CUDA入门
初学CUDA编程,一些概述
CUDA编程入门
文章目录
CUDA C 编程权威指南 电子书链接: CUDA C
提取码:n58h
CUDA编程入门
1.什么是GPU
1.1 GPU架构
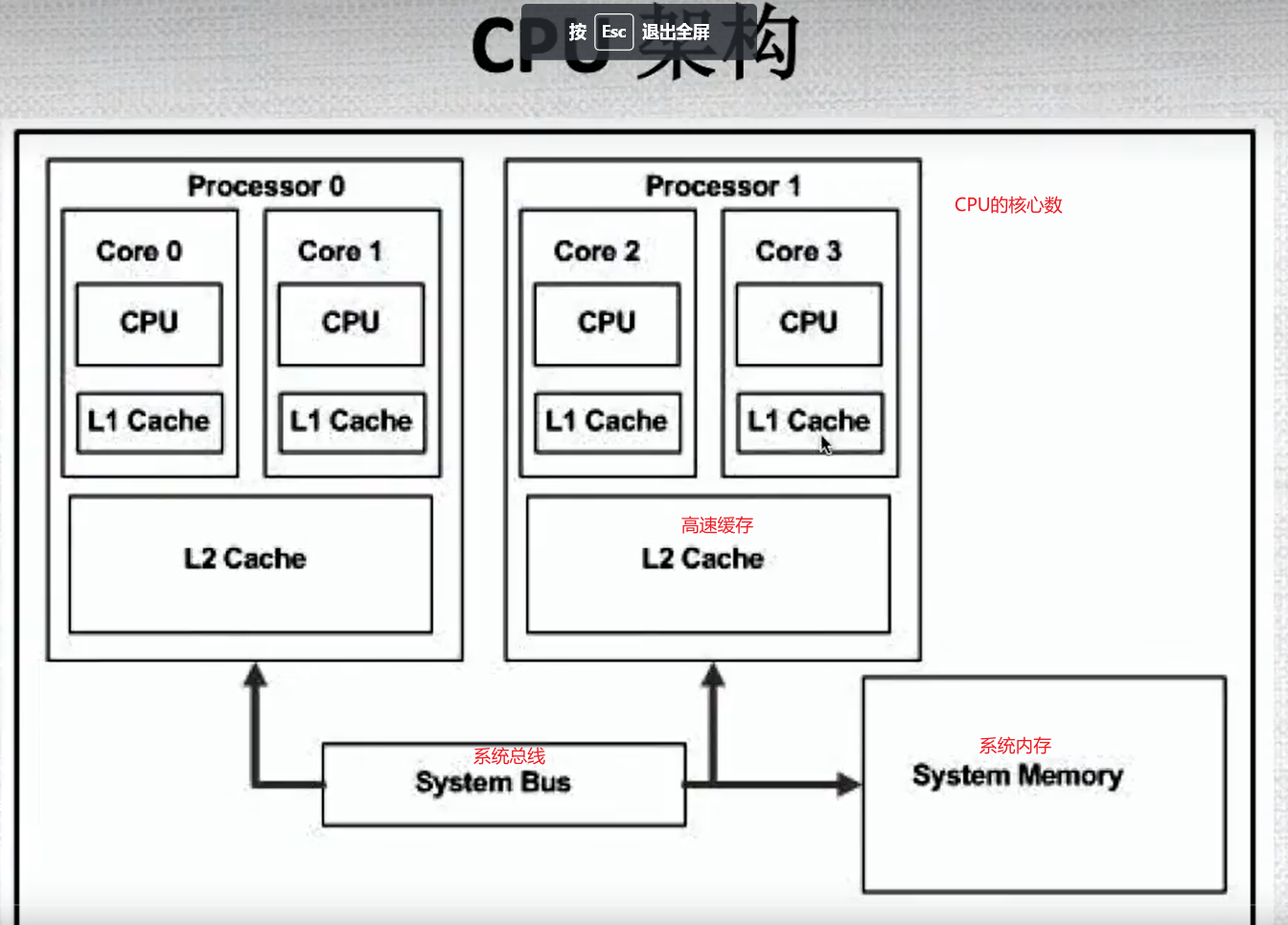
1.2 GPU架构
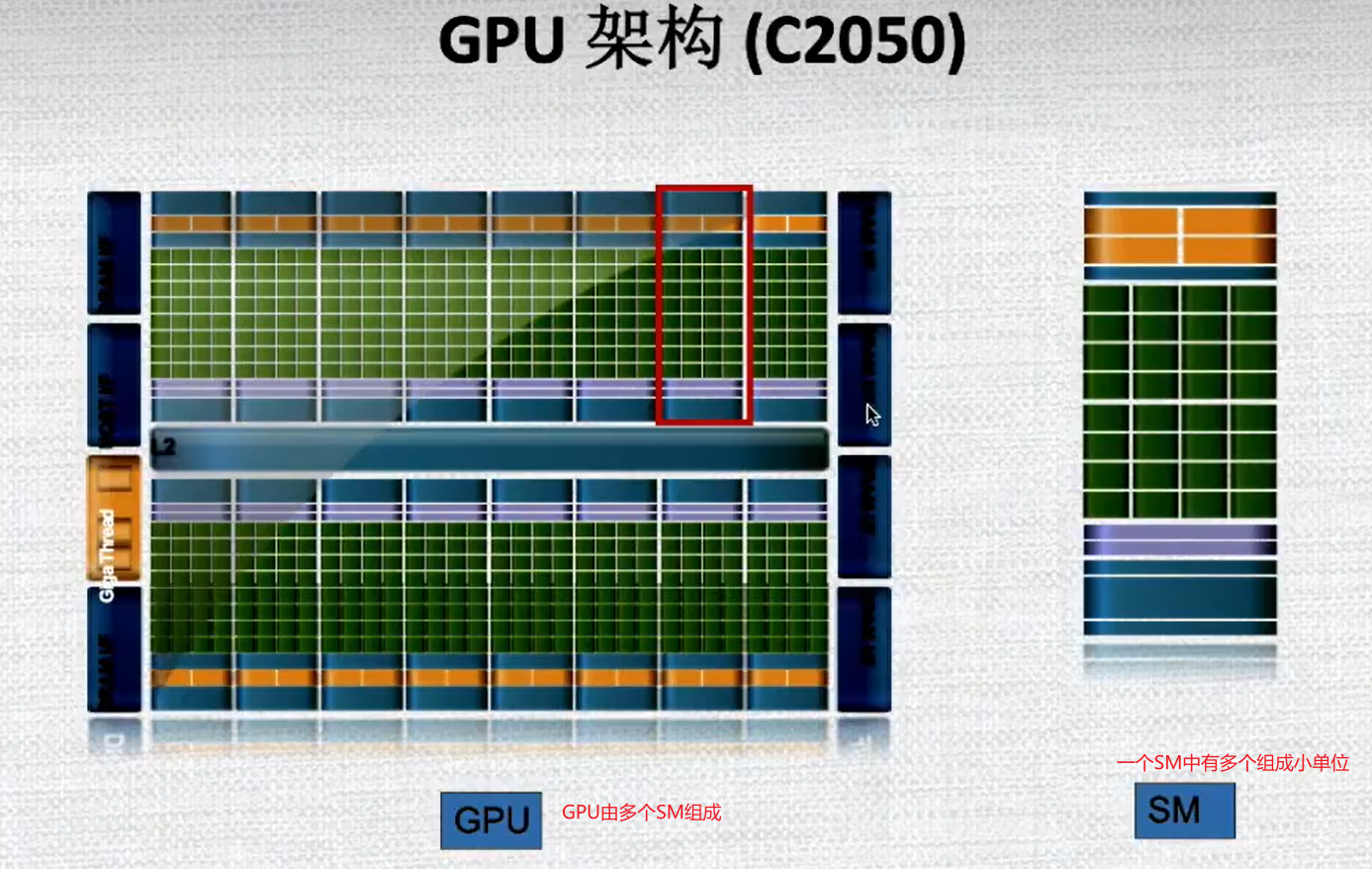
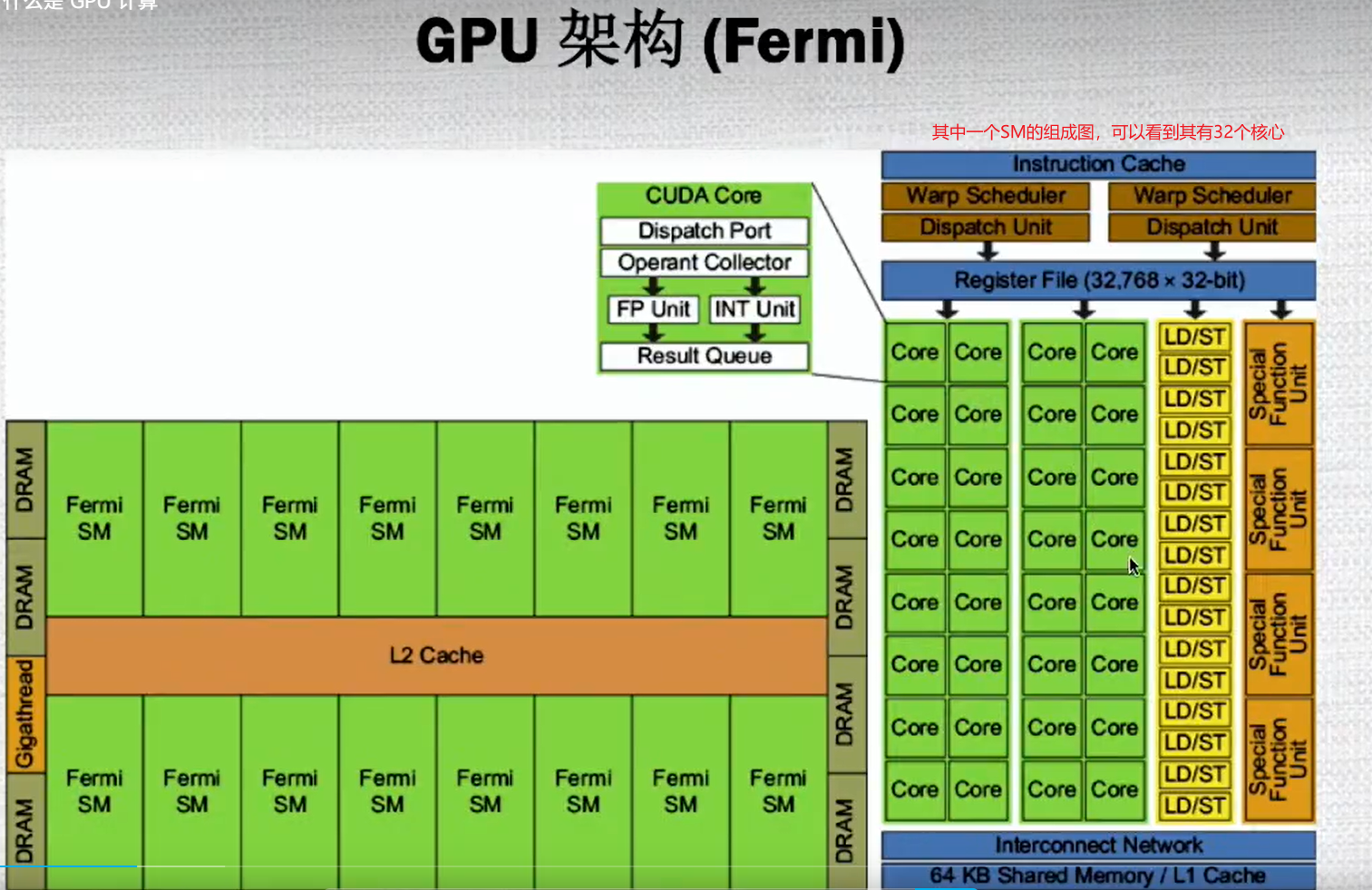
1.3 什么是GPU计算
GPU一般作为一个运算的平台,一般时候需要与CPU进行合作,CPU在控制整个的架构和逻辑,GPU作为一个协同计算的模块,可以加速运行。

