CUDA学习之全局内存--part1
文章目录4.1 CUDA内存模型概述执行模型中,核的配置,决定了程序执行效率,但是程序的执行效率不只由线程束,线程块等执行结构决定,内存也严重的影响了性能。4.1 CUDA内存模型概述
文章目录
执行模型中,核的配置,决定了程序执行效率,但是程序的执行效率不只由线程束,线程块等执行结构决定,内存也严重的影响了性能。
4.1 CUDA内存模型概述
CUDA采用的内存模型,结合了主机和设备内存系统,展现了完整的内存层次模型,其中大部分内存我们可以通过编程控制,来使我们的程序性能得到优化。
4.1.1 内存层次结构的优点
程序具有局部性特点,包括:
-
时间局部性:就是一个内存位置的数据某时刻被引用,那么在此时刻附近也很有可能被引用,随时间流逝,该数据被引用的可能性逐渐降低。.
-
空间局部性:空间局部性,如果某一内存位置的数据被使用,那么附近的数据也有可能被使用。
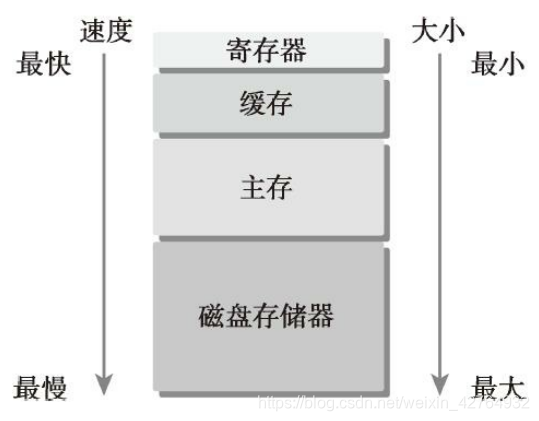
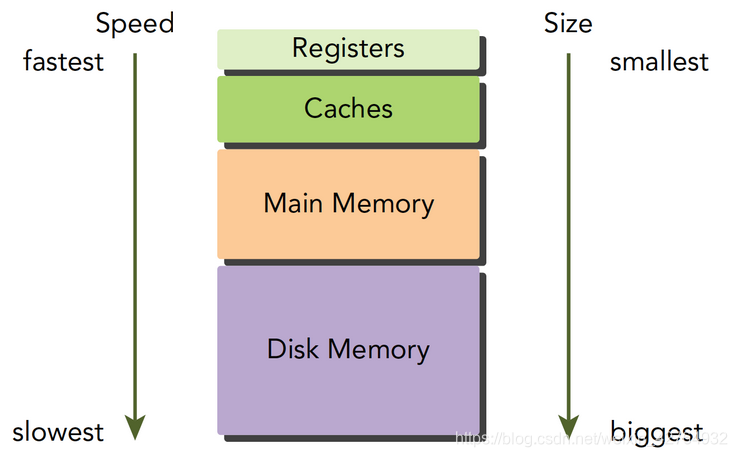
CPU和GPU的主存都是采用DRAM——动态随机存取存储器,而低延迟的内存,比如一级缓存,则采用SRAM——静态随机存取存储器。虽然底层的存储器延迟高,容量大,但是其中有数据被频繁使用的时候,就会向更高一级的层次传输,比如我们运行程序处理数据的时候,程序第一步就是把硬盘里的数据传输到主存里面。
GPU和CPU的内存设计有相似的准则和模型。但他们的区别是:CUDA编程模型将内存层次结构更好的呈献给开发者,让我们显示的控制其行为。
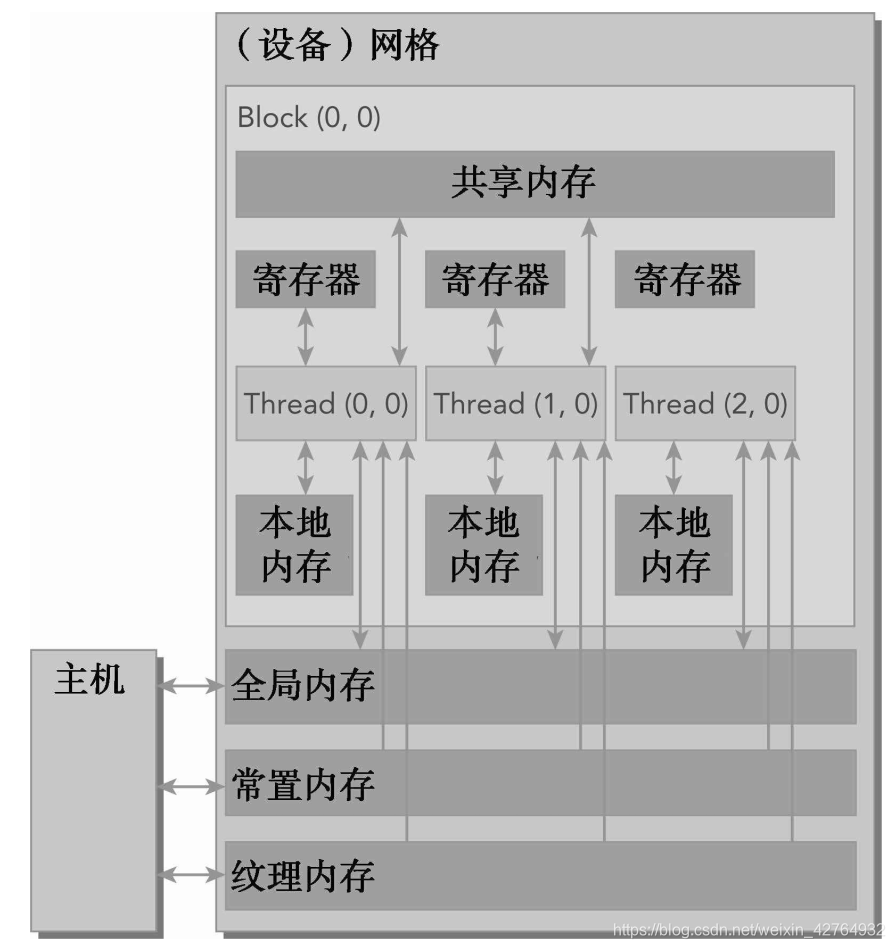
4.1.2 CUDA内存模型
在CPU内存层次结构中,一级缓存和二级缓存都是不可编程的存储器。
另一方面,CUDA内存模型提出了多种可编程内存的类型:
寄存器
共享内存
本地内存
常量内存
纹理内存
全局内存
各种都有自己的作用域,生命周期和缓存行为。
- CUDA中每个线程都有自己的私有的本地内存;
- 线程块有自己的共享内存,对线程块内所有线程可见;
- 所有线程都能访问读取常量内存和纹理内存,但是不能写,因为他们是只读的;
- 全局内存,常量内存和纹理内存空间有不同的用途。
- 对于一个应用来说,全局内存,常量内存和纹理内存有相同的生命周期。
1. 寄存器
寄存器无论是在CPU还是在GPU都是速度最快的内存空间,但是和CPU不同的是GPU的寄存器储量要多一些。
在CPU运行的程序中,只有当前在计算的变量存储在寄存器中,其余在主存中,使用时传输至寄存器。
而核函数内不加修饰的声明一个变量,此变量就存储在寄存器中。在核函数中定义的有常数长度的数组也是在寄存器中分配地址的。
寄存器对于每个线程是私有的,寄存器通常保存被频繁使用的私有变量,注意这里的变量也一定不能使共有的,不然的话彼此之间不可见,就会导致大家同时改变一个变量而互相不知道。
寄存器变量的声明周期和核函数一致,从开始运行到运行结束,执行完毕后,寄存器就不能访问了。
寄存器是SM中的稀缺资源,Fermi架构中每个线程最多63个寄存器。Kepler结构扩展到255个寄存器,一个线程如果使用更少的寄存器,那么就会有更多的常驻线程块,SM上并发的线程块越多,效率越高,性能和使用率也就越高。
