免费报名|来「2025 智源大会」特色活动 Tech Tutorial,聆听一线技术大牛面授公开课
2025年6月6日-7日,第 7 届北京智源大会将以“线上线下双联动”的形式在北京中关村国家自主创新示范区展示中心举办。本次大会将汇聚多位图灵奖得主、海内外顶尖机构学者与产业领袖,在思辨与实证的交织中,为 AI 的未来绘制航图。
为满足观众的多样化需求,本次大会设有 20+ 专题论坛、近 10+ 场 AI 开源项目 Tech Tutorial、超大 AI 互动体验区等精彩环节。创新开设的 AI 开源项目 Tech Tutorial 系列活动,由一线技术大咖领衔带队,从模型、数据、算法、软件系统等多个方向体系化介绍相关 AI 开源项目,包括一站式大模型开源基座平台、多元算力大模型分布式训练、多芯片推理部署、训推一体开源框架、统一通信库、开源统一 AI 编译器、AI 高性能算子库等干货分享,面向开发者详解相关技术细节,呈现一场兼具理论指导和实操性的技术交流盛宴。
Tech Tutorial 1
《技术大揭秘:大模型训推框架 FlagScale 与统一通信库 FlagCX 技术详解》

演讲 1《多元算力大模型分布式训练技术实践与创新》
内容摘要:围绕 FlagScale 框架在大模型训练中的关键实践展开,涵盖高效复现 DeepSeekV3、自动容错与异构加速三大话题。首先,介绍如何基于 FlagScale 与 OpenSeek 开源社区协作,快速复现 DeepSeekV3 模型,充分利用其分布式能力与模块化训练流水线。其次,聚焦分布式 Checkpointing 与容错机制展示如何在大规模训练中实现自动容错与训练恢复,从而提升训练稳定性和资源利用率。最后,探讨通用异构硬件下的混合并行训练策略,包括不同硬件间如何协同降低算力损耗、如何支持任意多异构芯片混合训练,以及端到端异构训练在生产环境中的部署经验。这些探索,我们希望为大模型训练提供更高效、稳定、灵活的系统解决方案。
演讲大纲
1. 基于 FlagScale 高效复现 DeepSeek-V3
1.1 与 OpenSeek 开源社区合作,复现 DeepSeek 模型结构与系统框架相关优化
1.2 Dualpipe 调度高效实现
2. 基于分布式 Checkpoint 的端到端高效自动容错与分布式训练
2.1 Distributed Checkpointing 应用与实践
2.2 基于自动容错的故障恢复
3. 通用异构硬件混合分布式训练
3.1 通用异构硬件混合训练设计
3.2 端到端异构硬件混合训练
观众收益
1. 复现 DeepSeek-V3 关键技术与性能优化
2. 基于 Distributed Checkpointing 技术的分布式训练自动容错技术实践
3. 基于 FlagScale 的异构混训的技术原理
4. 基于 FlagScale 的异构混训实践
演讲 2《基于 FlagScale 自动调优机制,进行多芯片高效推理部署》
内容摘要:本演讲将深入探讨 FlagScale 在多芯片推理部署领域的核心技术与落地实践。针对当前 AI 大模型部署面临的算力多样化挑战,FlagScale 提供了一套完整的解决方案:1)提供跨芯片一键部署能力,在不同芯片上可以丝滑实现部署能力迁移;2)智能化的资源自动调优机制,针对不同芯片不同模型自动找到最优的部署配置;3)异构PD分离部署,突破单一硬件限制。结合自动调优功能,系统能够智能选择最优异构资源组合,并完成动态负载均衡与性能优化,实现计算资源利用率的大幅提升。
