifeCycle::AsyncLoad(...)
└── ModelLifeCycle::CreateModel(...)
└── TritonModel::Create(...) # 通过线程池 load_pool_->Enqueue 异步加载
├── TritonBackendManager::CreateBackend(...)
│ └── TritonBackend::Create(...)
│ ├── new TritonBackend(name, dir, libpath, backend_config)
│ ├── local_backend->LoadBackendLibrary(...)
│ │ └── 用 dlopen 和 dlsym 加载动态库,获取库中 8 个接口函数指针(例如 ModelInitFn)
│ └── local_backend->backend_init_fn_(...)
│ └── 调用 TRITONBACKEND_BackendInit(如果非空)
│
└── TritonModel::PrepareInstances()
└── TritonModelInstance::CreateInstance()
└── TritonModelInstance::ConstructAndInitializeInstance()
├── new TritonModelInstance(...)
│ └── 初始化成员变量、注册指标,不涉及模型加载
├── reinterpret_cast<TRITONBACKEND_ModelInstance*>(...)
└── model->Backend()->ModelInstanceInitFn()(triton_instance)
└── 实际调用 .so 中的 TRITONBACKEND_ModelInstanceInitialize(...)
├── TRITONBACKEND_ModelInstanceName(...)
├── TRITONBACKEND_ModelInstanceDeviceId(...)
├── TRITONBACKEND_ModelInstanceModel(...)
├── TRITONBACKEND_ModelState(...)
│ └── 得到 ModelState*
├── DeviceMemoryTracker::TrackThreadMemoryUsage(...)
├── ModelInstanceState::Create(model_state, instance, &instance_state)
│ └── new ModelInstanceState(...)
│ └── model_state->LoadModel(...)
│ └── 真正加载 OrtSession、default_allocator、模型路径等资源
├── TRITONBACKEND_ModelInstanceSetState(...)
│ └── 绑定 instance_state 到 instance 中
└── DeviceMemoryTracker::Untrack / Serialize / ReportMemoryUsage(...)
2.6 一个重要、承上启下的函数--TritonModel::Create()
在上面阅读代码的时候,我发现了一个比较重要的函数 TritonModel::Create,因为这个函数中包含了下面四个比较重要的方面
- server->BackendManager()->CreateBackend(
- std::unique_ptr<TritonModel> local_model(new TritonModel(...));
- backend->ModelInitFn()(
- RETURN_IF_ERROR(local_model->PrepareInstances(model_config, &added_instances, &removed_instances));
2.7 应该有个循环遍历所有的目录然后分析出来所有backend .so的代码吧,在哪里
这个问题是在刚开始看代码的时候想到的一个问题,当时想着记下来然后后面弄明白,但是当我看完代码后这个问题自然有答案了:
确实有这样的代码,就是在ModelRepositoryManager::Create函数里面,前面分析“class TritonBackend类的创建代码在哪里被调用的”那一小节的时候已经分析过加载模型的流程了,这里不重复了。
2.8 看代码时无意看到了new triton::common::ThreadPool,这个线程池在哪里用了
ModelLifeCycle(InferenceServer* server, const ModelLifeCycleOptions& options)
: server_(server), options_(options)
{
load_pool_.reset(new triton::common::ThreadPool(
std::max(1u, options_.model_load_thread_count)));
}这个线程池源码就不复制了,就是用生产者消费者模式设计的,里面无非还是那一套用条件变量和互斥锁进行控制,线程池基本都这一套东西,我重点是想看看这个线程池在哪里用它了。
这个问题是在刚开始看代码的时候想到的一个问题,当时想着记下来然后后面弄明白,但是当我看完代码后这个问题自然有答案了:
就是在异步加载模型的时候用到了,具体代码就不复制了,在前面整理的代码调用流程里面都有。
3 完整的backend机制以及模型加载的代码流程梳理
这个问题本来是我看代码的过程中觉得每次看的一小块不够系统,想着等我看懂后整理个完整的,但是当我看完发现,其实在前面的过程中我已经逐渐把完整的流程给整理出来了,如下:
main.cc
└── TRITONSERVER_ServerNew(&server_ptr, triton_options.get())
// 创建 Triton 服务器实例的入口,对外 C 接口
└── new tc::InferenceServer()
// 实例化 InferenceServer 类,分配内部结构
└── lserver->Init()
// 初始化 server,包括 backend、repository 等模块
└── InferenceServer::Init()
└── ModelRepositoryManager::Create(...)