那么问题就来了,如果一个线程里面的变量太多,以至于寄存器完全不够呢?这时候寄存器发生溢出,本地内存就会过来帮忙存储多出来的变量,这种情况会对效率产生非常负面的影响,所以,不到万不得已,一定要避免此种情况发生。
为了避免寄存器溢出,可以在核函数的代码中配置额外的信息来辅助编译器优化,比如:
__global__ void
__lauch_bounds__(maxThreadaPerBlock,minBlocksPerMultiprocessor)
kernel(...) {
/* kernel code */
}
这里面在核函数定义前加了一个 关键字 lauch_bounds,然后他后面对应了两个变量:
maxThreadaPerBlock:线程块内包含的最大线程数,线程块由核函数来启动
minBlocksPerMultiprocessor:可选参数,每个SM中预期的最小的常驻内存块参数
对于给定的核函数,最优的启动边界会因主要架构的版本不同而有所不同。
也可以在编译选项中加入
-maxrregcount=32
来控制一个编译单元里所有核函数使用的最大数量。
2. 本地内存
核函数中符合存储在寄存器中 但不能进入被核函数分配的寄存器空间中的变量将存储在本地内存中,编译器可能存放在本地内存中的变量有以下几种:
-
使用未知索引引用的本地数组
-
可能会占用大量寄存器空间的较大本地数组或者结构体
-
任何不满足核函数寄存器限定条件的变量
本地内存实质上是和全局内存一样在同一块存储区域当中的,其访问特点——高延迟,低带宽。
对于2.0以上的设备,本地内存存储在每个SM的一级缓存,或者设备的二级缓存上。
3. 共享内存
在核函数中使用如下修饰符的内存,称为共享内存:
__share__
每个SM都有一定数量的由线程块分配的共享内存,共享内存是片上内存,跟主存相比,速度要快很多,也即是延迟低,带宽高。其类似于一级缓存,但是可以被编程。
使用共享内存的时候一定要注意,不要因为过度使用共享内存,而导致SM上活跃的线程束减少,也就是说,一个线程块使用的共享内存过多,导致更过的线程块没办法被SM启动,这样影响活跃的线程束数量。
共享内存在核函数内声明,生命周期和线程块一致,线程块运行开始,此块的共享内存被分配,当此块结束,则共享内存被释放。
因为共享内存是块内线程可见的,所以就有竞争问题的存在,也可以通过共享内存进行通信,当然,为了避免内存竞争,可以使用同步语句:
void __syncthreads();
此语句相当于在线程块执行时各个线程的一个障碍点,当块内所有线程都执行到本障碍点的时候才能进行下一步的计算,这样可以设计出避免内存竞争的共享内存使用程序、
注意,__syncthreads();频繁使用会影响内核执行效率。
SM中的一级缓存,和共享内存共享一个64k的片上内存 ,他们通过静态划分,划分彼此的容量,运行时可以通过下面语句进行设置:
cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache);
这个函数可以设置内核的共享内存和一级缓存之间的比例。cudaFuncCache参数可选如下配置:
cudaFuncCachePreferNone//无参考值,默认设置
cudaFuncCachePreferShared//48k共享内存,16k一级缓存
cudaFuncCachePreferL1// 48k一级缓存,16k共享内存