1.4 为什么使用GPU计算

1.5 CPU和GPU的分工协作

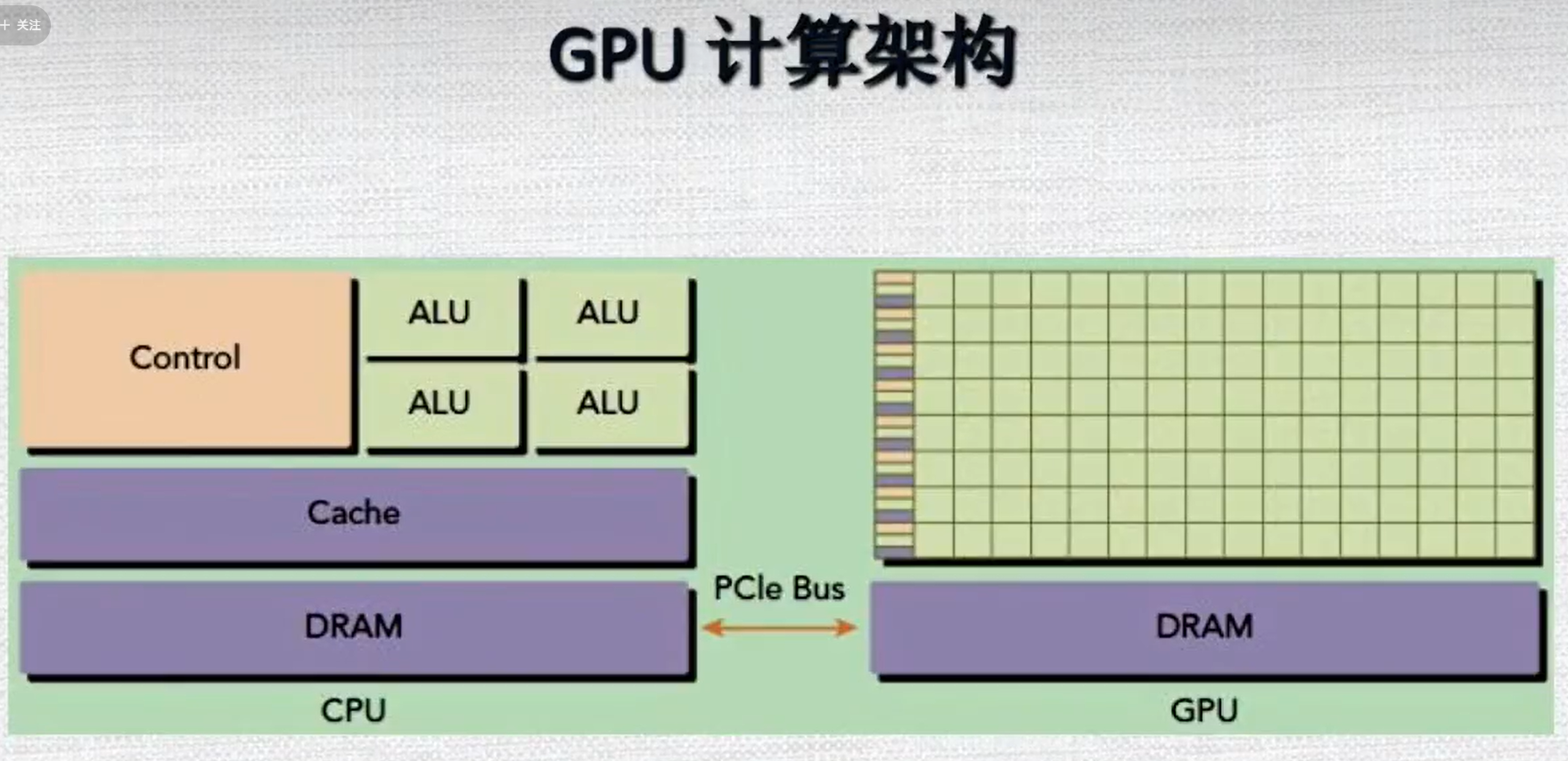
1.6 GPU 计算架构
1.7 程序架构
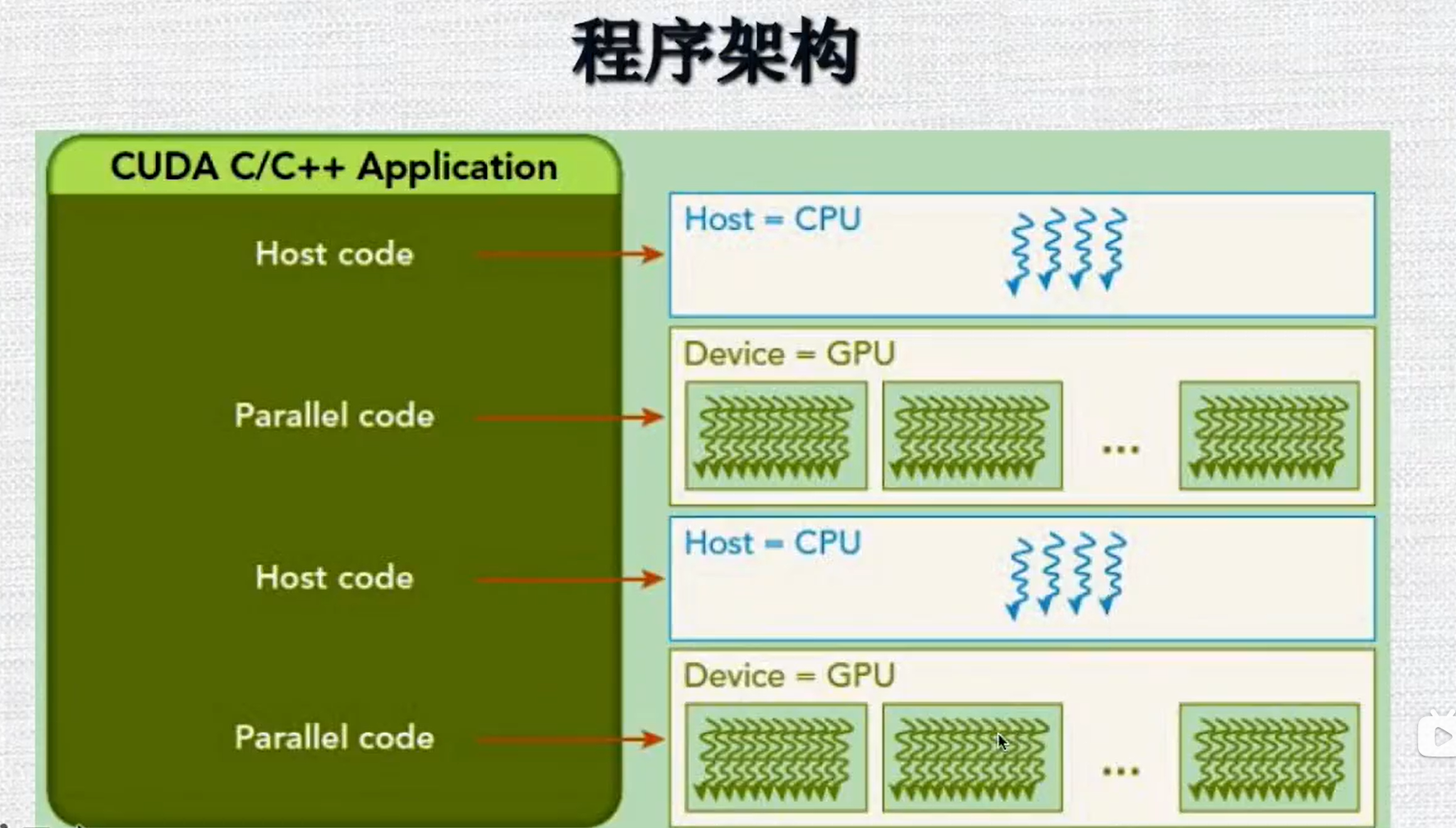
一个CUDA程序的运行,其实是CPU和GPU协作的结果:
CPU做一些初始化/逻辑控制的工作=>某个模块的计算两特别大适合并行计算时,将计算任务放在GPU上运行=>CPU对于GPU运算的结果会进行重新的加工=>处理完成之后又接着使用GPU做运算。
1.8 语言选择和编译器



