【CUDA编程基础】第二章 CUDA中的线程组织
【CUDA编程基础】第二章CUDA中的线程组织
第零章 资料
⭐CUDA所有版本官网文档:CUDA Toolkit Archive | NVIDIA Developer
书中源码:GitHub - brucefan1983/CUDA-Programming
第二章 CUDA中的线程组织
主机对CUDA设备的调用是通过核函数(kernel function)来实现的。CUDA中的核函数与C++中的函数是类似的,但它必须被限定词(qualifier)__global__修饰。还有核函数的返回类型必须是空类型,即void。
每个线程在核函数中都有一个唯一的身份标识。在核函数内部,程序执行配置参数grid_size和block_size保存在两个内建变量(build-in variable)中:
- gridDim.x:该变量的数值等于执行配置中变量grid_size中x的值。
- blockDim.x:该变量的数值等于执行配置中变量block_size中x的值。
类似的,在核函数中预定义了以下标识线程的内建变量:
- blockIdx.x:该变量指定一个线程在一个网格中的线程块指标,其取值范围从0到gridDim.x - 1。
- threadIdx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围从0到blockDim.x - 1。
一个GPU往往有几千个计算核心,而总的线程数必须至少等于计算核心数时才有可能充分利用GPU中的全部计算资源。总的线程数大于计算核心数时才能更充分地利用GPU中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
`hello.cu`
// 在使用nvcc编译时,将自动包含必要的cuda头文件,如cuda.h、cuda_runtime.h等
// #include <cuda_runtime.h>
#include <stdio.h>
// 编译命令:nvcc hello.cu -o hello
// 编译过程:c++ => Parallel Thread eXecution(PTX)=> cubin(二进制)
__global__ void hello_form_gpu()
{
// const int thread_id = gridDim.y * blockIdx.x + threadIdx.x;
// 网格在网络块中的id
const int bid = blockIdx.x;
const int bid_mult = blockIdx.z * gridDim.y * gridDim.x + blockIdx.y * gridDim.x + blockIdx.x;
// 线程在线程块中的id
const int tid = threadIdx.x;
const int tid_mult = threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
if (bid == 0 && tid == 0)
{
// 核函数中使用printf()函数时也需要包含头文件<stdio.h>(也可以写成<cstdio>)。核函数中不支持C++的iostream。
printf("gridDim.x: %d,gridDim.y: %d, gridDim.z:%d.\n", gridDim.x, gridDim.y, gridDim.z);
printf("blockDim.x: %d,blockDim.y: %d, blockDim.z:%d.\n", blockDim.x, blockDim.y, blockDim.z);
}
printf("Hello world from the GPU! block id: %d,bid_mult %d,thread id: %d, tid_mult:%d.\n",
bid, bid_mult, tid, tid_mult);
// 线程在全局三个方向上的id
// const int nx = blockDim.x * blockIdx.x + threadIdx.x;
// const int ny = blockDim.y * blockIdx.y + threadIdx.y;
// const int nz = blockDim.z * blockIdx.z + threadIdx.z;
printf("nx id: %d,ny %d,nz id: %d.\n", nx, ny, nz);
}
int main(int argc, char **argv)
{
// 指定GPU执行核函数
const int dev = 0;
cudaSetDevice(dev);
/*
grid size x、y和z最大值(由GPU设备决定)分别为2^(31)-1、65535和65535。
dim3是CUDA(Compute Unified Device Architecture)中的一个数据类型,
主要用于定义多维的网格(grid)和块(block)的尺寸,以进行 GPU 并行计算。