cudaFuncCachePreferEqual// 32k一级缓存,32k共享内存
Fermi架构支持前三种,Kepler设备都支持。
4. 常量内存
常量内存驻留在设备内存中,每个SM都有专用的常量内存缓存,常量内存使用__constant__修饰。
常量内存在核函数外,全局范围内声明,对于所有设备,只可以声明64k的常量内存,常量内存静态声明,并对同一编译单元中的所有核函数可见。
常量内存,不能被修改的,这里不能被修改指的是被核函数修改,主机端代码是可以初始化常量内存的,初始化函数如下:
cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count);
同 cudaMemcpy的参数列表相似,从src复制count个字节的内存到symbol里面,也就是设备端的常量内存。多数情况下此函数是同步的,也就是会马上被执行。
当线程束中所有线程都从相同的地址取数据时,常量内存表现较好,比如执行某一个多项式计算,系数都存在常量内存里效率会非常高,
但是如果不同的线程取不同地址的数据,常量内存就不那么好了,
因为常量内存的读取机制是:
一次读取会广播给所有线程束内的线程。
5. 纹理内存
纹理内存驻留在设备内存中,在每个SM的只读缓存中缓存,
纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,它可以将浮点插入作为读取过程中的一部分来执行,纹理内存是对二维空间局部性的优化。
总的来说纹理内存设计目的应该是为了GPU本职工作显示设计的,但是对于某些特定的程序可能效果更好,比如需要滤波的程序,可以直接通过硬件完成。
6. 全局内存
GPU上最大的内存空间,延迟最高,使用最常见的内存,global指的是作用域和生命周期,可以在任何SM被访问,在主机端使用cuda-Malloc函数分配全局内存,使用cudaFree函数释放全局内存。然后指向全局内存的指针就会作为参数传递给核函数。
全局内存可以动态声明,或者静态声明,可以用下面的修饰符在设备代码中静态的声明一个变量:
__device__
全局内存分配空间存在于应用程序的整个生命周期中,并且可以访问所有核函数中的所有线程。
从多个线程访问全局内存时必须注意。因为线程的执行不能跨线程块同步,不同线程块内的多个线程并发地修改全局内存的同一位置可能会出现问题,这将导致一个未定义的程序行为。
因为全局内存的性质,当有多个核函数同时执行的时候,如果使用到了同一全局变量,应注意内存竞争。
全局内存常驻于设备内存中,可通过32字节、64字节或128字节的内存事务进行访问。这些内存事务必须自然对齐,也就是说,首地址必须是32字节、64字节或128字节的倍数。
所以当线程束执行内存加载/存储时,需要满足的传输数量通常取决与以下两个因素:
- 跨线程的内存地址分布
- 内存事务的对齐方式。
一般情况下满足内存请求的事务越多,未使用的字节被传输的可能性越大,数据吞吐量就会降低,换句话说,对齐的读写模式使得不需要的数据也被传输
1.1以下的设备对内存访问要求非常严格(为了达到高效,访问受到限制)因为当时还没有缓存,现在的设备都有缓存了,所以宽松了一些。
接下来演技如何优化全局内存访问,最大程度提高全局内存的数据吞吐量。
7. GPU缓存
与CPU缓存类似,GPU缓存不可编程,其行为出厂是时已经设定好了。GPU上有4种缓存:
