Ubuntu下cuda、cudnn、tensorrt安装及完成推理加速,并使用psmnet和yolov8进行验证
WSL2急速搭建CUDA体验环境_wsl2 cuda-CSDN博客
一.环境要求
1.环境要求
选择Ubuntu为安装系统,我这里采用wsl,双系统同样适用
首先用nvidia-smi查看一下驱动支持情况
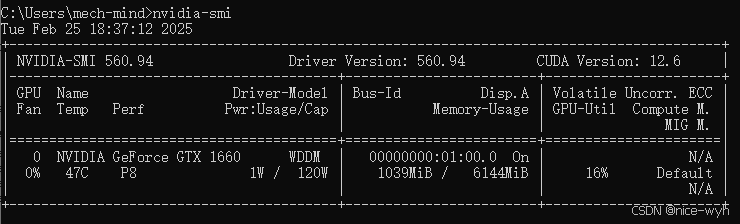
确定最高支持的版本为12.6,所以安装12.6及一下都可以
使用以下稳当版本:
python:3.8
conda create -n tensorrt python=3.8tensorrt:8.5.1.7
pycuda:2022.1
pip install pycuda==2022.1torch 2.4.1+cu118/2.3.1+cu118
torchaudio 2.4.1+cu118/2.3.1+cu118
torchvision 0.19.1+cu118/0.18.1+cu118pip install torch==2.4.1+cu118
pip install torchvision==0.19.1+cu118 torchaudio==2.4.1+cu118 --index-url https://download.pytorch.org/whl/cu118如果之前安装过cuda、cudnn、tensorrt,需要先进行卸载
2.cuda卸载
sudo apt-get --purge remove "*cuda*" "*cublas*" "*cufft*" "*cufile*" "*curand*" \
"*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*"
sudo apt-get autoremove3.cudnn卸载
sudo apt-get purge libcudnn8
sudo apt-get purge libcudnn8-dev
# or
sudo apt-get --purge remove "*cublas*" "*cufft*" "*curand*" "*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "cuda*" "nsight*"
cd /usr/local/cuda-xx.x/bin/
sudo ./cuda-uninstaller
sudo rm -rf /usr/local/cuda-xx.x4.tensorrt卸载命令(因为有可能下载python对用的tensorrt,所以会有pip的卸载)
