Triton入门指南|Triton DSL的特点与类型
Triton官方将其DSL语法表达体系称为 triton.language(https://triton-lang.org/main/python-api/triton.language.html),是一种依托于python环境的DSL,从该命名中的“language”中不难窥见,Triton团队想用自成一派的语言(language)对面向GPU的编程模型进行独特的表达,在Triton中,DSL由
开发前夜
前文提及,Triton不仅是一门抽象的编程语言,还是该语言相应的编译器。它在硬件层面面向CTA(协作线程数组)进行优化,在软件层面则针对线程块的并行层次进行编程。作为编程语言,Triton自然拥有一套独特的语言表达体系(python-DSL)。这些表达对于程序的表达能力和性能具有直接且深远的影响。通过这些语言表达体系,开发者能够更精准地控制硬件行为,实现高效的并行计算。
(1). 什么是DSL ?
DSL,在计算机编程中,全称为Domain Specific Language,是一种专门针对某一特定领域或应用而设计的编程语言或规范。它不同于通用的编程语言,如Java、Python等,这些通用语言旨在满足各种不同类型的编程需求。相反,DSL则另辟蹊径,以简洁、直观且高效的语法和工具支持为核心,致力于简化特定领域内的编程任务,DSL是围绕特定领域的概念、操作和规则设计的。这使得它能够更直接地表达该领域的问题和解决方案,从而提高开发效率并减少错误。
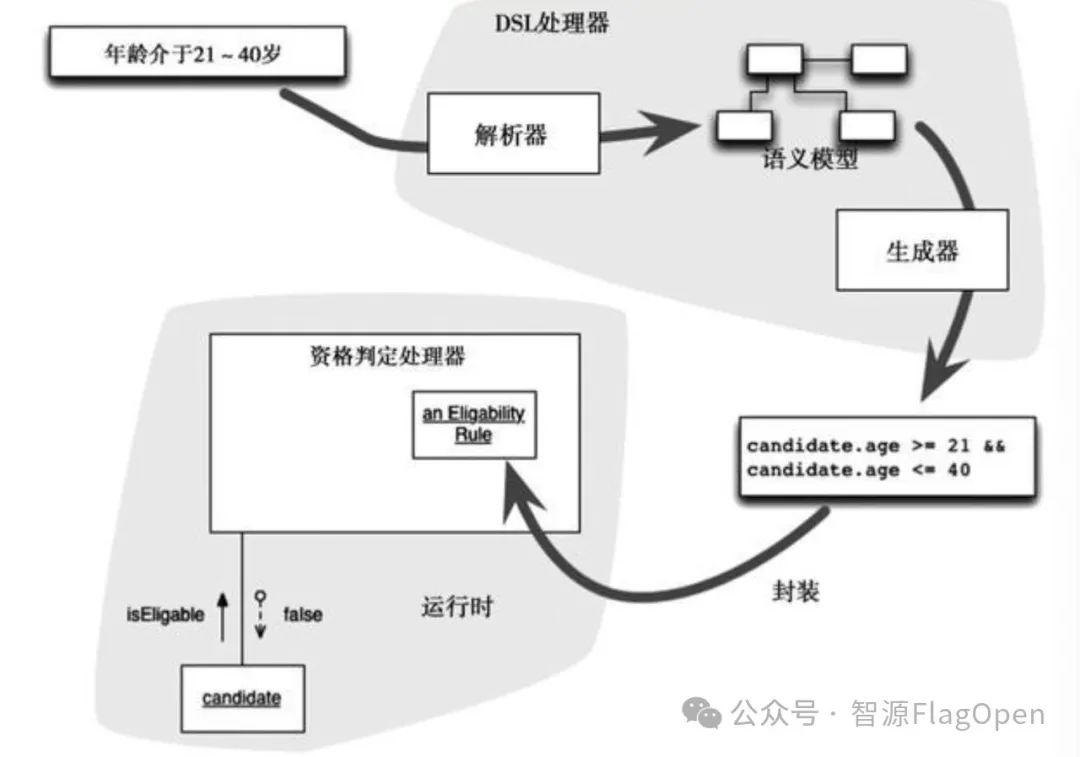
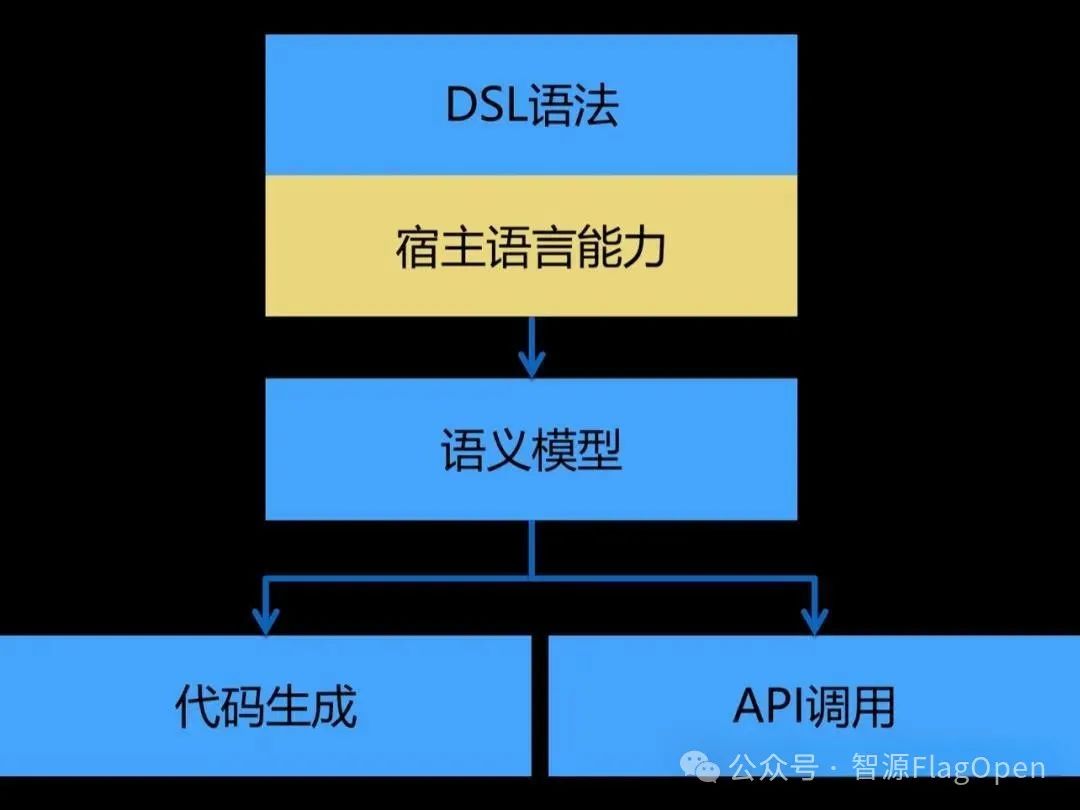
(2). Triton中的DSL(triton.language )
Triton官方将其DSL语法表达体系称为 triton.language(https://triton-lang.org/main/python-api/triton.language.html),是一种依托于python环境的DSL,从该命名中的“language”中不难窥见,Triton团队想用自成一派的语言(language)对面向GPU的编程模型进行独特的表达,在Triton中,DSL由各种基本的操作或函数组成,它们直接映射到GPU的硬件功能,从而实现高效执行。就Triton的使用者而言,了解这些DSL表达的类型和特点,对于充分发挥Triton的性能至关重要。

triton.language(通常通过其别名如tl被引用)是Triton官方提供的一套完备且高效的语法表达与编程接口体系,允许开发者在Triton框架内(以triton.jit为装饰器的python函数内)更灵活,更游刃有余地编写和优化自定义的算子(operators)或处理复杂的数据流程。这些表达广泛涵盖了编写高性能算子所需的各类常规操作,包括但不限于数据加载,存储,基本运算,程序调试等核心功能, 其特点是:
-
高效执行:直接映射到GPU的硬件功能,这使得程序能够以非常高效的方式执行。通过减少抽象层级和提高硬件利用率,有助于实现更高的计算性能。
-
精确控制:为开发者提供了对硬件行为的精确控制。在深度学习和其他高性能计算应用中,这种控制是至关重要的,因为它允许开发者优化数据布局、内存访问模式和同步操作,从而最大限度地提高计算效率。
-
简化编程模型:Triton简化了GPU编程的复杂性,隐藏了一些线程块粒度以下的调度功能,改由编译器自动接管共享存储、线程并行、合并访存、张量布局等细节,降低了并行编程模型的难度,同时提高了用户的生产效率。
-
可扩展性和灵活性:具有良好的可扩展性和灵活性。随着硬件技术的不断发展,新的表达可以很容易地添加到Triton中,以支持新的硬件特性和优化策略。这使得Triton能够持续适应和充分利用最新的硬件创新。
(3).Triton Language的类别
triton.language分为了15个类别,其类别分别是:
-
编程模型(Programming Model)
-
创建操作(Creation Ops)
-
形状操作(Shape Manipulation Ops)
-
线性代数操作(Linear Algebra Ops)
-
内存/指针操作(Memory/Pointer Ops)
-
索引操作(Indexing Ops)
-
数学操作(Math Ops)
-
规约操作(Reduction Ops)
-
扫描/排序操作(Scan/Sort Ops)
-
原子操作(Atomic Ops)
-
随机数生成(Random Number Generation)
-
迭代器(Iterators)
-
内联汇编(Inline Assembly)
-
编译器提示操作(Compiler Hint Ops)
-
调试操作(Debug Ops)
我们可以在:https://github.com/triton-lang/triton/blob/main/python/triton/language/__init__.py中看到triton所有提供的DSL,由这些DSL相互有机的组合,我们就可以简洁高效地编写各种高性能的Triton kernel了。
下面我们将用Triton实现一个vector_add的kernel进一步举例说明一些常用原语:
import tritonimport triton.language as tl@triton.jit()def add_kernel( x: tl.tensor, y: tl.tensor, out: tl.tensor, n_element: tl.constexpr, BLOCK_SIZE: tl.constexpr,): pid = tl.program_id(axis=0) offset = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE) mask = offset < n_element x_ptr, y_ptr, out_ptr = x + offset, y + offset, out + offset x_val, y_val = tl.load(x_ptr, mask), tl.load(y_ptr, mask) out_val = x_val + y_val tl.store(out_ptr, out_val)