一级缓存
二级缓存
只读常量缓存
只读纹理缓存
每个SM都有一个一级缓存,所有SM公用一个二级缓存。
一级二级缓存的作用都是被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。
Fermi,Kepler以及以后的设备,CUDA允许我们配置读操作的数据是使用一级缓存和二级缓存,还是只使用二级缓存。
与CPU不同的是,CPU读写过程都有可能被缓存,但是GPU写的过程不被缓存,只有加载会被缓存!
每个SM有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各自内存空间内的读取性能。
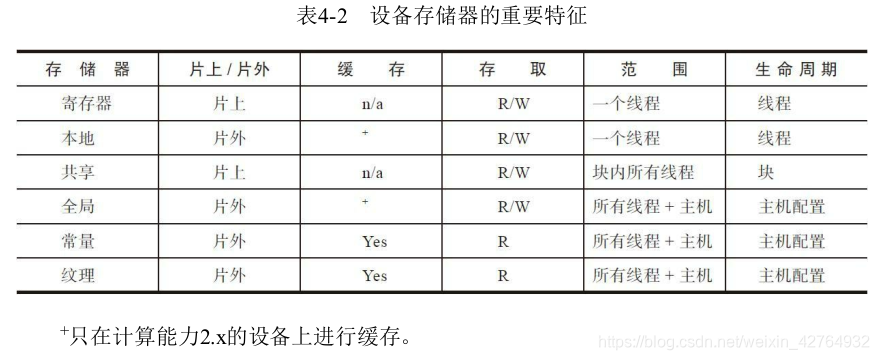
8. CUDA变量声明总结
CUDA变量声明和它们相应的存储位置、作用域、生命周期和修饰符。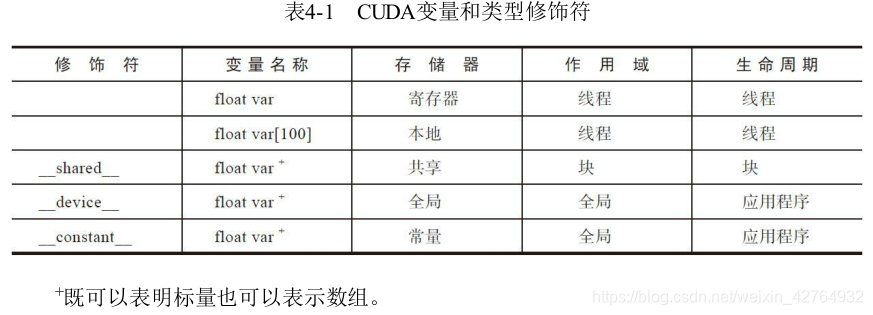
9. 静态全局内存
CPU内存有动态分配和静态分配两种类型,从内存位置来说,动态分配在堆上进行,静态分配在栈上进行,在代码上的表现是一个需要new,malloc等类似的函数动态分配空间,并用delete和free来释放。
在CUDA中也有类似的动态静态之分,动态分配为cudaMalloc。
而 静态分配与动态分配相同是,也需要显式的将内存copy到设备端:
#include <cuda_runtime.h>
#include <stdio.h>
__device__ float devData; // 一个浮点类型的全局变量在文件作用域内被声明
__global__ void checkGlobalVariable()
{
printf("Device: The value of the global variable is %f\n",devData);
devData+=2.0;
}
int main()
{
float value=3.14f;
cudaMemcpyToSymbol(devData,&value,sizeof(float));
printf("Host: copy %f to the global variable\n",value);
checkGlobalVariable<<<1,1>>>();
cudaMemcpyFromSymbol(&value,devData,sizeof(float));
printf("Host: the value changed by the kernel to %f \n",value);
cudaDeviceReset();
return EXIT_SUCCESS;
}

静态全局变量声明与赋值:
__device__ float devData; //必须在整个文件作用域声明
float value=3.14f;
cudaMemcpyToSymbol(devData,&value,sizeof(float)); //主机端赋值
-
在主机端,devData只是一个标识符,不是设备全局内存的变量地址
-
在核函数中,devData就是一个全局内存中的变量。
-
主机代码不能直接访问设备变量,设备也不能访问主机变量
设备变量devData在代码中定义的时候其实就是一个指针,这个指针指向何处,主机端是不知道的,指向的内容也不知道,想知道指向的内容,唯一的办法还是通过显式的办法传输过来