sudo apt-get purge "libnvinfer*"
sudo apt-get purge "nv-tensorrt-repo*"
sudo apt-get purge graphsurgeon-tf onnx-graphsurgeon
pip3 uninstall tensorrt
pip3 uninstall uff
pip3 uninstall graphsurgeon
pip3 uninstall onnx-graphsurgeon
python3 -m pip uninstall nvidia-tensorrt二.安装cuda
在确定了安装的CUDA版本后,比如上文确定的CUDA 11.8,就可以进入CUDA下载界面
https://developer.nvidia.com/cuda-toolkit-archive
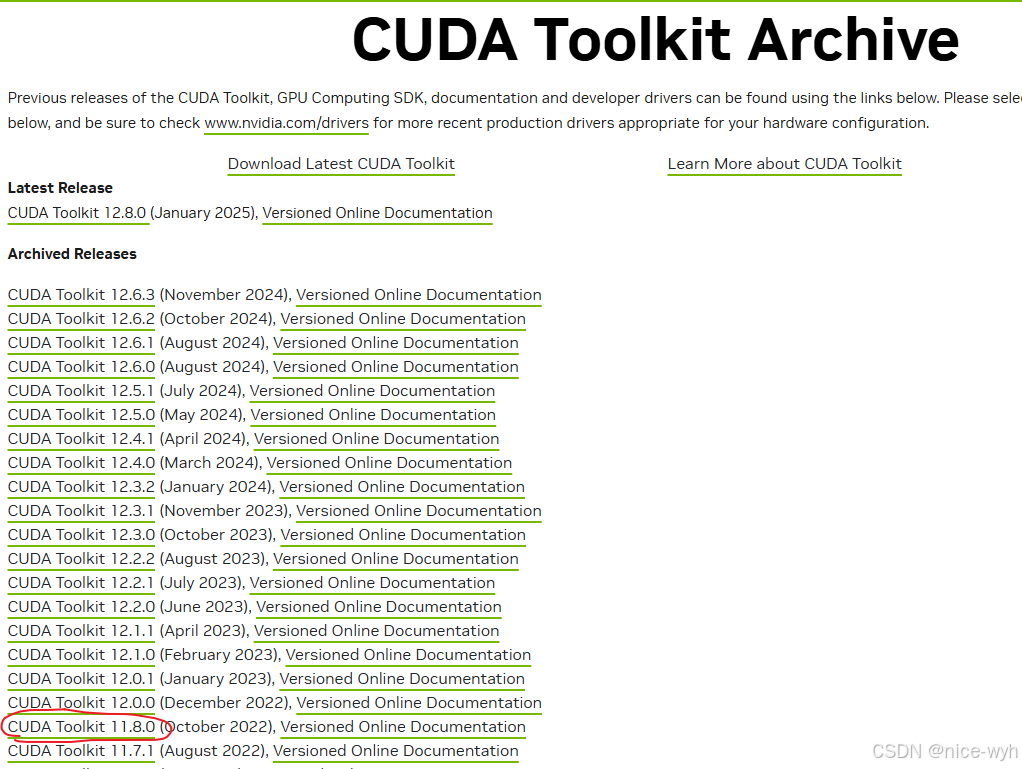
选择11.8版本,之后选择deb的安装方式,按照官网教程,依次输入以下指令
sudo wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-wsl-ubuntu-11-8-local_11.8.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-11-8-local_11.8.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
完成之后可以看到/usr/local下出现了安装好的cuda

之后在bashrc中的最下面加入如下内容
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH之后source ~/.bashrc,再使用nvcc -v查看是否安装成功
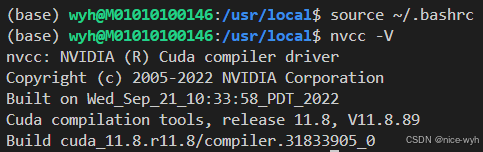
到此,完成了cuda11.8的安装
三.安装cudnn
进入cuDNN Download界面https://developer.nvidia.com/rdp/cudnn-archive
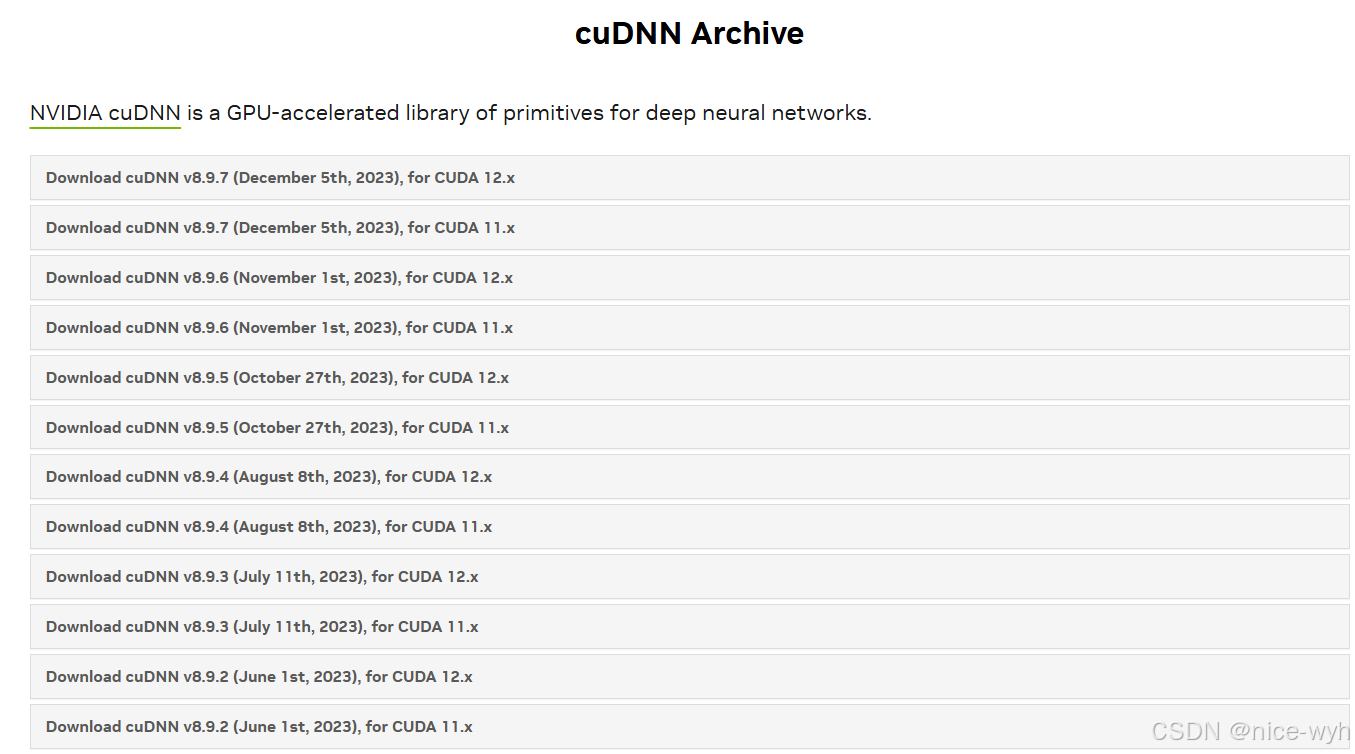
因为要安装的版本是8.7.0,所以在下面找到对应版本,这里选择tar安装
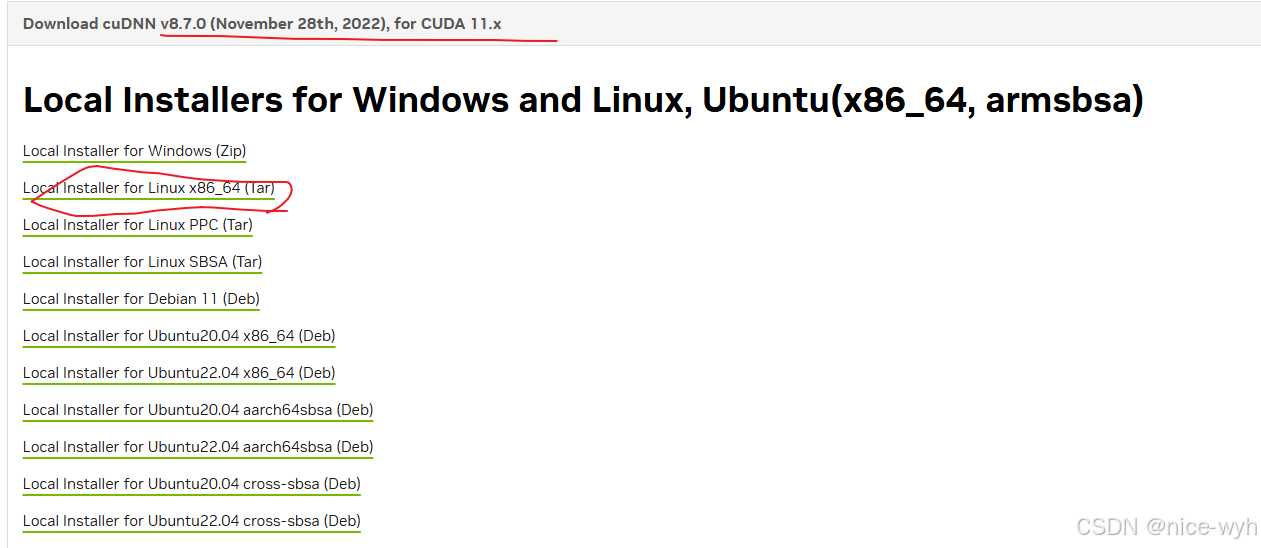
之后执行指令
tar -xvf cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