演讲大纲
1. FlagScale 多芯片推理部署
1.1 在英伟达芯片上进行一键部署
1.2 一键部署流程迁移到其他国产芯片
2. 基于 FlagScale 自动调优机制进行高效部署
2.1 FlagScale 自动调优功能
2.2 基于 FlagScale 进行异构 PD 分离部署
2.3 基于自动调优功能对异构 PD 分离资源进行自动选择和性能调优
观众收益
1. 跨芯片高效部署
2. 不同部署配置对模型性能的影响
3. PD异构分离部署资源分配和调优
演讲 3《基于 FlagCX 打造多框架+多芯片高效跨芯通信能力》
内容摘要:本次演讲将深入探讨 FlagCX 在多芯通信领域的核心技术与落地实践。针对多元算力时代带来的异构通信性能和通用性挑战,FlagCX 提供了一套完整的解决方案:1)提供同构模式“零开销”厂商通信库分发机制,统一通信接口;2)提供异构模式高性能跨芯 P2P 和 Collective 通信操作和服务器级自动拓扑探测功能,最大化利用网卡带宽,实现跨芯高效互联;3)提供多框架集成能力,目前已支持 PyTorch 和 PaddlePaddle,并实现基于 FlagScale + FlagCX 的端到端异构混训。
演讲大纲
1. FlagCX 的“零开销”适配器设计,实现一套通信接口下发多种厂商通信库
1.1 多后端适配器设计
1.2 基于 FlagCX 在多种芯片上实现一键编译+单机同构通信测试
2. FlagCX 的跨芯通信设计和实践
2.1 跨芯 P2P 通信和跨芯 C2C 集合通信设计
2.2 基于 FlagCX 在混芯环境实现跨芯高效通信
3. FlagCX 的多框架集成和异构混训能力
3.1 FlagCX 多框架集成现状介绍
3.2 基于 FlagScale + FlagCX 实现端到端异构混训
观众收益
1. FlagCX 的跨芯通信技术方案
2. FlagCX 跨芯通信在不同网络环境下的性能表现
3. FlagScale + FlagCX 的异构混训实践
演讲4 《FlagScale 多后端管理与多硬件适配机制》
内容摘要:FlagScale 是联合了生态伙伴完全基于开源技术构建的面向多种芯片的大模型端到端框架。通过提供模型开发、训练和部署等关键组件,FlagScale致力于成为优化大型模型工作流程效率与效果的必备开源工具包。针对当前多硬件和多后端的使用复杂挑战,FlagScale 提供了可扩展的多后端管理机制与灵活的多硬件适配机制,本次演讲将深入介绍 FlagScale 在多后端管理与多硬件适配上的设计思路、工程实现及实际应用案例,分享如何实现后端的灵活切换、以及多芯片如何快速适配,助力开发者在多样化计算环境中高效落地不同芯片的大模型解决方案。
演讲大纲
1. FlagScale 多后端管理机制
1.1 后端管理机制的架构设计
1.2 后端的使用与二次开发流程
2. FlagScale 多硬件适配机制
2.1 新硬件适配与接入机制的设计
2.2 在国产芯片上的落地与使用实践
观众收益
1. 如何高效管理与接入不同后端
2. 如何快速在新硬件上实现 FlagScale 的适配与支持
3. 如何在不同硬件架构中高效使用 FlagScale
Tech Tutorial 2
《实战训练:Triton 算子开发与编译器技术详解》
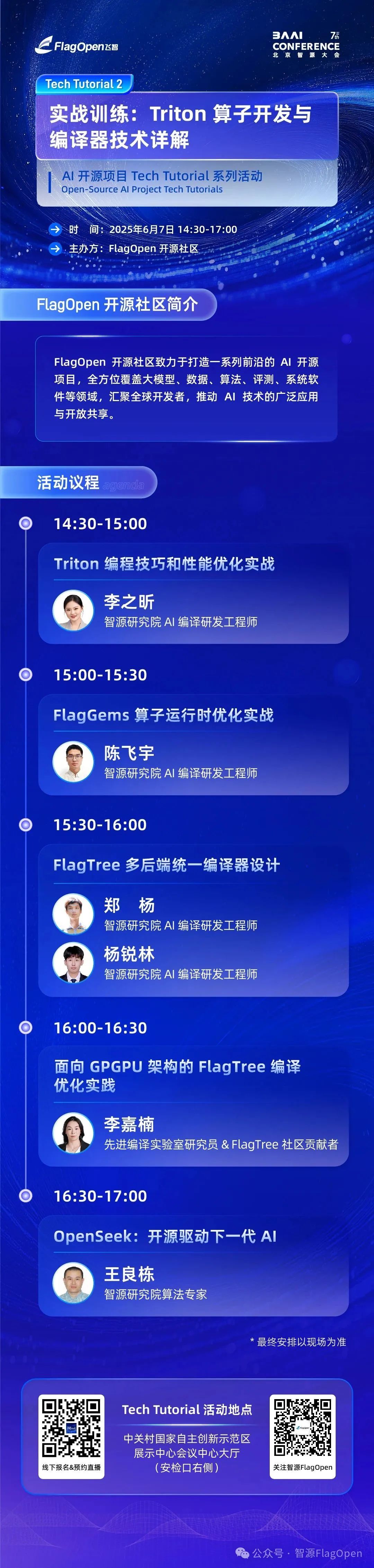