├── ModelRepositoryManager::LoadUnloadModels(...) ←───┐
└── ModelRepositoryManager::PollAndUpdateInternal(...) ←───┘
└── ModelRepositoryManager::LoadModelByDependency(...)
└── ModelLifeCycle::AsyncLoad(...)
└── ModelLifeCycle::CreateModel(...)
└── TritonModel::Create(...) // 通过线程池 load_pool_->Enqueue 异步加载
├── TritonBackendManager::CreateBackend(...)
│ └── TritonBackend::Create(...)
│ ├── new TritonBackend(name, dir, libpath, backend_config)
│ ├── local_backend->LoadBackendLibrary(...)
│ │ └── 用 dlopen 和 dlsym 加载动态库,获取动态库中 8 个接口函数指针(例如 ModelInitFn)
│ └── local_backend->backend_init_fn_(...)
│ └── 调用 TRITONBACKEND_BackendInit(如果非空)
│
├── std::unique_ptr<TritonModel> local_model(new TritonModel(...))
│ └── TritonModel::TritonModel(...) // 构造函数
│ ├── 赋值成员变量(模型路径、版本、配置、backend 指针等)
│ ├── 初始化同步机制、标志位等
│ └── 不做耗时资源加载,纯成员初始化
│
├── backend->ModelInitFn()(raw_local_model) // 调用 TRITONBACKEND_ModelInitialize(...)
│ └── TRITONBACKEND_ModelInitialize(...)
│ ├── TRITONBACKEND_ModelName(...) / TRITONBACKEND_ModelVersion(...)
│ ├── DeviceMemoryTracker::TrackThreadMemoryUsage(...)
│ ├── ModelState::Create(model, &model_state)
│ │ └── 加载模型级 config.pbtxt、tokenizer、共享资源等
│ ├── TRITONBACKEND_ModelSetState(model, model_state)
│ └── DeviceMemoryTracker::Untrack / Serialize / ReportMemoryUsage(...)
│
└── TritonModel::PrepareInstances()
└── TritonModelInstance::CreateInstance()
└── TritonModelInstance::ConstructAndInitializeInstance()
├── new TritonModelInstance(...)
│ └── 初始化成员变量、注册指标,不涉及模型加载
├── reinterpret_cast<TRITONBACKEND_ModelInstance*>(...)
└── model->Backend()->ModelInstanceInitFn()(triton_instance)
└── 实际调用 .so 中的 TRITONBACKEND_ModelInstanceInitialize(...)
├── TRITONBACKEND_ModelInstanceName(...)
├── TRITONBACKEND_ModelInstanceDeviceId(...)
├── TRITONBACKEND_ModelInstanceModel(...)
├── TRITONBACKEND_ModelState(...)
│ └── 得到 ModelState*
├── DeviceMemoryTracker::TrackThreadMemoryUsage(...)
├── ModelInstanceState::Create(model_state, instance, &instance_state)
│ └── new ModelInstanceState(...)
│ └── model_state->LoadModel(...)
│ └── 真正加载 OrtSession、default_allocator、模型路径等资源
├── TRITONBACKEND_ModelInstanceSetState(...)
│ └── 绑定 instance_state 到 instance 中
└── DeviceMemoryTracker::Untrack / Serialize / ReportMemoryUsage(...)