验证是否安装成功,输入如下命令,显示如下图即安装成功

四.安装TensorRT
TensorRT选择对应的tar包进行安装
进入到TensorRT官方下载网址Log in | NVIDIA Developer,点击勾选I agree
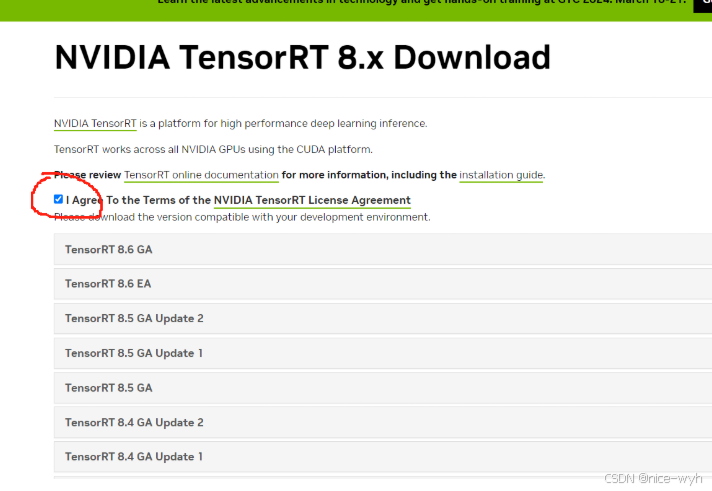
选择8.5 GA,注意到越网上对应的cuda版本越高,CUDA 11.8在8.5GA上可以找到
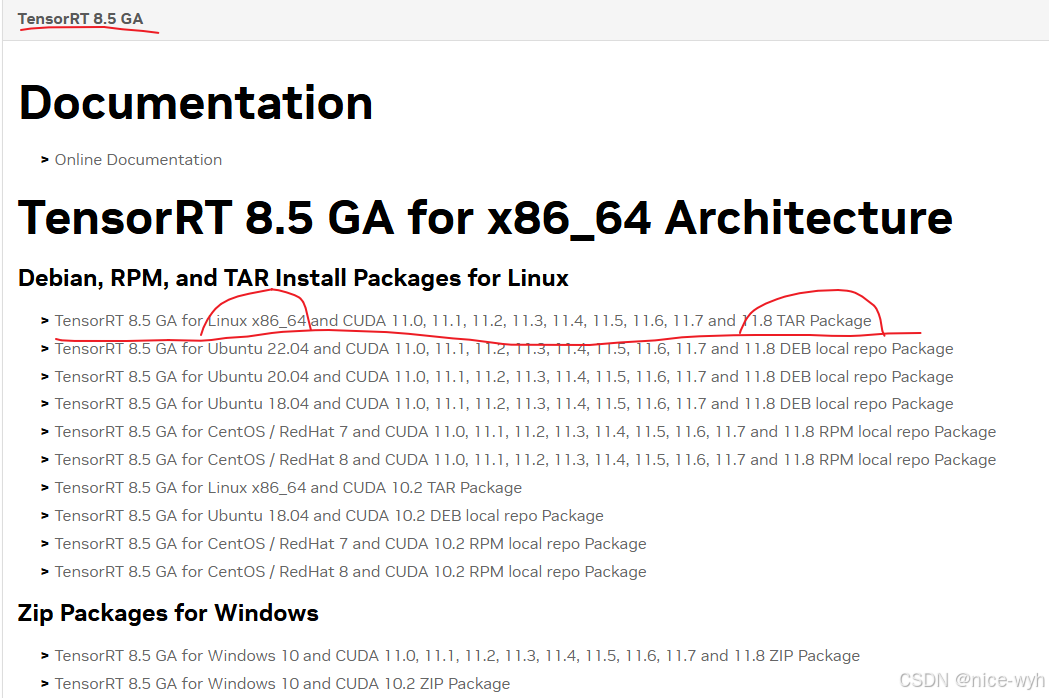
将下载后的tar包复制到ubuntu的一个文件夹下,本文是home/用户名下的Downloads,最后通过解压安装,然后进行配置即可。安装完成后会出现TensorRT-(版本)的文件夹,这里我们已经安装好了,然后进行解压缩
tar -xzvf TensorRT-8.5.1.7.Linux.x86_64-gnu.cuda-11.8.cudnn8.6.tar
之后可以看到解压缩之后的文件夹了
将TensorRT 下的lib绝对路径添加到系统环境中(根据自己的安装目录来)
export TRT_DIR=/mnt/d/TensorRT-8.5.1.7
export PATH=$PATH:$TRT_DIR/bin
export LD_LIBRARY_PATH=/mnt/d/TensorRT-8.5.1.7/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=$LIBRARY_PATH:$TRT_DIR/lib
export CPATH=$CPATH:$TRT_DIR/include然后surce ~/.bashrc,到此我们应该可以使用我们的trtexec工具了,这是一个可以把onnx文件转换成engine文件的工具,使用下面的指令即可
trtexec --onnx=best.onnx --saveEngine=best.engine --fp16切换到python目录下,安装tensorrt python whl文件
注意:这里的pip安装一定是下载到自己的虚拟环境下,比如anaconda下pytorch环境激活后
根据当前环境的python版本安装对应的tensorrt, 我的当前环境python为3.8,就安装3.8对应的tensorrt whl文件(whl文件在对应的路径为/mnt/d/TensorRT-8.5.1.7/python)
直接使用离线包安装即可
conda activate tensorrt
pip install tensorrt-8.5.1.7-cp38-none-linux_x86_64到此,环境基本安装完成,虚拟环境下主要的包版本为