2. GPU硬件架构
2.1 GT200 例子
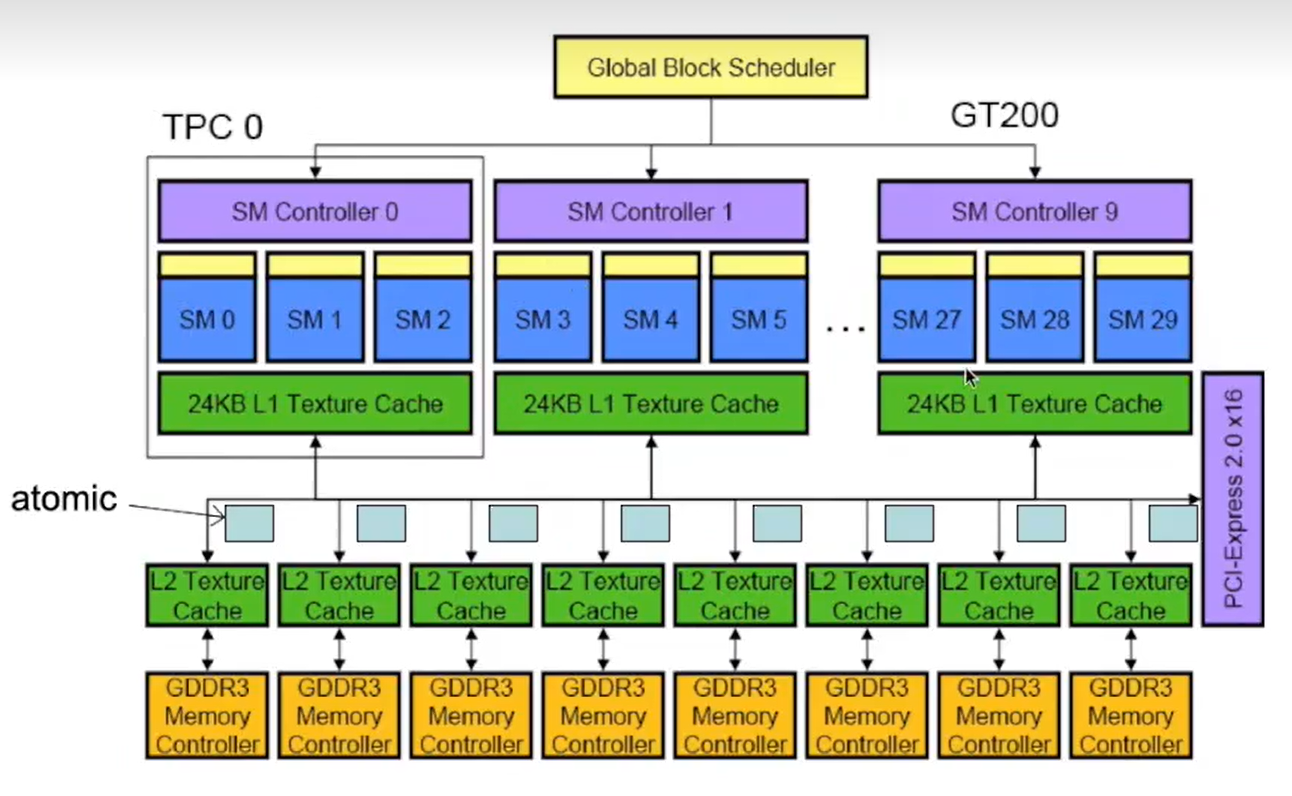
专业术语:SPA(streaming Processor Array) 所有的流处理器成为一个流处理器阵列
TPC/GPC(Texture(Graphics) Processor Cluster):将多个流多处理器分成一个小组
SM(Streaming Mutiprocessir 32SP):设计程序的块,有自己的内存单元,作业调度单元
SP(CUDA Core):流多处理器含有32个或者更多的SP流处理器

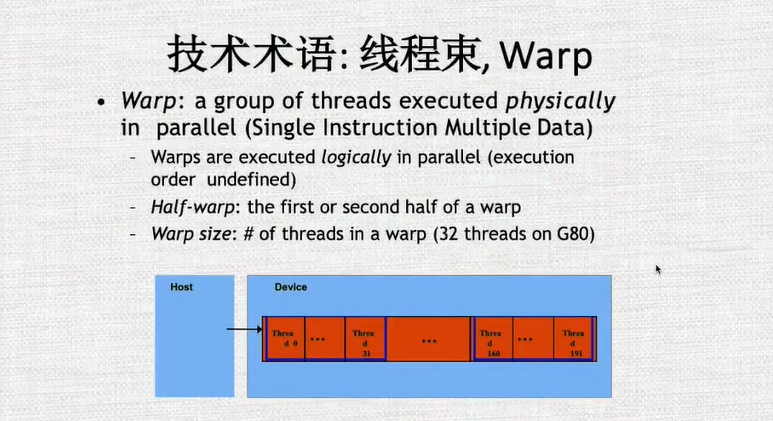
每个块中含有的线程数不能太多,1-512,现在最多能做到2048,并且每32个线程共享一个Wrap Scheduler
2.2 硬件架构
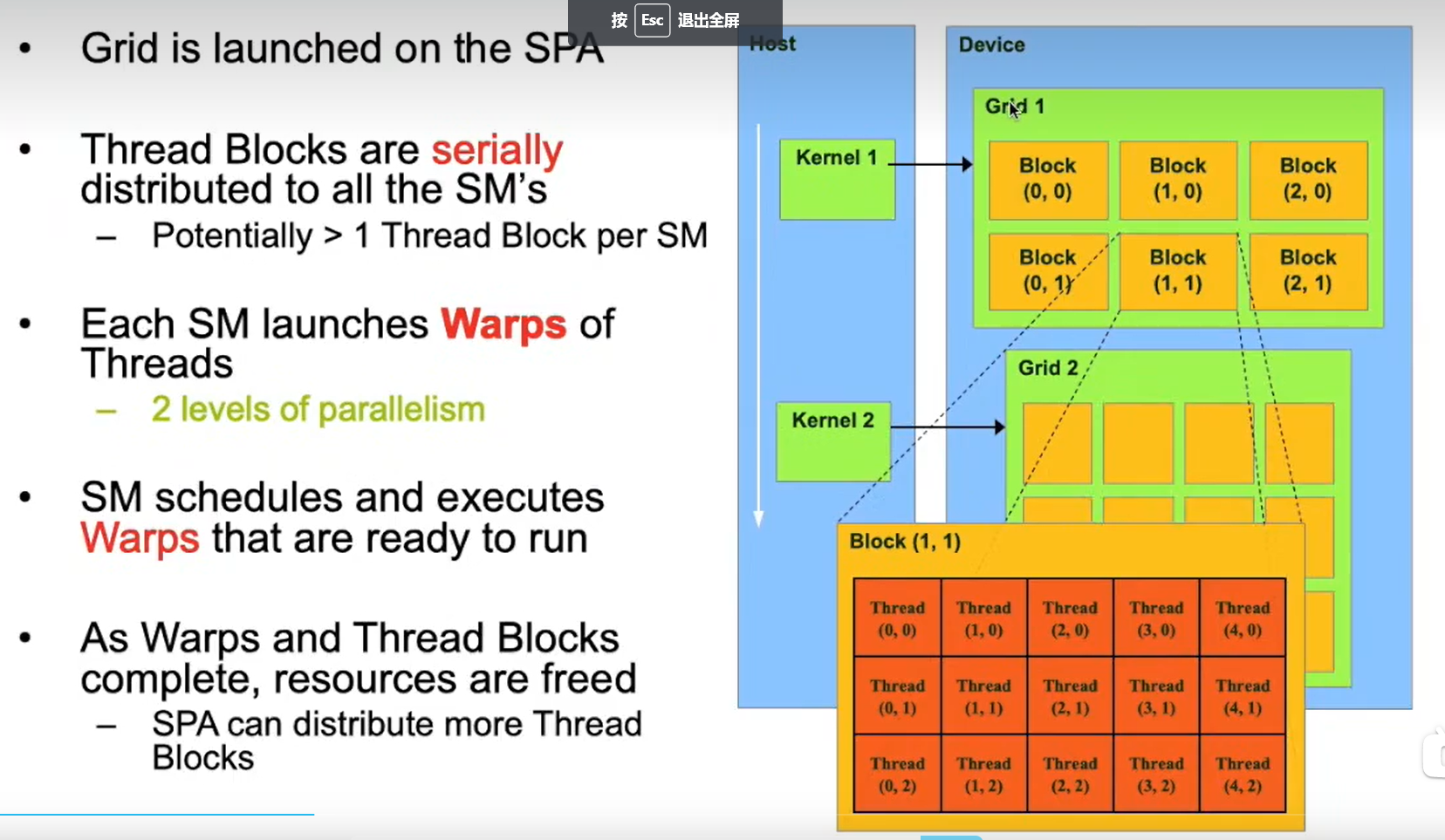
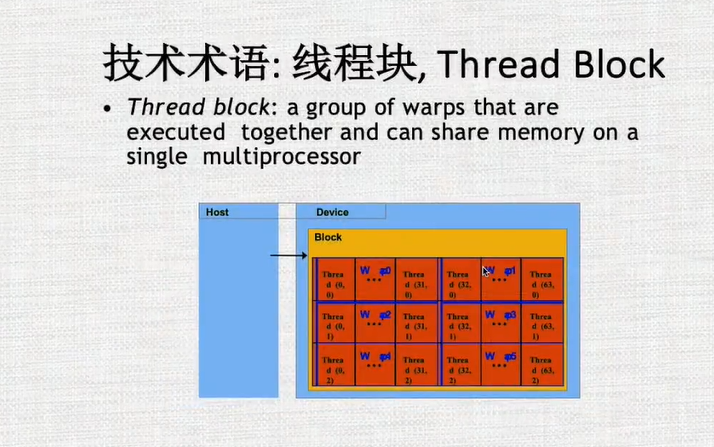
首先将所有的进程组成称为一个网格,网格之内分为不同的块,每个块中含有的线程数不能太少也不能太多,如果太大如2048个线程,那么每个块需要给线程提供的内存空间和资源就太多,块的开销就比较大。但是如果太小的话,不足以隐藏其调度的开销。
因为每32个线程组成一个warp,所以块内的线程数最好是32的倍数
每个块都独立的在SM中运行,不能够跨SM运行