演讲 1《 Triton 编程技巧和性能优化实战》
内容摘要:本次分享将依托 FlashMLA 的技术改良,介绍 Triton 的编程技巧与性能优化实践。DeepSeek_V3 重磅开源以来,全新推出的注意力机制 FlashMLA 受到广泛关注,它的计算效率成为 DeepSeek 模型推理的重点问题。为了提供高性能、易迁移的 FlashMLA 算法,FlagGems 在早期版本的基础上,深入研究 Triton 语言特性,结合硬件架构特点,通过精细化的内存管理、并行计算策略优化,大幅提升了 FlashMLA 的执行效率。实测数据显示,FlashMLA 在 FlagGems 中的版本实现了性能提升,在多元芯片平台上效果尤为显著,为 Triton 语言在大模型推理优化领域的应用提供了可供参考的实践范例。
演讲大纲
1. FlashMLA 的 Triton 实现
1.1 FlashMLA 算法逻辑
1.2 FlashMLA 与普通 FA 的差异
1.3 Triton 的初步实现
2. FlashMLA 的性能优化
2.1 分块策略的比较与解析
2.2 读写指令的优化空间
2.3 其他的优化思考和尝试
观众收益
1. 理解热点算法 Flash-Multi-Latent-Attention 的原理
2. 认识 Triton 常用的性能优化模式
3. 探索 Triton 编程原语的使用技巧
演讲 2《FlagGems 算子运行时优化实战》
内容摘要:FlagGems 算子应用到模型训练与推理时,Triton 语言的 python 基础环境与即时编译特征易造成运行时开销较高,导致端到端的计算耗时无法从 FlagGems 编写的高性能 kernel 中获益。为提升模型训推效率,高性能通用 AI 算子库 FlagGems 推出了一系列新特性对运行时进行优化,提升算子在模型中的性能表现。本次分享中,我们聚焦 FlagGems 算子运行时优化技术方案,通过 cpp extension 机制解决 python wrapper 的效率缺陷。
演讲大纲
Triton 算子的 python wrapper 开销问题
Triton JIT 运行时分析
Triton JIT C++ 运行时设计
C++ wrapper 开发实践
观众收益
1. Python-like 语言写 kernel 是用户喜闻乐见的,但代价是 python 的运行时开销
2. 通过 Triton JIT c++ 运行时,可以在 c++ 中使用 triton, 实现 ffi
3. 使用 C++ 来写 wrapper,可以很大程度减少 cpu 开销
演讲 3 《 FlagTree 多后端统一编译器设计》
内容摘要:演讲以接入及优化 Triton 算子编译器软件生态为主题 ,介绍面向多元 AI 硬件的开源、统一编译器生态FlagTree 项目的设计范式。以增强的硬件表达能力为中心,解决当前 Triton 面临的对多后端支持有限、不同硬件在 ttir 和 ttgir 之间发散出多种编译路线等问题。FlagTree 以统一的硬件抽象架构,开放的硬件集成等特性,构建真正统一的代码仓库,为上层用户提供一站式的 Triton 支持,同时为算子库、算法开发形成统一的编译器依赖。
演讲大纲
1. FlagTree 顶层设计范式
1.1 AI 硬件设备接入架构
1.2 优化层级
1.2.1 Triton 当前面临的问题
1.2.2 hint 设计的整体模块和流程以加入 npu 的 shared mem 作为 case study