Package Version
------------------------ ------------
appdirs 1.4.4
certifi 2025.1.31
charset-normalizer 3.4.1
coloredlogs 15.0.1
contourpy 1.1.1
cycler 0.12.1
filelock 3.13.1
flatbuffers 25.2.10
fonttools 4.56.0
fsspec 2024.6.1
humanfriendly 10.0
idna 3.10
importlib_resources 6.4.5
Jinja2 3.1.4
kiwisolver 1.4.7
Mako 1.3.9
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.7.5
mdurl 0.1.2
mpmath 1.3.0
networkx 3.0
numpy 1.24.4
nvidia-cublas-cu11 11.11.3.6
nvidia-cuda-cupti-cu11 11.8.87
nvidia-cuda-nvrtc-cu11 11.8.89
nvidia-cuda-runtime-cu11 11.8.89
nvidia-cudnn-cu11 9.1.0.70
nvidia-cufft-cu11 10.9.0.58
nvidia-curand-cu11 10.3.0.86
nvidia-cusolver-cu11 11.4.1.48
nvidia-cusparse-cu11 11.7.5.86
nvidia-nccl-cu11 2.20.5
nvidia-nvtx-cu11 11.8.86
onnx 1.17.0
onnx-simplifier 0.4.36
onnxruntime-gpu 1.19.2
opencv-python 4.11.0.86
packaging 24.2
pandas 2.0.3
pillow 10.2.0
pip 24.2
platformdirs 4.3.6
protobuf 5.29.3
psutil 7.0.0
py-cpuinfo 9.0.0
pycuda 2022.1
Pygments 2.19.1
pyparsing 3.1.4
python-dateutil 2.9.0.post0
pytools 2024.1.14
pytz 2025.1
PyYAML 6.0.2
requests 2.32.3
rich 13.9.4
scipy 1.10.1
seaborn 0.13.2