cudaMemcpyFromSymbol(&value,devData,sizeof(float));
主机端不可以对设备变量进行取地址操作!这是非法的!
想要得到devData的地址可以用下面方法:
float *dptr=NULL;
cudaGetSymbolAddress((void**)&dptr,devData);
不能用动态copy的方法给静态变量赋值!
如果非要用cudaMemcpy,只能用下面的方式:
float *dptr=NULL;
cudaGetSymbolAddress((void**)&dptr,devData);
cudaMemcpy(dptr,&value,sizeof(float),cudaMemcpyHostToDevice);
有一个例外,可以直接从主机引用GPU内存——CUDA固定内存。后面我们会研究这部分。
做个对比,动态全局变量:
int *d_idata = NULL;
CHECK(cudaMalloc((void **) &d_idata, bytes));
CHECK(cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice));
.
.
.
add_gpu<<<grid, block>>>(d_idata, d_odata, size); //需要传参
4.2 内存管理
4.2.1 内存分配和释放
CUDA编程模型假设了一个包含一个主机和一个设备的异构系统,每一个异构系统都有自己独立的内存空间。
核函数在设备内存空间中运行,CUDA运行时提供函数以分配和释放设备内存。
内存分配
cudaError_t cudaMalloc(void **devptr, size_t count);
这个函数在设备上分配了count字节的全局内存,并用devptr指针返回该内存的地址。所分配的内存支持任何变量类型,包括整型、浮点类型变量、布尔类型等。如果cuda-Malloc函数执行失败则返回cudaErrorMemoryAllocation。在已分配的全局内存中的值不会被清除。
float * devMem=NULL;
cudaError_t cudaMalloc((float**)&devMem, count)
devMem是一个指针,定义时初始化指向NULL,这样做是安全的,避免出现野指针,cudaMalloc函数要修改devMem的值,所以必须把他的指针传递给函数,如果把devMem当做参数传递,经过函数后,指针的内容还是NULL。
当分配完地址后,可以使用下面函数进行初始化:
cudaError_t cudaMemset(void * devPtr,int value,size_t count)
用法和Memset类似,但是注意,这些被我们操作的内存对应的物理内存都在GPU上。
释放
当分配的内存不被使用时,使用下面语句释放程序。
cudaError_t cudaFree(void * devPtr)
注意这个参数一定是前面cudaMalloc类的函数(还有其他分配函数)分配的空间,如果输入非法指针参数,会返回 cudaErrorInvalidDevicePointer 错误,如果重复释放一个空间,也会报错。
目前为止,套路基本和C语言一致。但是,设备内存的分配和释放非常影响性能,所以,尽量重复利用!
