深度学习CUDA编程干货-kernel的编写和调用
title: 深度学习CUDA编程干货-kernel的编写和调用date: 2020-06-09 12:08:54category: 默认分类本文介绍 深度学习CUDA编程干货-kernel的编写和调用深度学习CUDA编程干货-kernel的编写和调用本文由林大佬原创,转载请注明出处,来自腾讯、阿里等一线AI算法工程师组成的QQ交流群欢迎你的加入: 1037662480上一篇给大家分享了一些CUD
title: 深度学习CUDA编程干货-kernel的编写和调用
date: 2020-06-09 12:08:54
category: 默认分类
本文介绍 深度学习CUDA编程干货-kernel的编写和调用
深度学习CUDA编程干货-kernel的编写和调用
本文由林大佬原创,转载请注明出处,来自腾讯、阿里等一线AI算法工程师组成的QQ交流群欢迎你的加入: 1037662480
上一篇给大家分享了一些CUDA编程的干货,这一篇来夯实一下,我们主要看一些基础的cuda概念。
三个层级
cuda编程主要是三个层级,分别是 thread,block和grid。
- 多个thread组成block;
- 多个block组成grid;
这样的话,thread实际上就是cuda里面最小的运行单位,实际上也是如此,你在kernel里面定义的threadIdx是唯一的标志。所以当我们要进行一个并行计算的时候,我们第一步要做的,实际上是如何设计这个grid,block以及thread配套使用。但是在这之前,我们还是需要了解一下CUDA kernel的调用方式以及它的意义。
CUDA的kernel
我们这里有一个kernel,很简单的:
__global__ void kernel(param list){ }
kernel<<<Dg,Db, Ns, S>>>(param list);
我们主要关心一下这里的 <<<Dg, Db, Ns, S>>>是什么意思?
事实上总结起来很简单:
- 三个尖括号没什么高级的,就是告诉编译器,接下来我要调用cuda的kernel了;
- 里面的kernel参数(不是kernel函数的参数),是告诉编译器用多少个线程来执行它;
- 里面有4个参数,其中都是可选的;
- Dg,第一个参数指的是定义Grid的维度和尺寸,为dim3的类型,也就是说一个grid有多少个block;
- Db,同理指的是block的维度和尺寸,是dim3的类型,也就是一个block有多少个thread;
- Ns,是可选的,它告诉编译器,它设置的是每个block除了静态分配的sharedmemory以外,最多能分配的sharedmemory大小,单位是byte;
- S是cudastream的可选参数。
因此,实际上我们需要用到只有两个参数,大多数情况下,这两个参数,分别是一个grid里面多少个block,一个是一个block里面多少个thread。
上面说道,这里的值是一个dim。这个dim实际上是一个xyz的维度,它的构成是:
dim3 dim = {x, y, z};
dim3 dim = {23, 1, 1};
这里的z,实际上是grid的数目,xy是block的size。同理定义thread的方式也一样,因此我们有
总共block有 Dg.x * Dg.y * Dg.z 个blocks,然后thread的总数是 Db.x * Db.y * Db.z个,其中Db.x 和 Db.y的最大值为512,计算能力比较decent的显卡上最大值通常是有限制的。
kernel中gridIdx和blockIdx用法
上面只是理论,但是实际上我们不是传入一个dim3的方式给kernel的参数,而通常是这样的:
sum<<< 512, 512 >>>()
那么我们的问题来了:这里面的Idx循环到底是怎么循环的呢?。这里的int变量和dim3其实是一个意思,只不过这里指的是一维的排布。简单来说,就是一个grid里面有512个block,一个block里面有512个thread。
用一张图来表示grid和block以及thread的排布方式可以如图:
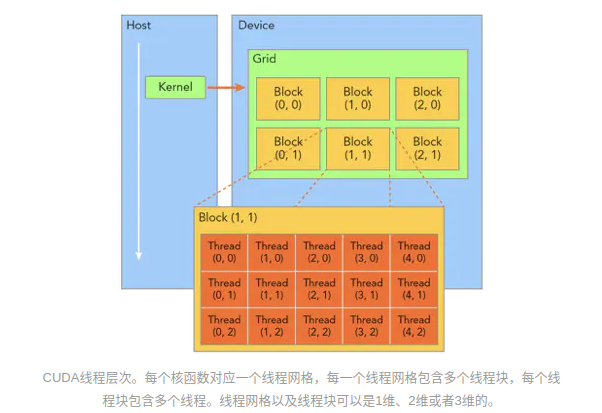
那么,如果我们有这样的定义:
dim3 grid(3, 2, 1), block(5, 3, 1)
这个意思就是,grid里面有3x2排布的block,block里面是5x3的排布。
假如我们传入的kernel参数就上上面这个,那么在kernel里面,我们这样定义Idx:
int idx = blockDim.x * blockIdx.x + threadIdx.x;
这里面跑的循环是多少呢?
实际上我们循环了3x2x5x3=90次。实际上当你定义了dim都是两个三维的排布方式,那么相应的idx取值的时候也需要使用三维的排布方式。
三维的其实不是很好理解,我们用两维的来展示一下:
比如一个kernel这样调用:
kernel<<<4, 8>>>()
然后它的Idx排布是这样的:

我们有4个线程块,每个线程块有8个线程,那么我们如何获取每一个线程的idx?
int idx = blockIdx.x * blockDim.x + threadIdx.x
最后不得不说,如果是3维的情况,会比较复杂。这里给大家提供一段3维情况下的打印threadID的例子:
#include <stdio.h>
#include <cuda.h>
__global__ void printThreadIndex() {
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy*blockDim.x * gridDim.x + ix;
printf("thread_id (%d,%d) block_id (%d,%d) coordinate (%d, %d), global index %2d \n",
threadIdx.x, threadIdx.y, blockIdx.x, blockIdx.y, ix, iy, idx);
}
int main(void) {
dim3 grid(2, 3, 1), block(4, 8, 1);
printThreadIndex<<<grid, block>>>();
cudaResetDevice();
return 0;
}
CUDA blocksize设计的讲究
对于我们炼丹的来说,我们不关心太复杂的kernel设计,最简单的,对图片的w和h进行并行化的操作,那么讲道理,我只需要这样调用kernel就可以了:
kernel<<<244, 244>>>
这样的话,w和h就并行了,大大的提高了效率,但是很多时候你会看到人们都是这么用的 :
BLOCK=512;
dim3 cudaGridSize(uint n)
{
uint k = (n - 1) /BLOCK + 1;
uint x = k ;
uint y = 1 ;
if (x > 65535 )
{
x = ceil(sqrt(x));
y = (n - 1 )/(x*BLOCK) + 1;
}
dim3 d = {x,y,1} ;
return d;
}
int num = w*h;
FCOSforward_kernel << < cudaGridSize(num), BLOCK >> > ()
所以说,这里的BLOCK的设计是有什么讲究吗 ?如果你去谷歌你会发现都是一些说合理设置BLOCK使得sharedmemory占满的说法,笔者试验下来,好像对于我们这么一些简单的使用场合,差别并不是很大。
重点是看起来那些优化比较复杂并且难以控制。等到后面我们更加深入的学习之后再来分享一波把。

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)