3 六个比较重要的类
在前面看代码时候,从上到下的流程中,其实中间出现了 好几个类,下面看一下这几个类分别是干什么的。
3.1 class ModelRepositoryManager是做什么的
它的作用就像一个 “模型仓库管理员”,主要职责是:ModelRepositoryManager 负责扫描模型仓库目录,解析模型配置(config.pbtxt),识别模型版本,并触发模型加载流程。
它不会自己加载模型、创建推理实例,而是:只“发现模型 + 解析配置 + 告知生命周期管理器(ModelLifeCycle)去加载”。
| 职责 | 说明 |
|---|---|
| 模型仓库扫描 | 递归扫描模型目录结构,找出所有合法模型名与版本号目录(通常是形如 /model_repo/model_name/1/ 的结构) |
| 配置文件解析 | 加载并解析每个模型的 config.pbtxt 文件,生成 ModelConfig 结构体 |
| 版本识别 | 确定每个模型可用的版本(默认是所有整数目录名,如 1/、2/) |
| 动态更新支持 | 支持模型的动态加载、卸载、修改配置(比如 model control mode 为 POLL 或 EXPLICIT) |
| 触发模型加载 | 将识别到的模型交给 ModelLifeCycle 执行异步加载 |
| 管理多个模型仓库 | 支持多个 model repository 路径(多个目录合并管理) |
3.2 class ModelLifeCycle是做什么的
ModelLifeCycle 是整个 Triton 模型管理的“调度控制中心”,它负责
-
模型加载(Load)和卸载(Unload)
-
模型版本管理
-
管理模型当前的状态(加载中、可用、失败、卸载中等)
-
管理模型实例的创建与销毁
-
提供线程池并发加载多个模型
3.3 class TritonModel是做什么的
class TritonModel是一个具体模型的对象(一个版本),是 Triton 后端插件机制与模型推理生命周期的关键桥梁。TritonModel 是某个已加载模型的“抽象体 + 管理者 + 资源宿主”,Triton 在加载每个模型时,都会创建一个 TritonModel 实例。
- 这个模型的所有配置、路径、所处版本、所属 backend、后端状态、执行策略、实例组等
- 管理该模型的所有推理实例(
TritonModelInstance) - 负责绑定后端提供的推理函数,调用
TRITONBACKEND_ModelInit等生命周期函数 - 支撑整个推理生命周期,包括模型加载、初始化、配置更新、实例管理、资源回收等
TritonModel 的典型作用:
| 功能分类 | 具体职责 |
|---|---|
| 基础信息管理 | 包括模型名、版本号、config、路径(LocalizedModelPath())、是否自动完成 config 等 |
| 绑定后端 backend | 保存和管理本模型所使用的 backend(如 PythonBackend、TensorRTBackend) |
| 生命周期管理 | 调用后端的 ModelInit / ModelFini,维护模型状态(state_) |
| 模型实例管理 | 管理并组织所有 TritonModelInstance,包括设备分布、前后台实例、更新切换等 |
| 批处理相关接口 | 提供 batch_init_fn_、batch_fini_fn_、ModelBatchInclFn() 供 backend 注册调用 |
| 执行策略管理 | 提供 GetExecutionPolicy() 配置每个模型实例的执行逻辑(如线程绑定、优先级等) |