2. 愿景:谈一下我们要优化到什么程度,想做到什么样的生态和影响力
观众收益
1. 如何接入 Triton 算子编译器软件生态
2. 以 hint 为形式的编译指导信息传递方法
演讲 4 《面向 GPGPU 架构的 FlagTree 编译优化实践》
内容摘要:本演讲将深入解析 FlagTree 在 GPGPU 上的编译优化实践。首先介绍 FlagTree 的核心组成与优化遍管理机制,展示如何灵活扩展编译优化流程。随后介绍 FlagTree 编译优化的实战经验,包括结合具体案例分析配置策略优化在性能调优中的作用,改进访存合并、代码生成、TensorCore 矩阵乘加速优化,以及新增代数变换策略。旨在帮助开发者高效地利用 FlagTree 释放 GPGPU 的计算潜能,为 GPGPU 适配 FlagTree 提供技术指导和实践借鉴。
演讲大纲
1. FlagTree 核心组成
1.1 框架简介
1.2 优化遍管理
1.3 优化遍添加
2. FlagTree 编译优化
2.1 配置策略优化
2.2 访存合并优化
2.3 代码生成优化
2.4 TensorCore 优化
2.5 代数变换优化
观众收益
大家将了解 FlagTree 在 GPGPU 架构上的优化原理与实践经验,获得编译优化遍的添加方法和配置优化策略,同时掌握包括访存合并、代码生成、TensorCore 利用、代数变换等在内的关键技术,为其在深度学习编译器开发、高性能算子实现和 GPGPU 性能提升等方面提供技术指导和实践借鉴。
演讲 5《OpenSeek:开源驱动下一代AI》
内容摘要:开源项目 OpenSeek 旨在联合全球开源社区,推动算法、数据和系统的协同创新,开发出超越 DeepSeek 的下一代模型。 该项目从 Bigscience 和 OPT 等大模型计划中汲取灵感,致力于构建一个开源自主的算法创新体系。 自 DeepSeek 模型开源以来,学术界涌现出众多算法改进和突破,但这些创新往往缺乏完整的代码实现、必要的计算资源和高质量的数据支持。OpenSeek 项目期望通过联合开源社区,探索高质量数据集构建机制,推动大模型训练全流程的开源开放,构建创新的训练和推理代码以支持多种 AI 芯片,促进自主技术创新和应用发展。
演讲大纲
1. OpenSeek 整体概述
2. 系统工作组
2.1 DeepSeek 主要系统特性
2.2 OpenSeek 目标和进展
3. 数据工作组
3.1 DeepSeek 数据特点
3.2 OpenSeek 数据集 CCI4.0
4. 算法工作组
4.1 算法工作组进展
4.2 OpenSeek-Small V1 进展
观众收益
1. 系统化呈现 CCI4.0 中英双语数据集的构建全流程
2. 探索适用于小尺寸稀疏专家模型的高效训练策略
3. 开源参与者可通过协作优化数据集、训练策略及模型结构,共同推动模型性能提升。
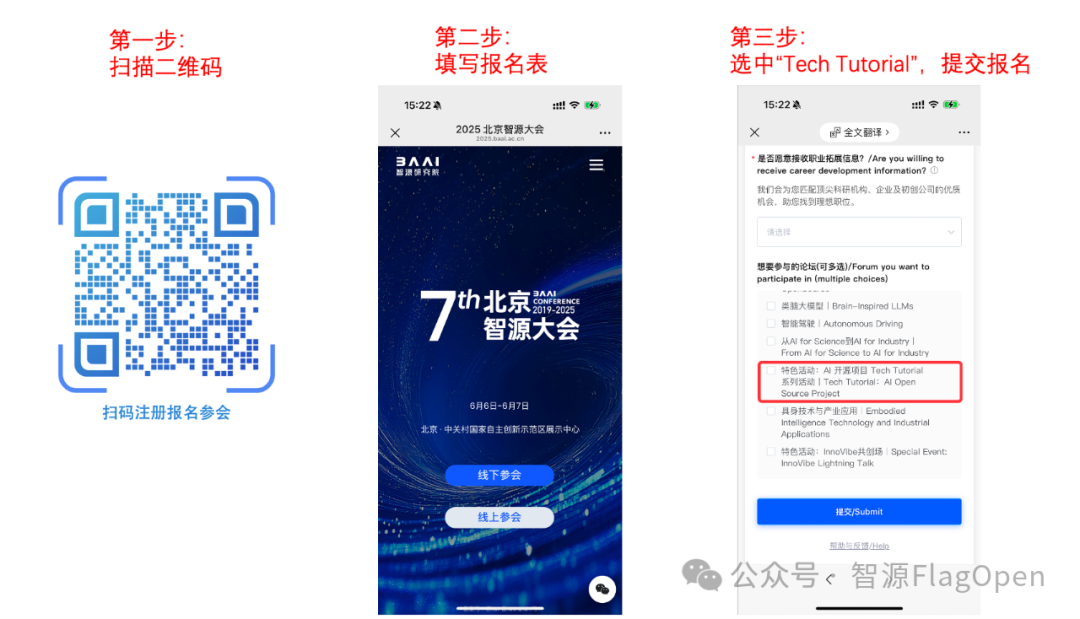
AI 开源项目 Tech Tutorial 系列活动现已开启免费报名,点击「阅读原文」或者扫描二维码,一起聆听一线技术大咖现场面授课 ,助你干货技能UP UP!

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 2
2 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)