setuptools 75.1.0
six 1.17.0
sympy 1.13.1
tensorrt 8.5.1.7
torch 2.4.1+cu118
torchaudio 2.4.1+cu118
torchvision 0.19.1+cu118
tqdm 4.67.1
triton 3.0.0
typing_extensions 4.12.2
tzdata 2025.1
ultralytics 8.3.78
ultralytics-thop 2.0.14
urllib3 2.2.3
wheel 0.44.0
zipp 3.20.2五.使用TensorRT进行推理加速
主要流程如下:将训练好的模型文件转换成onnx----使用trtexec工具将onnx转换成engine文件用于推理----编写推理代码完成部署加速
1.tar2onnx
我在这里拿psmnet网络训练的双目视差估计网络进行试验,网络训练完输出权重文件为checkpoint.tar,我的tra2onnx.py文件内容如下
import torch
import torch.nn as nn
from models import *
import sys
model = stackhourglass(disp_min=416, disp_max=528)
model = nn.DataParallel(model)
state_dict = torch.load("checkpoint.tar", map_location='cpu', weights_only=True)
model.load_state_dict(state_dict['state_dict'])
model.eval()
dummy_input_L = torch.randn(1, 3, 720, 960).cuda()
dummy_input_R = torch.randn(1, 3, 720, 960).cuda()
with torch.no_grad():
torch.onnx.export(
model.module,
(dummy_input_L, dummy_input_R),
"psmnet.onnx",
input_names=["left", "right"],
output_names=["output"],
export_params = True,
keep_initializers_as_inputs=True,
opset_version=11,
do_constant_folding=True,
)
print("ONNX model exported successfully!")