| 内存统计功能 | 提供 AccumulatedInstanceMemoryUsage() 汇总所有实例的显存/内存使用情况 |
3.3.1 class ModelState 是做什么的--其实就是实际干活的类
ModelState 是与 TritonModel 紧密关联的状态管理类,主要负责维护和管理模型后端(Backend)在运行时的内部状态。可以把它理解为 TritonModel 在后端层面的“具体实现”或“后台管家”,承担模型生命周期中更细粒度的状态和资源管理工作。
ModelState 的核心职责包括:
| 功能分类 | 具体职责 |
|---|---|
| 后端资源管理 | 管理后端为模型分配的各种资源,如内存、显存、模型上下文(Context)等 |
| 状态维护 | 跟踪模型加载、初始化、卸载等阶段的状态,保证模型在推理过程中的一致性和稳定性 |
| 生命周期协助 | 支持调用后端的生命周期接口,如 TRITONBACKEND_ModelInitialize 和 TRITONBACKEND_ModelFinalize,完成模型后端的初始化和清理 |
| 性能统计与监控 | 统计模型在推理过程中的内存使用、调用次数等指标,辅助调优和资源调配 |
| 线程安全与同步 | 处理多线程环境下模型状态的同步,保证并发推理时模型状态数据的安全访问 |
ModelState 本质上是模型后端状态的容器和管理者,它与 TritonModel 的区别在于:
-
TritonModel更多是面向 Triton Server 级别的模型“外壳”,负责管理配置、路径、版本、实例等整体逻辑 -
ModelState则是具体后端实现层面,专注于模型后端资源和运行时状态的细节维护
通常,一个 TritonModel 对象会对应一个唯一的 ModelState,通过 TRITONBACKEND_ModelSetState 绑定在一起。后续后端的推理调用、资源分配、状态查询等操作,基本都由 ModelState 来承担。
3.4 class TritonModelInstance 是做什么的
TritonModelInstance 是实际执行推理的最小调度单元,对应一个 model_instance 配置项,拥有自己的线程上下文、device(CPU/GPU)绑定、batch 策略等。
| 功能 | 说明 |
|---|---|
| 执行推理 | 它会持有后端 backend 提供的真正推理句柄,比如 ORT 的 Session、TensorRT 的 ExecutionContext |
| 绑定资源 | 每个 TritonModelInstance 会绑定设备(device_id)、线程模型(BLOCKING, NON_BLOCKING)等 |
| 调度任务 | Triton 的调度器会将请求投递给 TritonModelInstance 去处理 |
| 支持并发 | 一个模型有多个 instance,就能并发执行多个推理请求(由后端线程池调度) |
-
一个模型(如
resnet50) 的某个版本(比如 v1)会生成一个TritonModel; -
每个
TritonModel会根据config.pbtxt中的instance_group生成一个或多个TritonModelInstance; -
每个
TritonModelInstance是最终 执行推理工作的实体。
instance_group [
{
count: 4
kind: KIND_GPU
gpus: [ 0 ]
}
]
上面这个配置,表示模型有 4 个 instance,会生成 4 个 TritonModelInstance,部署在 GPU0 上。