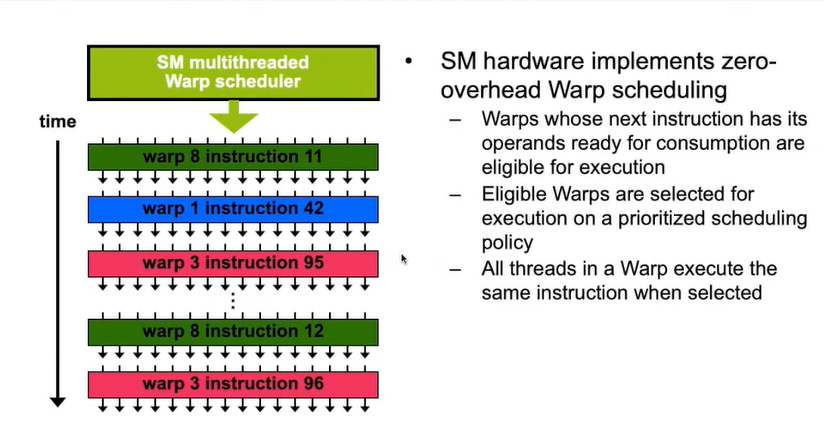
每32个线程可以组成一个warps, Warp Scheduler可以根据优先级,安排某个Warp内的线程执行
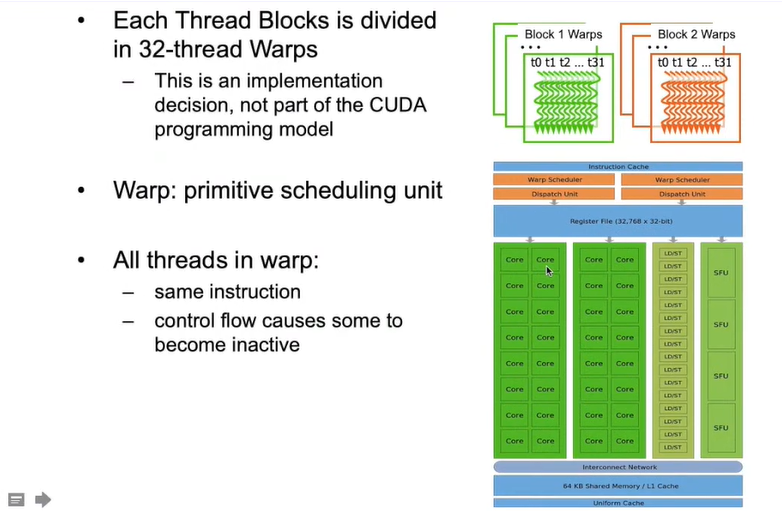
warp的切换是没有开销的,它依赖于硬件的调度器以及算法的判断,那个warp可以执行了就将其放入可执行的队列中去,按照优先级对其进行执行。
GPU的速度非常快,很适合做计算加速处理

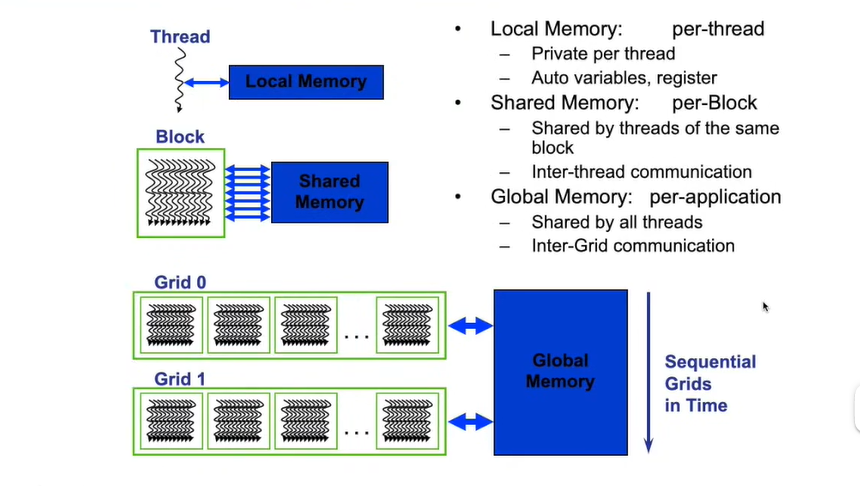
在GPU中,每个线程有自己的局部内存,而同一个块中,线程可以通过共享内存进行消息传递。
全局内存:被所有的线程共享。
因为共享内存针对于块,使用共享内存一般能比使用全局内存快两个数量级。但是共享内存是比较小的,
其和L1 cache加起来才64字节,但是全局内存可以达到8G,16G,64G甚至更多
在块内的线程可以共享数据或者结果,所以块内的线程有一些共享合作的机制