*/
const dim3 grid_size(2, 2);
// block size x,y,z最大值为1024,1024,64,且x*y*z <=1024
const dim3 block_size(3, 2);
printf("Hello world from the CPU!1\n");
/*
核函数调用形式。主机在调用一个核函数时,必须指明需要在设备中指派多少个线程。
三括号中的数是用来指明核函数中线程数目以及排列情况的。
核函数中的线程常组织为若干线程块(thread block):三括号中第一个数字可以看作线程块的个数,第二个数字可看作每个线程块中的线程数。
一个核函数的全部线程块构成一个网络(grid),而线程块的个数就记为网格大小(grid size)。
每个线程块中含有同样数目的线程,该数目称为线程块大小(block size)。
所以,核函数中总的线程数就等于网格大小乘以线程块大小,而三括号中的两个数字分别就是网格大小和线程块大小,
即<<<网格大小,线程块大小>>>。
*/
hello_form_gpu<<<grid_size, block_size>>>();
printf("Hello world from the CPU!2\n");
/*
去掉这句话后,核函数无法正常输出信息。这是因为调用输出函数时,
输出流是先存放在缓冲区的,而缓冲区不会自动刷新。只有程序遇到某种同步操作时缓冲区才会刷新。
函数cudaDeviceSynchronize的作用是同步主机与设备,所以能够促使缓冲区刷新。
*/
cudaDeviceSynchronize();
return 0;
}CUDA的编译驱动(compiler drive)nvcc会先将全部代码进行分离为主机代码和设备代码。主机代码完整地支持C++语法,但设备代码只部分地支持C++。nvcc先将设备代码编译为PTX(Parallel Thread eXecution)伪汇编代码,再将PTX代码编译为二进制的cubin目标代码。在编译代码为PTX代码时,需要用选项-arch=compute_XY指定虚拟架构能力,用以确定代码中能够使用的CUDA功能。在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力,用以确定可执行文件能够使用的GPU。真是架构的计算能力必须大于等于虚拟架构的计算能力。即可使用“-arch=compute_75 -code=sm_89”,但不可使用“-arch=compute_89 -code=sm_75”。
可使用多组计算能力,使编译出来的可执行文件在不同GPU中执行,格式为:“-gencode arch=compute_XY, code=sm_ZW”。
nvcc有一种即时编译(just-in-time compilation)的机制。可以在运行执行文件时从保留的PTX代码中临时编译出一个cubin目标代码。要在执行文件中保留这样的PTX代码,必须用”-gencode arch=compute_XY,code=compute_XY“。此种编译方式不一定能充分利用计算能力对应架构的硬件功能。
使用”-arch=sm_XY“等价于”-gencode arch=compute_XY,code=sm_XY -gencode arch=compute_XY,code=compute_XY“。
nvcc编译器驱动官方文档:NVIDIA CUDA Compiler Driver。
计算力:1080Ti 6.1,2080ti&T4 7.5,4070&L4 8.9
https://developer.nvidia.com/cuda-gpus
https://blog.csdn.net/wohenibdxt/article/details/124537949
Table 20:Feature Support per Compute Capability
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#features-and-technical-specifications-feature-support-per-compute-capability
Table 21:Technical Specifications per Compute Capability:
2080ti上运行 nvcc test.cu -arch=compute_35 -code=sm_35 -o test 时:
报nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
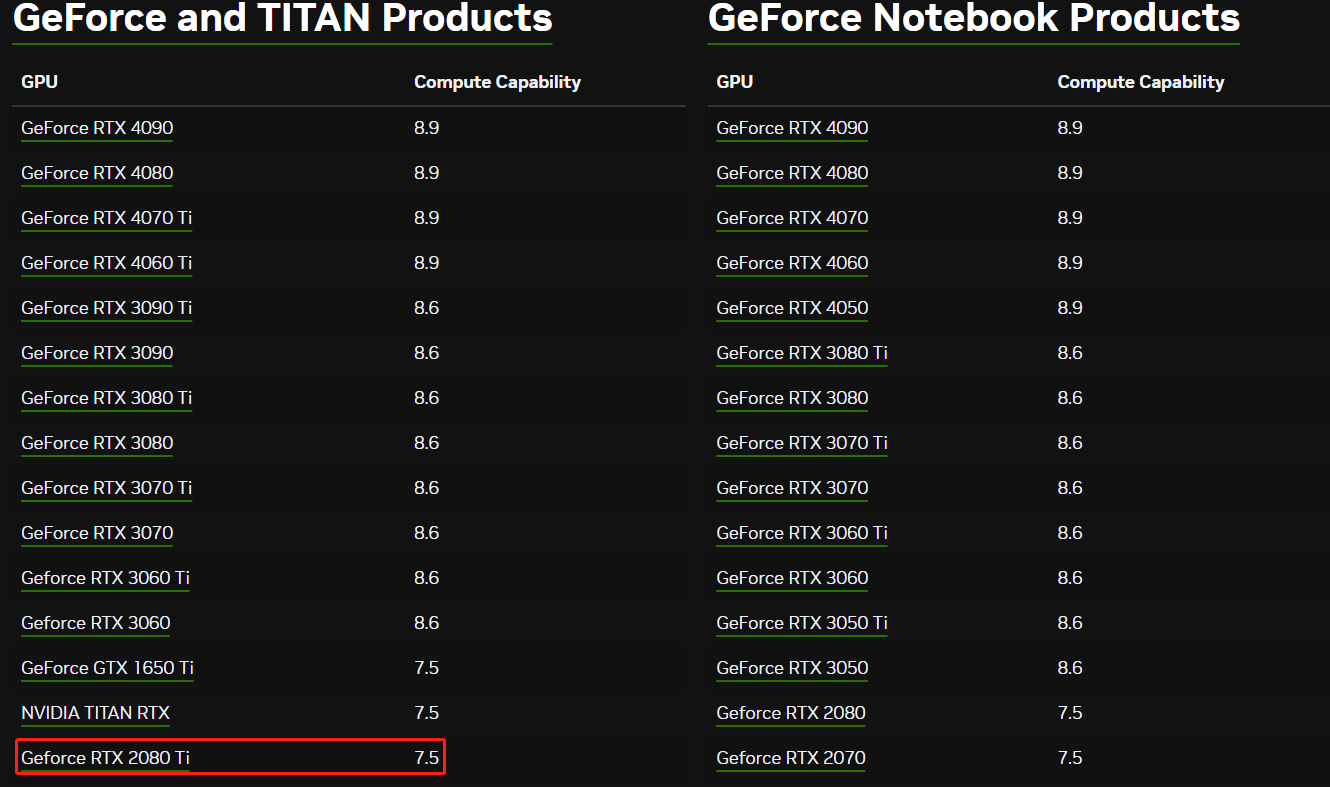
j计算能力查询链接:CUDA GPUs - Compute Capability | NVIDIA Developer
点击后会展开列表:
查看对应gpu Compute Capability
其他:MAhaitao999_CUDA书籍_pdf 对应的 CUDA编程书本目录

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)