4.2.2 内存传输
对于异构计算, 主机线程不能访问设备内存,设备线程也不能访问主机内存,需要传送数据:
cudaError_t cudaMemcpy(void *dst,const void * src,size_t count,enum cudaMemcpyKind kind)
//eg:
//cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice)
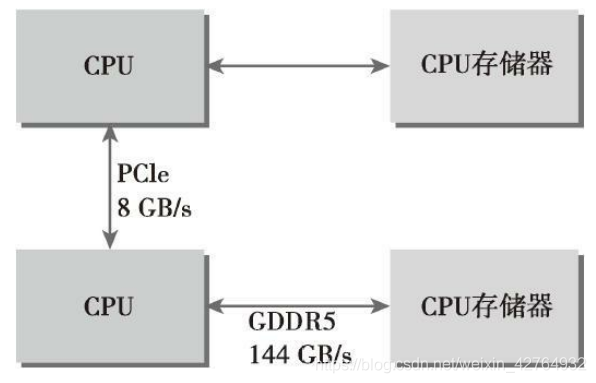
GPU的内存理论峰值带宽非常高,对于Fermi C2050 有144GB/s;而CPU和GPU之间通信要经过PCIe总线,总线的理论峰值要低很多——8GB/s左右,也就是说:
CUDA编程需要大家减少主机和设备之间的内存传输。
4.2.3 固定内存
主机内存采用分页式管理,通俗的说法就是操作系统把物理内存分成一些“页”,然后给一个应用程序一大块内存,但是这一大块内存可能在一些不连续的页上,应用只能看到虚拟的内存地址,而操作系统可能随时更换物理地址的页(从原始地址复制到另一个地址)但是应用是不会察觉。
但是从主机传输到设备上的时候,如果此时发生了页面移动,对于传输操作来说是致命的,所以在数据传输之前,CUDA驱动会锁定页面,或者直接分配固定的主机内存,将主机源数据复制到固定内存上,然后从固定内存传输数据到设备上: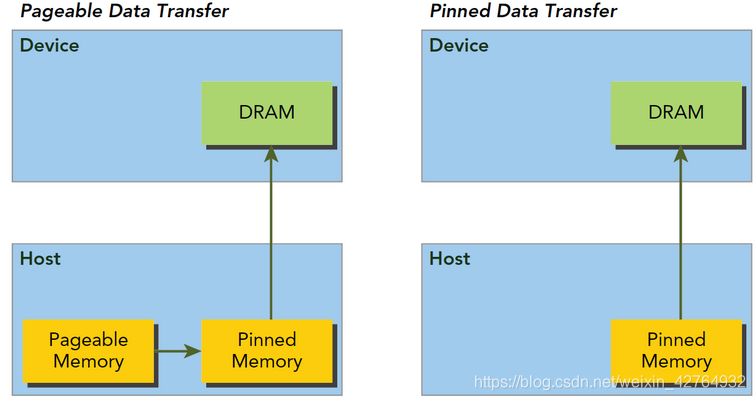
- 上图左边是正常分配内存,传输过程是:锁页-复制到固定内存-复制到设备
- 右边时分配时就是固定内存,直接传输到设备上。
下面函数用来分配固定内存:
cudaError_t cudaMallocHost(void ** devPtr,size_t count)
分配count字节的固定内存,这些内存是页面锁定的,可以直接传输到设备的,比可分页内存高得多的带宽进行读写。然而,分配过多的固定内存可能会降低主机系统的性能,因为它减少了用于存储虚拟内存数据的可分页内存的数量,其中分页内存对主机系统是可用的。
固定的主机内存释放使用:
cudaError_t cudaFreeHost(void *ptr)
与可分页内存相比,固定内存的分配和释放成本更高,但是它为大规模数据传输提供了更高的传输吞吐量。
相对于可分页内存,使用固定内存获得的加速取决于设备计算能力。例如,当传输超过10MB的数据时,在Fermi设备上使用固定内存通常是更好的选择。
将许多小的传输批处理为一个更大的传输能提高性能,因为它减少了单位传输消耗。
主机和设备之间的数据传输有时可以与内核执行重叠。
4.2.4 零拷贝内存
通常来说,主机不能直接访问设备变量,同时设备也不能直接访问主机变量。但有一个例外:零拷贝内存。主机和设备都可以访问零拷贝内存。
GPU线程可以直接访问零拷贝内存,这部分内存在主机内存里面,CUDA核函数使用零拷贝内存有以下几种情况:
- 当设备内存不足的时候可以利用主机内存
- 避免主机和设备之间的显式内存传输
- 提高PCIe传输率
前面我们讲,注意线程之间的内存竞争,因为他们可以同时访问同一个内存地址,现在设备和主机可以同时访问同一个设备地址了,所以,我们要注意主机和设备的内存竞争——当使用零拷贝内存的时候。
零拷贝内存是固定内存,不可分页。可以通过以下函数创建零拷贝内存:
cudaError_t cudaHostAlloc(void ** pHost,size_t count,unsigned int flags)
这个函数分配了count字节的主机内存,该内存是页面锁定的且设备可访问的。用这个函数分配的内存必须用cudaFreeHost函数释放。
最后一个标志参数,可以选择以下值:
cudaHostAllocDefalt
cudaHostAllocPortable
cudaHostAllocWriteCombined
cudaHostAllocMapped