在设计程序时,一个块可能需要2k或者3k的寄存器。如果一个blocks需要4k寄存器,而一共有64k的寄存器,那么最多可以有16个block在同时运行

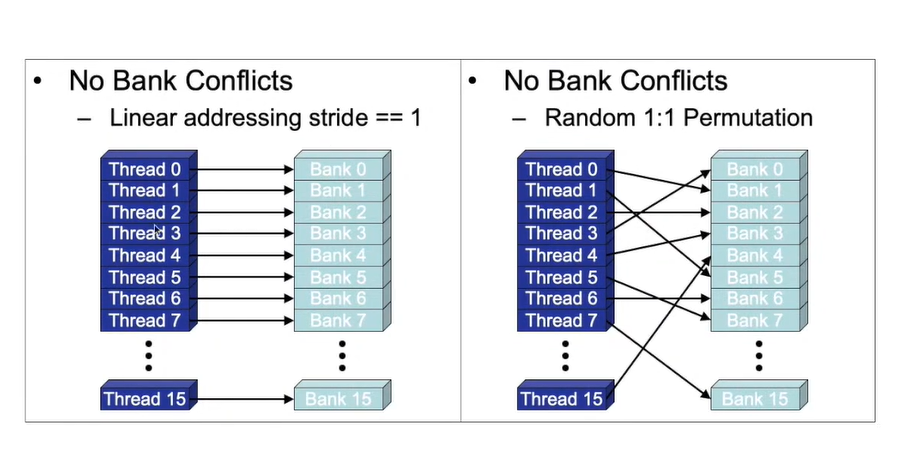
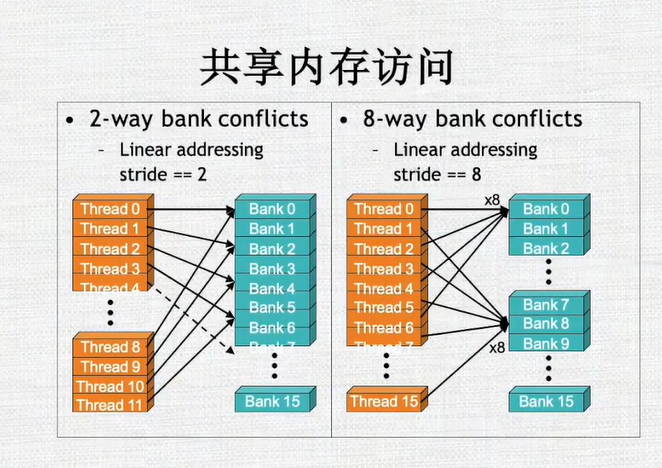
共享内存的访问:共享内存分多个banks。如果半个warp中的每个线程只访问一个bank,并且没有多个线程访问一个bank的话,一次内存访问就可以将所有的数据拿到。如果有多个线程访问同一个bank的话,就会产生冲突,那么这个访问会变成顺序执行的,这样使得本来一个时钟周期能够完成的事情需要多个时钟周期来完成

- 举例:线程之间访问没有冲突
-
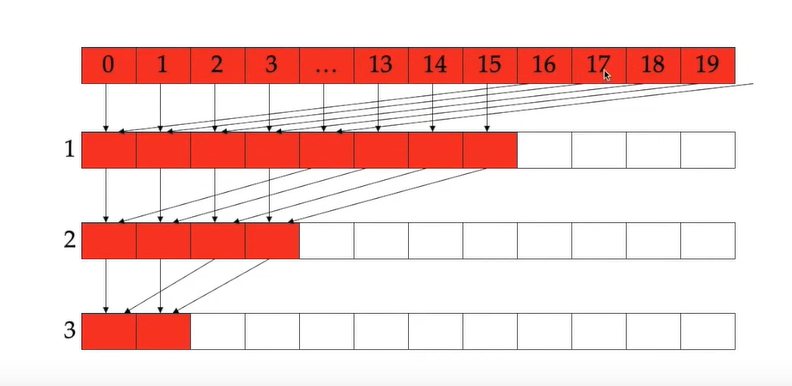
举例:线程之间访问有冲突
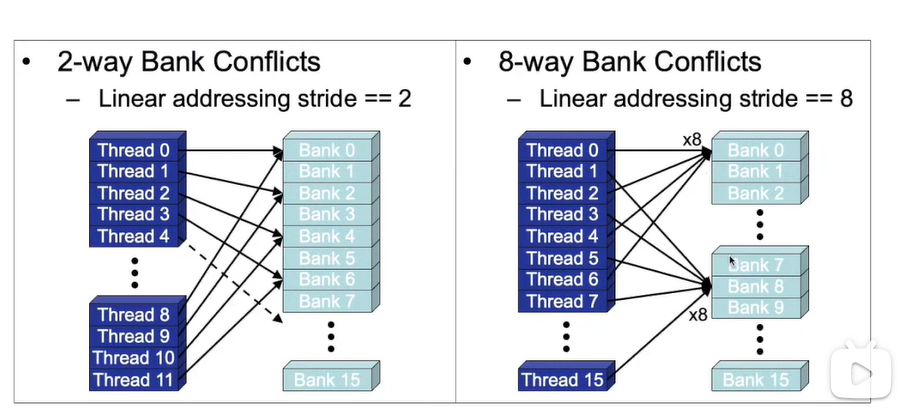
在使用GPU的共享内存时,要尽量保证线程之间没有bank冲突

-
举例:求序列和
这时候,两个线程之间通过共享内存通信可能会存在冲突
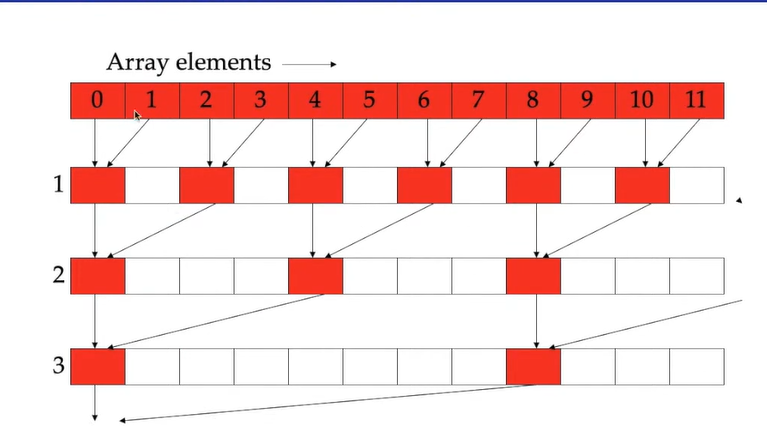
-
因为每半个warp访问一个banks共享内存组,这样可以保证没有冲突
3. GPU编程模型
3.1 GPU计算基础知识
CPU的核心较少,一般用于做逻辑控制,GPU的核心数多,用于做计算加速器。