2.onnx2engine
原则上使用trtexec工具是肯定没问题的(这里要注意要在同一个环境下执行此操作,我之前在windows端使用trtexec导出engine文件,在ubuntu端进行部署是有问题的)
trtexec --onnx=psmnet.onnx --saveEngine=psmnet.engine --fp16在这之后,我又写了一个Python脚本进行转化,目前只在fp32精度下测试成功,代码如下
import onnx
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import os
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# fp32精度
def onnx_to_engine(onnx_model_path, engine_path):
builder = trt.Builder(TRT_LOGGER)
network_flags = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
network = builder.create_network(network_flags)
onnx_parser = trt.OnnxParser(network, TRT_LOGGER)
with open(onnx_model_path, "rb") as f:
if not onnx_parser.parse(f.read()):
print("Error parsing ONNX model")
for error in range(onnx_parser.num_errors):
print(onnx_parser.get_error(error))
return None
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30)
serialized_engine = builder.build_serialized_network(network, config)
if serialized_engine is None:
print("Failed to build TensorRT engine.")
return None
with open(engine_path, "wb") as f:
f.write(serialized_engine)
print(f"Engine saved at: {engine_path}")
# fp16精度
def onnx_to_engine(onnx_model_path, engine_path, fp16=True):
builder = trt.Builder(TRT_LOGGER)
network_flags = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
network = builder.create_network(network_flags)
onnx_parser = trt.OnnxParser(network, TRT_LOGGER)
with open(onnx_model_path, "rb") as f:
if not onnx_parser.parse(f.read()):
print("Error parsing ONNX model")
for error in range(onnx_parser.num_errors):
print(onnx_parser.get_error(error))
return None
config = builder.create_builder_config()
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30)
if fp16 and builder.platform_has_fast_fp16:
print("Enabling FP16 precision...")
config.set_flag(trt.BuilderFlag.FP16)
serialized_engine = builder.build_serialized_network(network, config)
if serialized_engine is None:
print("Failed to build TensorRT engine.")
return None
with open(engine_path, "wb") as f:
f.write(serialized_engine)
print(f"FP16={fp16}: Engine saved at {engine_path}")
def load_engine(engine_path):
runtime = trt.Runtime(TRT_LOGGER)
with open(engine_path, "rb") as f:
engine_data = f.read()
return runtime.deserialize_cuda_engine(engine_data)
def run_inference(engine, imgL, imgR):
context = engine.create_execution_context()
# 获取输入/输出 tensor 名称
input_binding_name_L = engine.get_tensor_name(0)
input_binding_name_R = engine.get_tensor_name(1)
output_binding_name = engine.get_tensor_name(2)
input_shape_L = engine.get_binding_shape(0)
input_shape_R = engine.get_binding_shape(1)
output_shape = engine.get_binding_shape(2)
# 分配 GPU 内存
d_input_L = cuda.mem_alloc(imgL.nbytes)
d_input_R = cuda.mem_alloc(imgR.nbytes)
d_output = cuda.mem_alloc(trt.volume(output_shape) * np.dtype(np.float32).itemsize)
stream = cuda.Stream()
bindings = [int(d_input_L), int(d_input_R), int(d_output)]
# 拷贝数据到 GPU
cuda.memcpy_htod(d_input_L, imgL)
cuda.memcpy_htod(d_input_R, imgR)
context.execute_v2(bindings=bindings)
output_data = np.empty(output_shape, dtype=np.float32)
cuda.memcpy_dtoh_async(output_data, d_output, stream)
stream.synchronize()
return output_data
onnx_model_path = "psmnet.onnx"
engine_path = "psmnet_online.engine"
if not os.path.exists(engine_path):
# fp32精度
onnx_to_engine(onnx_model_path, engine_path)
# # # fp16精度
# onnx_to_engine(onnx_model_path, engine_path, True)
3.Test_trt
最后需要做的就是进行部署,仿照官方直接使用模型进行推理的代码,修改的完整代码如下
from __future__ import print_function
import argparse
import json
import sys
import os
import random
import re
import cv2
import numpy as np
import math
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import time
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
parser = argparse.ArgumentParser(description='PSMNet')
parser.add_argument('--leftimgs', default= './VO04_L.png',
help='load model')
parser.add_argument('--rightimgs', default= './VO04_R.png',
help='load model')
parser.add_argument('--disp_trues', default= './VO04_disp.pfm',
help='load model')
parser.add_argument('--loadmodel', default='./psmnet16.engine',
help='loading model')
parser.add_argument('--disp_min', type=int ,default=416,
help='minimum disparity')
parser.add_argument('--disp_max', type=int ,default=528,
help='maxium disparity')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='enables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
def load_engine(trt_runtime, engine_path):
with open(engine_path, "rb") as f:
engine_data = f.read()
return trt_runtime.deserialize_cuda_engine(engine_data)
def test_trt(imgL, imgR, engine, context, d_input_L, d_input_R, d_output):
imgL = np.ascontiguousarray(imgL.cpu().numpy(), dtype=np.float32)
imgR = np.ascontiguousarray(imgR.cpu().numpy(), dtype=np.float32)
# **提前创建 Stream**(用于异步数据传输)
stream = cuda.Stream()
bindings = [int(d_input_L), int(d_input_R), int(d_output)]
cuda.memcpy_htod_async(d_input_L, imgL, stream)
cuda.memcpy_htod_async(d_input_R, imgR, stream)
stream.synchronize()
success = context.execute_v2(bindings=bindings)
if not success:
raise RuntimeError("TensorRT inference failed!")