- cudaHostAllocDefault函数使cudaHostAlloc函数的行为与cudaMallocHost函数一致。
- cudaHostAllocPortable函数返回能被所有CUDA上下文使用的固定内存,而不仅是执行内存分配的那一个。
- cudaHostAllocWriteCombined返回写结合内存,在某些设备上这种内存传输效率更高。
- cudaHostAllocMapped产生零拷贝内存。
注意,零拷贝内存虽然不需要显式的传递到设备上,但是设备还不能通过pHost直接访问对应的内存地址,设备需要访问主机上的零拷贝内存,需要先获得另一个地址,这个地址帮助设备访问到主机对应的内存,方法是:
cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags);
- pDevice就是设备上访问主机零拷贝内存的指针了!该指针可以在设备上被引用以访问映射得到的固定主机内存。
- 此处flag必须设置为0,具体内容后面有介绍。
零拷贝内存可以当做比设备主存储器更慢的一个设备。
频繁的读写,零拷贝内存效率极低,这个非常容易理解,因为每次都要经过PCIe,千军万马堵在独木桥上,速度肯定慢,要是再有人来来回回走,那就更要命了。
float *a_host,*b_host,*res_d;
res_from_gpu_h=(float*)malloc(nByte);
float *a_dev,*b_dev;
CHECK(cudaHostAlloc((float**)&a_host,nByte,cudaHostAllocMapped)); //零拷贝内存
CHECK(cudaHostAlloc((float**)&b_host,nByte,cudaHostAllocMapped));
CHECK(cudaMalloc((float**)&res_d,nByte));
initialData(a_host,nElem);
initialData(b_host,nElem);
CHECK(cudaHostGetDevicePointer((void**)&a_dev,(void*) a_host,0)); // 获取零拷贝内存地址
CHECK(cudaHostGetDevicePointer((void**)&b_dev,(void*) b_host,0));
dim3 block(1024);
dim3 grid(nElem/block.x);
sumArraysGPU<<<grid,block>>>(a_dev,b_dev,res_d);
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte,cudaMemcpyDeviceToHost));
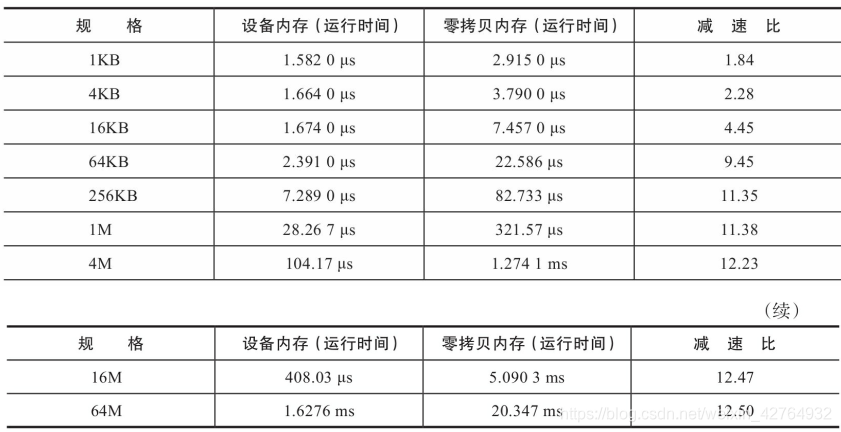
减度比=读取零拷贝内存的运行时间/读取设备内存的运行时间。
如果你想共享主机和设备端的少量数据,零拷贝内存可能会是一个不错的选择,因为它简化了编程并且有较好的性能。
对于由PCIe总线连接的离散GPU上的更大数据集来说,零拷贝内存不是一个好的选择,它会导致性能的显著下降。
有两种常见的异构计算系统架构:集成架构和离散架构。
-
集成架构中,CPU和GPU集成在一个芯片上,并且在物理地址上共享主存。在这种架构中,由于无须在PCIe总线上备份,所以零拷贝内存在性能和可编程性方面可能更佳。
-
离散系统:通过PCIe总线将设备连接到主机。零拷贝内存只在特殊情况下有优势。
因为映射的固定内存在主机和设备之间是共享的,你必须同步内存访问来避免任何潜在的数据冲突,这种数据冲突一般是由多线程异步访问相同的内存而引起的。
注意不要过度使用零拷贝内存。由于其延迟较高,从零拷贝内存中读取设备核函数可能很慢。
4.2.5 统一虚拟寻址
计算能力为2.0及以上版本的设备支持一种特殊的寻址方式,称为统一虚拟寻址(UVA)。UVA,在CUDA 4.0中被引入,支持64位Linux系统。