3.4.1 class ModelInstanceState 是做什么的--其实就是实际干活的
ModelInstanceState 是 TritonModelInstance 对应的后端状态管理类,是推理实例的“执行者状态”载体。
它承载了该推理实例在推理生命周期内的具体状态、资源分配以及运行时上下文,是真正驱动该实例执行推理工作的核心对象。
| 功能 | 说明 |
|---|---|
| 状态维护 | 维护推理实例运行时的内部状态信息,如设备资源、执行上下文、模型绑定等 |
| 资源管理 | 管理推理实例占用的显存、内存、计算资源,负责初始化和清理工作 |
| 生命周期操作 | 对应后端的 ModelInstanceInitialize / ModelInstanceFinalize 等生命周期回调,执行初始化与销毁 |
| 线程绑定与调度 | 支持线程上下文绑定、执行优先级等调度相关设置,配合 Triton 调度器合理分配推理请求 |
| 并发支持 | 作为推理工作单元,多个 ModelInstanceState 可并发运行,支持高吞吐推理 |
简而言之,ModelInstanceState 是 TritonModelInstance 的“幕后推手”,真正掌控了单个推理实例的执行状态和资源细节,与 ModelState 类似,但它聚焦于实例级的运行时管理。
3.5 六个类之间的层次关系
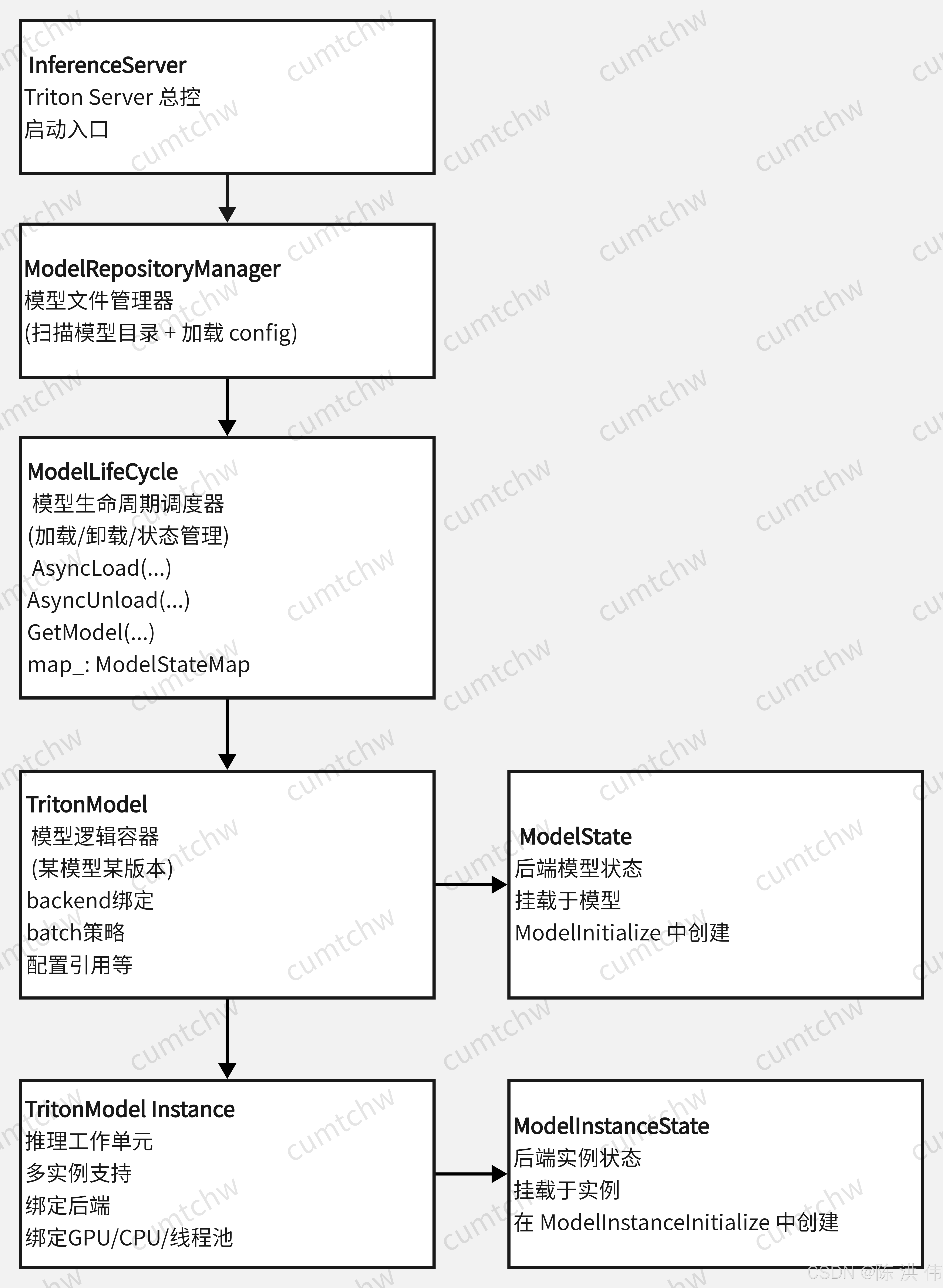
| 组件类名 | 类比角色 |
|---|---|
| ModelRepositoryManager | 模型文件管理员,负责模型文件扫描、版本识别、配置加载等 |
| ModelLifeCycle | 模型生命周期调度控制台,负责模型的真正加载/卸载/更新 |
| TritonModel / ModelState |
模型实例的“壳子”,包含配置、路径、backend等绑定逻辑;; ModelState为对应的模型后端状态管理,挂载于TritonModel下,负责模型生命周期的内部状态维护 |
| TritonModelInstance / ModelInstanceState |
推理工作单元,每个 instance 可以并发执行;; ModelInstanceState为对应推理实例的状态,挂载于TritonModelInstance,管理实例级资源与状态 |
对于这几个类的关系,先整体上有这么个理解吧,等以后真正开发修改triton 相关代码的时候,会理解的更加深入。
参考文献:
https://github.com/triton-inference-server/server
https://github.com/triton-inference-server/backend
https://github.com/triton-inference-server/backend/tree/main#backends
tritonserver学习之五:backend实现机制_triton backend-CSDN博客
tritonserver学习之三:tritonserver运行流程_trition-server 使用教程-CSDN博客
Triton Server 快速入门_tritonserver-CSDN博客
深度学习部署神器-triton inference server第一篇 - Oldpan的个人博客
tritonserver学习之六:自定义c++、python custom backend实践_triton c++-CSDN博客

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)