# **异步拷贝回 Host**
output_data = np.empty(engine.get_binding_shape(2), dtype=np.float32)
cuda.memcpy_dtoh_async(output_data, d_output, stream)
stream.synchronize()
return np.squeeze(output_data)
def read_pfm_wo_flip(file):
with open(file, 'rb') as f:
header = f.readline().decode('utf-8').rstrip()
if header == 'PF':
color = True
elif header == 'Pf':
color = False
else:
raise Exception('Not a PFM file.')
dim_match = re.match(r'^(\d+)\s(\d+)\s$', f.readline().decode('utf-8'))
if dim_match:
width, height = map(int, dim_match.groups())
else:
raise Exception('Malformed PFM header.')
scale = float(f.readline().decode('utf-8').rstrip())
if scale < 0: # little-endian
endian = '<'
scale = -scale
else: # big-endian
endian = '>'
# Read the data
data = np.fromfile(f, endian + 'f')
shape = (height, width, 3) if color else (height, width)
return np.reshape(data, shape), scale
def colorize_diff(estimated, ground_truth, cmap='viridis', output_file='disparity_diff.png'):
# Calculate the absolute difference between the estimated and ground truth disparities
diff = np.abs(estimated - ground_truth)
# Normalize the difference for better visualization
norm_diff = (diff - diff.min()) / (diff.max() - diff.min())
# Create a colorized image using a colormap
colorized_diff = cm.get_cmap(cmap)(norm_diff) # Get colorized image from colormap
# Save the colorized image as a PNG file
plt.imsave(output_file, colorized_diff)
return colorized_diff
def save_pfm(filename, image, scale=1):
if image.dtype != np.float32:
raise ValueError('Image dtype must be float32.')
if len(image.shape) == 2:
color = False
elif len(image.shape) == 3 and image.shape[2] == 3:
color = True
else:
raise ValueError('Image must be a HxW or HxWx3 array.')