有了UVA,主机内存和设备内存可以共享同一个虚拟地址空间
在UVA之前,你需要管理哪些指针指向主机内存和哪些指针指向设备内存。有了UVA,由指针指向的内存空间对应用程序代码来说是透明的。
通过UVA,cudaHostAlloc函数分配的固定主机内存具有相同的主机和设备地址,可以直接将返回的地址传递给核函数。
前面的零拷贝内存,可以知道以下几个方面:
分配映射的固定主机内存
使用CUDA运行时函数获取映射到固定内存的设备指针
将设备指针传递给核函数
有了UVA,可以不用上面的那个获得设备上访问零拷贝内存的函数了:
cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags);
UVA来了以后,此函数基本失业了。
float *a_host,*b_host,*res_d;
CHECK(cudaHostAlloc((float**)&a_host,nByte,cudaHostAllocMapped));
CHECK(cudaHostAlloc((float**)&b_host,nByte,cudaHostAllocMapped));
CHECK(cudaMalloc((float**)&res_d,nByte));
res_from_gpu_h=(float*)malloc(nByte);
initialData(a_host,nElem);
initialData(b_host,nElem);
dim3 block(1024);
dim3 grid(nElem/block.x);
sumArraysGPU<<<grid,block>>>(a_host,b_host,res_d);
4.2.6 统一内存寻址
在CUDA 6.0中,引入了“统一内存寻址”这一新特性,它用于简化CUDA编程模型中的内存管理。
统一内存中创建了一个托管内存池,内存池中已分配的空间可以用相同的内存地址(即指针)在CPU和GPU上进行访问。底层系统在统一内存空间中自动在主机和设备之间进行数据传输。 这种数据传输对应用程序是透明的,这大大简化了程序代码。
与UVA统一虚拟寻址区别
UVA为系统中的所有处理器提供了一个单一的虚拟内存地址空间。但是,UVA不会自动将数据从一个物理位置转移到另一个位置。
统一内存寻址可以自动将数据从一个物理位置转移到另一个位置。
与零拷贝内存区别
统一内存寻址提供了一个“单指针到数据”模型,在概念上它类似于零拷贝内存。
但是零拷贝内存在主机内存中进行分配,因此,由于受到在PCIe总线上访问零拷贝内存的影响,核函数的性能将具有较高的延迟。
统一内存寻址将内存和执行空间分离,因此可以根据需要将数据透明地传输到主机或设备上,以提升局部性和性能。
托管内存是指底层系统自动分配的统一内存,未托管内存就是我们自己分配的内存,这时候对于核函数,可以传递给他两种类型的内存,已托管和未托管内存,可以同时传递。
托管内存可以被静态分配也可以被动态分配。
- 可以通过添加
__managed__注释,静态声明一个设备变量作为托管变量。静态声明的托管内存作用域是文件,这一点可以注意一下。
__device__ __managed__ int y;
- 还可以使用下述的CUDA运行时函数动态分配托管内存:
cudaError_t cudaMallocManaged(void ** devPtr,size_t size,unsigned int flags=0)
devPtr指针在所有设备和主机上都是有效的。
使用托管内存的程序行为与使用未托管内存的程序副本行为在功能上是一致的。但是,使用托管内存的程序可以利用自动数据传输和重复指针消除功能。
在CUDA 6.0中,设备代码不能调用cudaMallocManaged函数。所有的托管内存必须在主机端动态声明或者在全局范围内静态声明。

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)