3.2 CUDA程序执行流程

3.3 CUDA程序

3.4 CUDA代码实例

3.5 GPU程序层次结构


3.6 CUDA程序调用

3.7 区分host的device代码



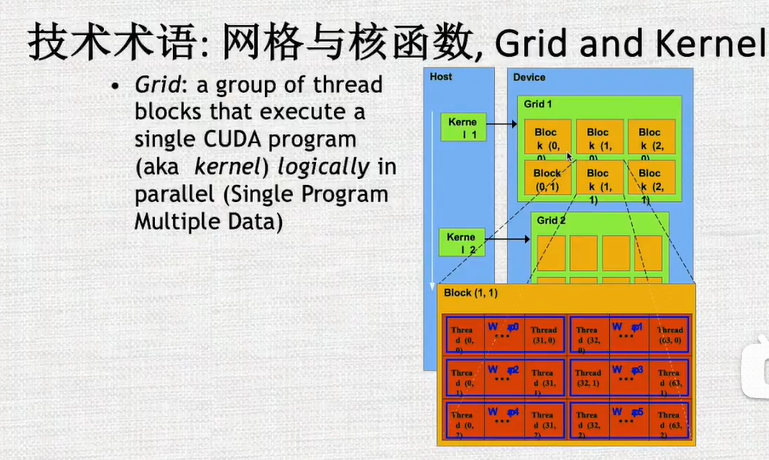
4. 详细介绍grip warp,block,thread


grip/block都可以是一维、二维、或者三维的


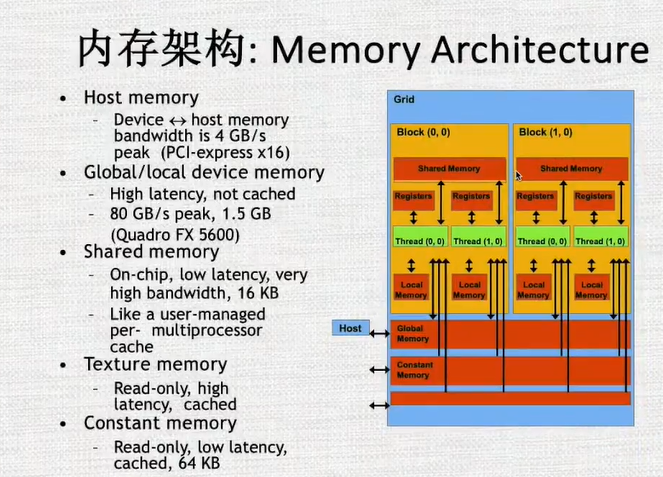
5.GPU内存

-
GPU和CPU速度对比
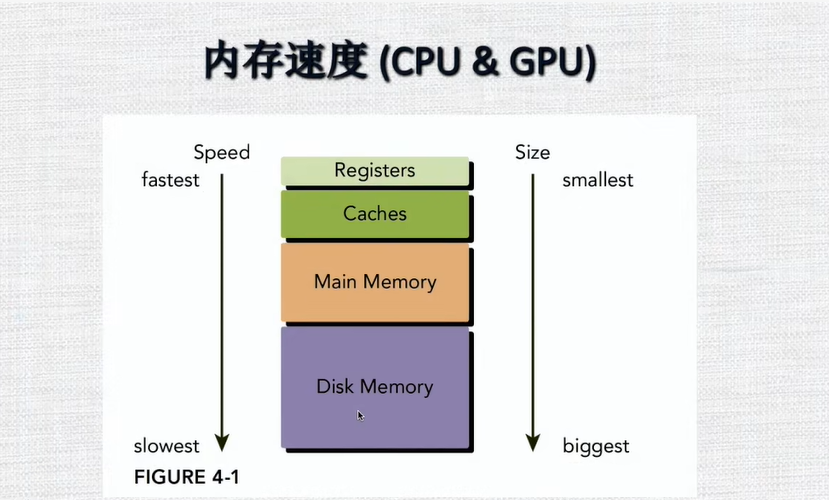
-
可编程内存

- 内存作用域和生命周期

-
寄存器
尽量少使用寄存器可以使得处于活动状态的块比较多

-
本地内存

-
共享内存


- 共享内存的访问冲突


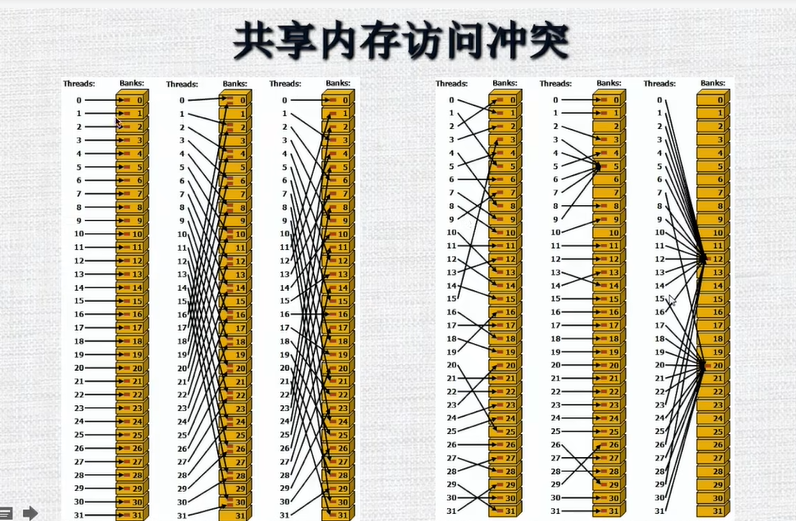
-
常量内存

-
纹理内存

-
全局内存

-
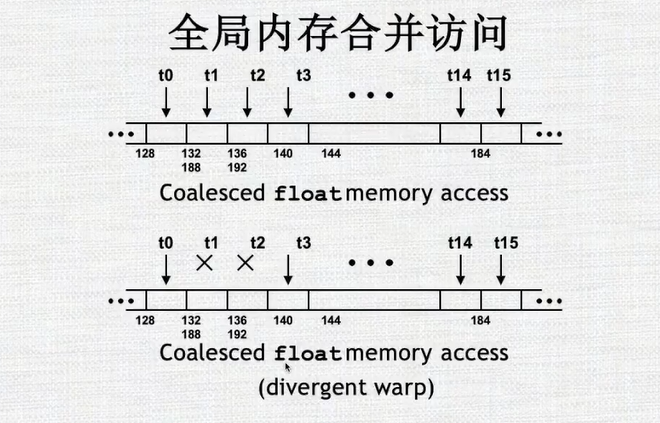
全局内存的访问

-
GPU缓存

6.GPU内存管理
- 内存使用

-
cpu内存

-
gpu内存

-
GPU全局内存分配释放

-
Host内存分配和释放

-
统一内存的分配与释放 一般是比较新的GPU才能申请统一内存

-
同步拷贝 只有当拷贝这个操作完成之时,才能够继续进行

-
异步拷贝,拷贝命令下达之后不等待,有一个问题就是不知道拷贝是否完成,如果数据从A->B,此时若读取B中的数据,有可能拷贝没有完成得到的是之前的数据。需要做一些检测来获知拷贝是否完成

-
共享内存


7.GPU内存使用代码解析

8.CPU程序架构以及硬件映射
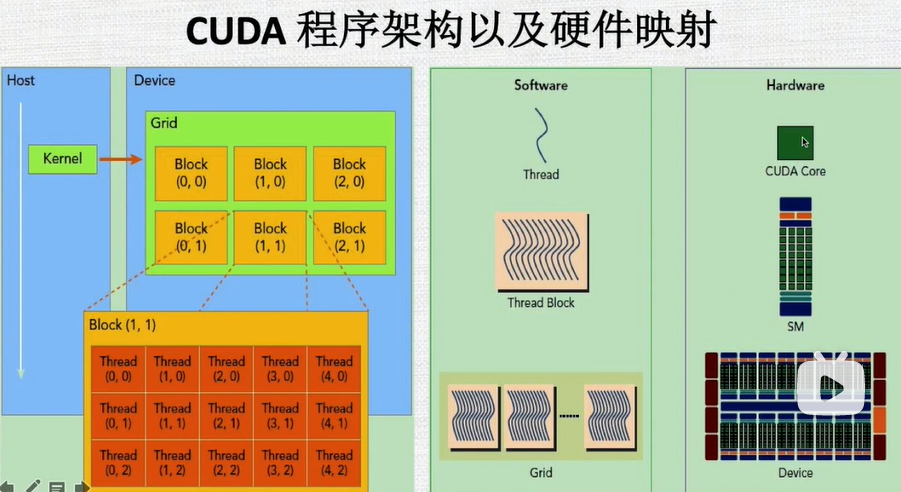
-
流式多处理器

-
CUDA内置变量

-
WARP技术细节

-
性能优化

9.规约算法

-
对于这种累加求和的方式,如果平常使用for循环的算法计算,时间复杂度为O(n)。
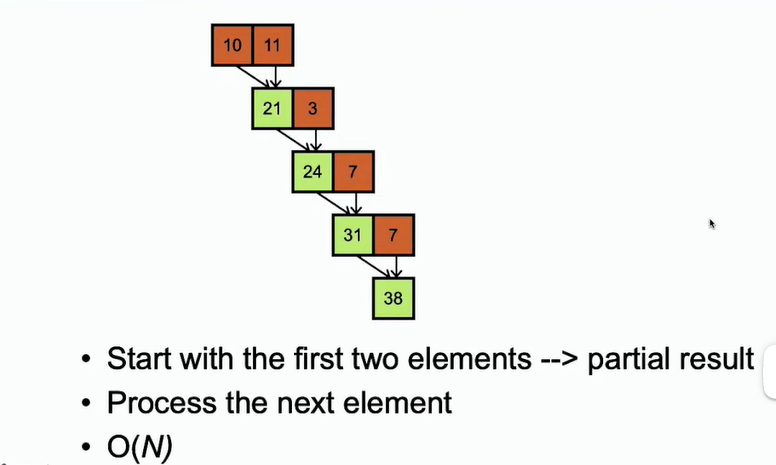
-
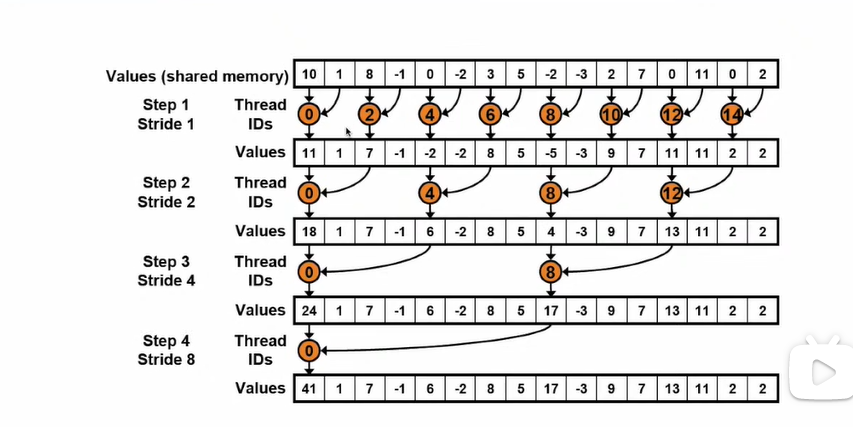
如果采用并行的计算方法,利用二叉树的方法进行并行。时间复杂度自然为log2N
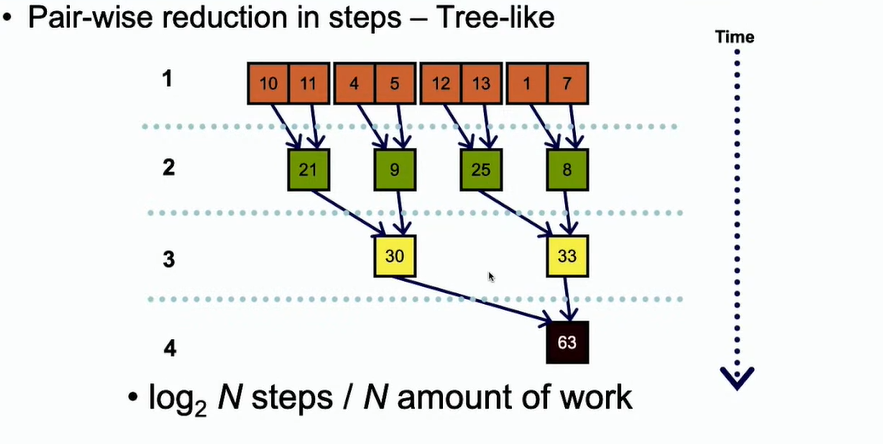
-
如果是4个一组进行并行,时间复杂度可以答案log4N
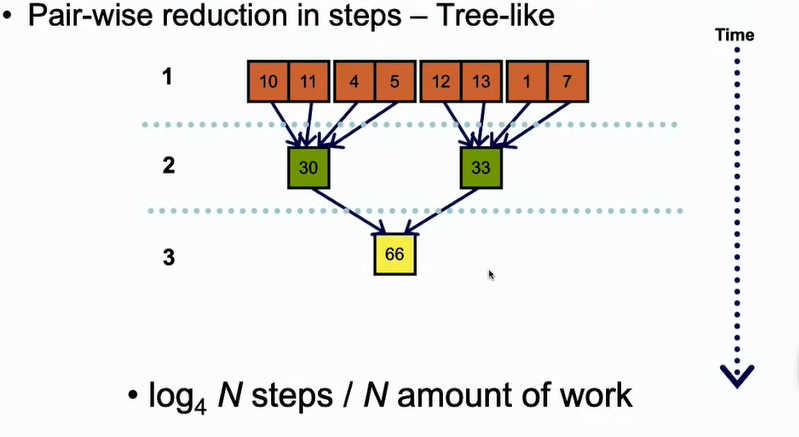
- 在GPU中如果只使用一个块,可以进行并行操作,但是会有很多SM块空闲。所以使用多个块,每个块负责一小部分,然后对块的结果再进行加和。