file = open(filename, 'wb')
if color:
file.write(b'PF\n')
else:
file.write(b'Pf\n')
file.write(f'{image.shape[1]} {image.shape[0]}\n'.encode())
endian = image.dtype.byteorder
if endian == '<' or endian == '=' and np.little_endian:
scale = -scale
file.write(f'{scale}\n'.encode())
image.tofile(file)
file.close()
def inference_trt(leftimg, rightimg, disp_true, idx, engine, context, d_input_L, d_input_R, d_output):
normal_mean_var = {'mean': [0.485, 0.456, 0.406],
'std': [0.229, 0.224, 0.225]}
infer_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(**normal_mean_var)])
imgL_o = Image.open(leftimg).convert('RGB')
imgR_o = Image.open(rightimg).convert('RGB')
disp_true, _ = read_pfm_wo_flip(disp_true)
mask = np.logical_or(disp_true >= args.disp_max, disp_true <= args.disp_min)
valid_mask = (disp_true < args.disp_max) & (disp_true > args.disp_min)
imgL = infer_transform(imgL_o)
imgR = infer_transform(imgR_o)
# pad to width and hight to 16 times
if imgL.shape[1] % 16 != 0:
times = imgL.shape[1]//16
top_pad = (times+1)*16 -imgL.shape[1]
else:
top_pad = 0
if imgL.shape[2] % 16 != 0:
times = imgL.shape[2]//16
right_pad = (times+1)*16-imgL.shape[2]
else:
right_pad = 0
imgL = F.pad(imgL,(0,right_pad, top_pad,0)).unsqueeze(0)
imgR = F.pad(imgR,(0,right_pad, top_pad,0)).unsqueeze(0)
start_time = time.time()
pred_disp = test_trt(imgL, imgR, engine, context, d_input_L, d_input_R, d_output)
print('time = %.2f' %(time.time() - start_time))
output_folder = "test_output"
if not os.path.exists(output_folder):
os.makedirs(output_folder, exist_ok=True)
pred_disp[mask] = 0
save_pfm(os.path.join(output_folder, "test_disparity_{}.pfm".format(idx)), pred_disp)
# save_pfm("test_disparity.pfm", disp)
if top_pad !=0 and right_pad != 0:
img = pred_disp[top_pad:,:-right_pad]
elif top_pad ==0 and right_pad != 0:
img = pred_disp[:,:-right_pad]
elif top_pad !=0 and right_pad == 0:
img = pred_disp[top_pad:,:]
else:
img = pred_disp
img[mask] = 0
epe = np.mean(np.abs(img[valid_mask]-disp_true[valid_mask]))
print( "EPE=%.3f" % (epe))
colorize_diff(img, disp_true, output_file=os.path.join(output_folder, "disparity_diff_{}.png".format(idx)))
img = (img*256).astype('uint16')
img = Image.fromarray(img)
img.save(os.path.join(output_folder, 'Test_disparity_{}.png'.format(idx)))
return epe
def test_all(engine, context):
# left_files = sorted([os.path.join(args.leftimgs, filename) for filename in os.listdir(args.leftimgs)])
# right_files = sorted([os.path.join(args.rightimgs, filename) for filename in os.listdir(args.rightimgs)])
# disp_files = sorted([os.path.join(args.disp_trues, filename) for filename in os.listdir(args.disp_trues)])
left_files = sorted([os.path.join("./left/", filename) for filename in os.listdir("./left/")])
right_files = sorted([os.path.join("./right/", filename) for filename in os.listdir("./right/")])
disp_files = sorted([os.path.join("./pfm/", filename) for filename in os.listdir("./pfm/")])
# 获取输入/输出 shape
input_shape_L = engine.get_binding_shape(0)
input_shape_R = engine.get_binding_shape(1)
output_shape = engine.get_binding_shape(2)
# **提前分配 GPU 内存**
d_input_L = cuda.mem_alloc(trt.volume(input_shape_L) * np.dtype(np.float32).itemsize)
d_input_R = cuda.mem_alloc(trt.volume(input_shape_R) * np.dtype(np.float32).itemsize)
d_output = cuda.mem_alloc(trt.volume(output_shape) * np.dtype(np.float32).itemsize)
print(left_files)
print(right_files)
print(disp_files)
avg_epe = 0
for idx in range(len(left_files)):
avg_epe += inference_trt(left_files[idx], right_files[idx], disp_files[idx], idx, engine, context, d_input_L, d_input_R, d_output)
avg_epe = avg_epe / len(left_files)
print( "AVG_EPE=%.3f" % (avg_epe))
if __name__ == '__main__':
model_file = args.loadmodel
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
engine = load_engine(trt_runtime, model_file)
if engine is None:
raise ValueError("Failed to load TensorRT engine!")
context = engine.create_execution_context()
test_all(engine, context)
# 释放
del context
del engine
torch.cuda.empty_cache()
参考链接:
WSL2急速搭建CUDA体验环境_wsl2 cuda-CSDN博客
【保姆级教程】Windows安装CUDA及cuDNN_windows安装cudnn-CSDN博客
深度学习环境-CUDA和CUDNN的安装与卸载-WSL2子系统篇 - 53AI-AI生产力的卓越领导者(大模型知识库|大模型训练|智能体开发)
win11 WSL ubuntu安装CUDA、CUDNN、TensorRT最有效的方式_wsl安装cudnn-CSDN博客

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)