-
需要一个同步的操作,各个块得到自己的一个局部的规约结果,经过全局的同步,将其规约结果相加或者相乘。
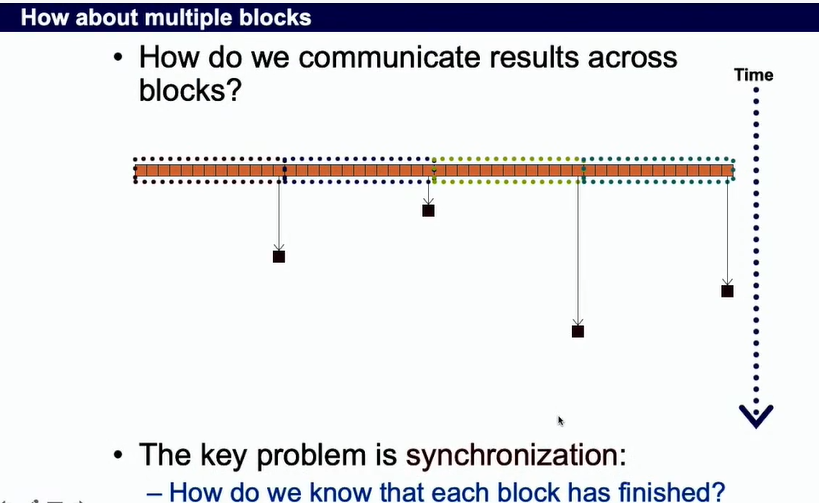
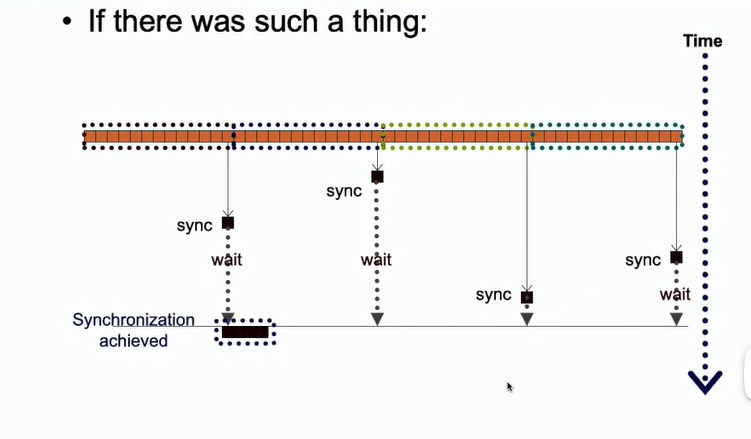
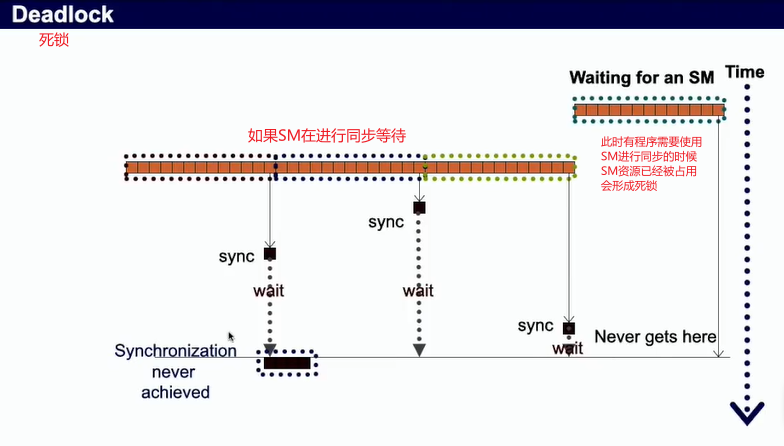
- CUDA是不支持全局同步的,因为全局同步块处于空闲状态,造成资源浪费


-
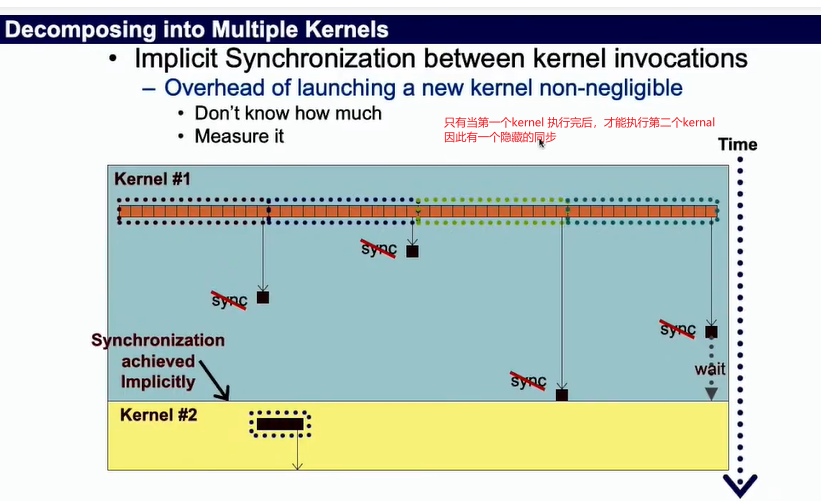
CUDA的解决方案 将其分成多个Kernal来进行计算
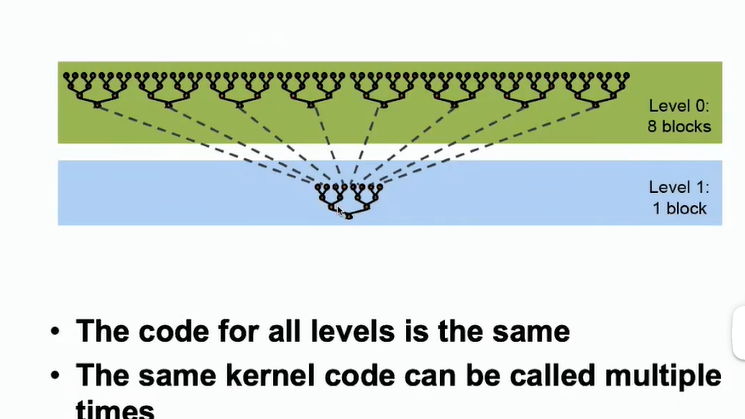
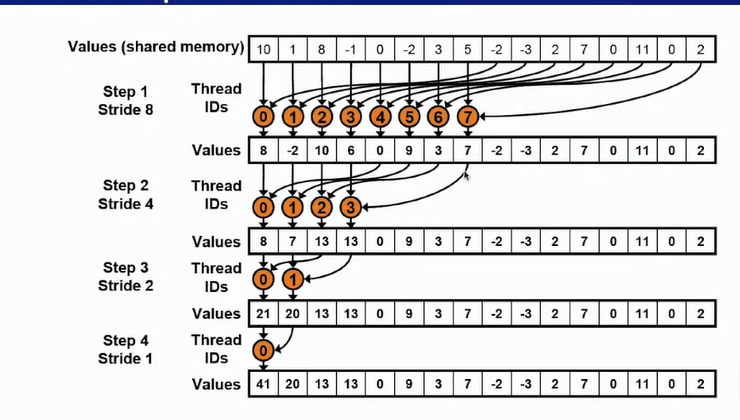
9.1 并行规约算法 二叉树

-
实现向量相加的伪代码

-
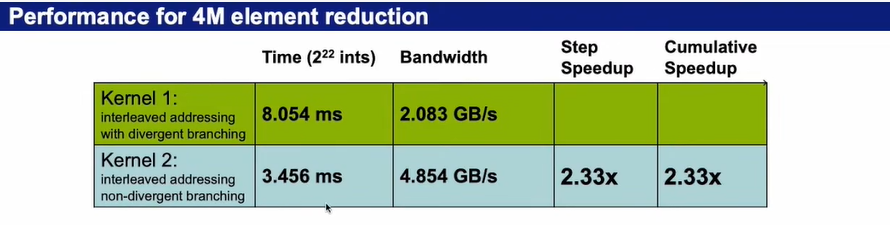
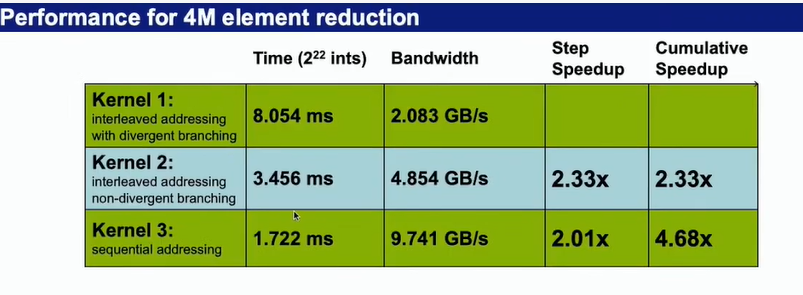
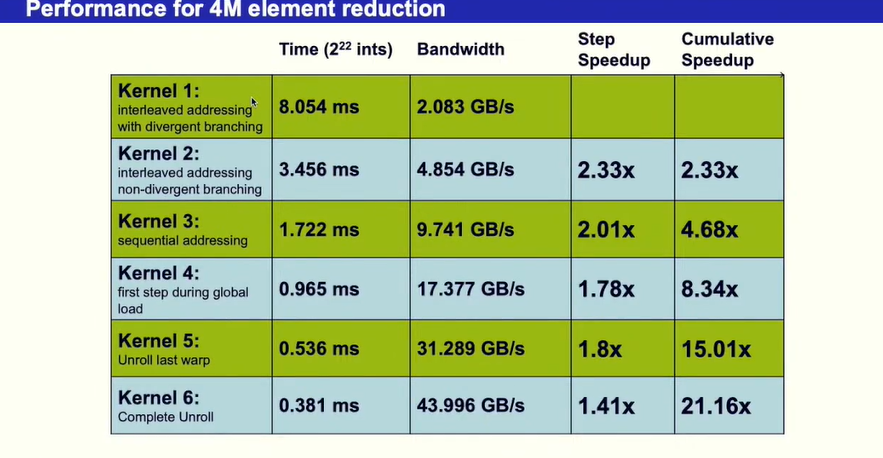
从算法的带宽来看,他的带块是2.083G每秒,说明其效果不是很理想

- 由于tid%2==0时候才进行相邻元素相加的操作,会导致同一个warp里的线程运行不同的命令,因此提出以下改进方法。

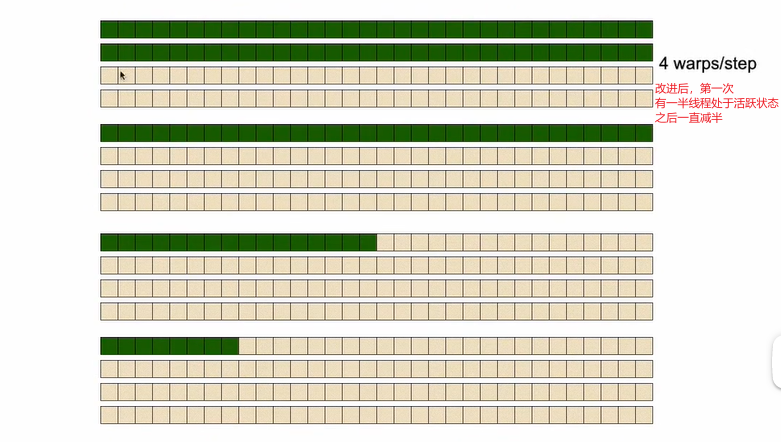
9.2 并行规约算法 改进共享内存访问
- 不将相邻的元素访问,跨一个bank的距离进行访问

- 运行效率对比
9.3改进全局内存访问
- 第一次将两个数据相加到共享内存

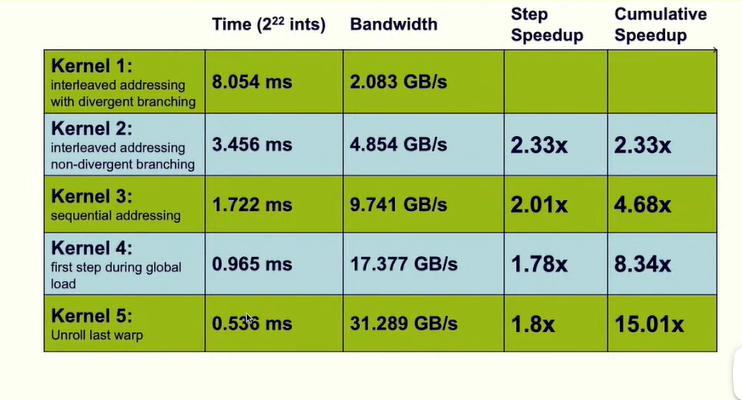
- 优化后运行性能对比

9.4 warp内循环展开
一些内存读取,存储的操作,循环变量的循环,同步,寻址操作,使得算法没有达到理论最优


- 算法改进

9.5 完全循环展开

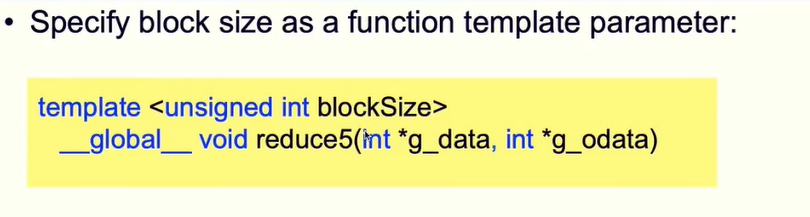


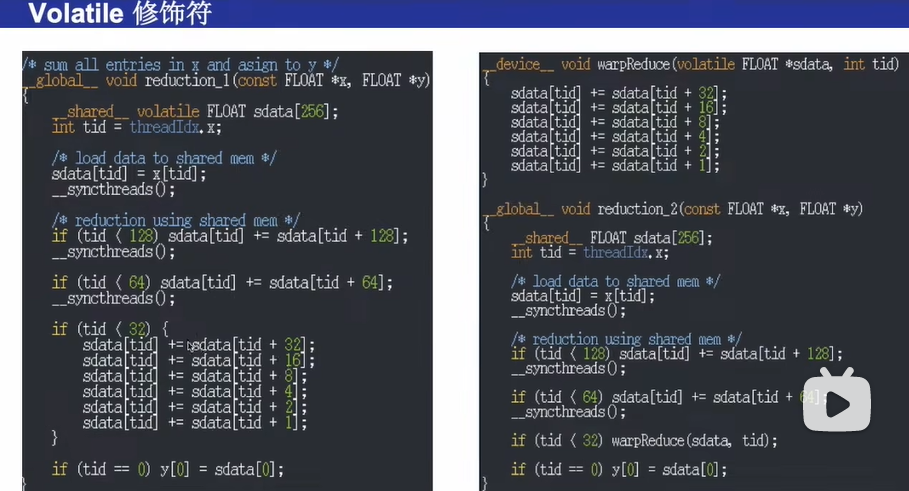
注意 编程是共享内存需要用volatile修饰,以免编译器的自动优化使得最后得出的结果是错误的
volatile是一个特征修饰符(type specifier).volatile的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值。
volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。
10.CUDA:高性能计算

GPU的线程是轻量级的,一般只需要完成一些非常简单的操作加减或者乘除,同时GPU的线程数量是非常庞大的


11.并行规约算法 内积


12. CUDA程序优化
-
最大化并行执行



- 最大化 occupancy=正在运行的warps数/最大的warps数


-
内存优化
-
在写程序是使用更多的计算,而不是内存访问





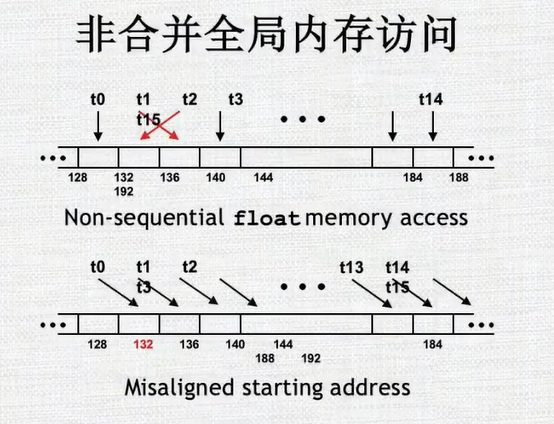
- t1和t2乱序,无法并行访问/t0对应的不是16的倍数,也无法并行访问
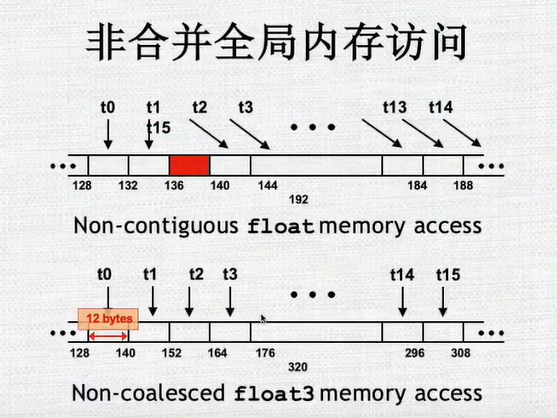




-
尽量使用一些高通量的指令,而不使用一些低通量的指令
-
只有在需要的时候才使用一些高精度的函数
-
尽量不要使warps中的指令不一样

-
不同指令的指令周期是不一样的






欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)