上述代码是一个简单vector_add的kernel的示例,代码中以tl.为前缀的表达都属于Triton的DSL,其中:
-
tl.tensor:用于在triton的kernel内表达一个tensor
-
tl.constexpr:用于在triton的kernel内告诉编译器将其修饰的变量在编译期间优化
-
tl.program_id:用于在triton的kernel内获取当前设备运行的program编号
-
tl.arange:用于在triton的kernel内返回半开区间 [start, end) 内的连续值
-
tl.load:用于在triton的kernel内加载其某指针指向的一片数据
具体地:
triton是triton语言的编译器前端
triton.language是triton语言。(一般缩写为 tl)
Triton作为python DSL存在,使用@triton.jit 装饰器装饰函数
-
tl.program(id) 访问 program 的 id, 类似 cuda 的 blockIdx.
-
tl.arange 用来产生一个整数等差序列 tensor. 一般是用来产生 offset 加到指针上去。
-
tensor 定义在 SRAM 上,tl.load 和 store 用于从 DRAM 加载数据或者保存数据到 DRAM.
整个函数中几乎所有的变量都是tl.tensor类型的。包括说a_ptr,它是一个只有一个tl.pointer_type元素的tensor。
上述代码,利用Triton框架的DSL来表达并行计算。函数通过线程块和线程索引计算每个线程应该处理的元素索引,并使用掩码来确保不会访问超出张量长度的索引。然后,它加载输入张量的相应元素,进行相加,并将结果存储到输出张量中。
(1). 首先导入了Triton框架及其语言模块triton.language,并简写为tl以便后续使用。
(2). 使用@triton.jit()装饰器标记该函数为一个 just-in-time(JIT)编译的kernel函数。这个函数接受五个参数:
-
x和y:输入的张量,需要进行元素相加。
-
out:输出的张量,存储相加的结果。
-
n_element:一个编译时常量(constexpr),表示张量中的元素总数。
-
BLOCK_SIZE:另一个编译时常量,表示每个线程块(block)处理的元素数量。
-
pid 是当前线程块(或程序实例)的ID。offset是当前线程块内每个线程要处理的元素的索引,通过pid * BLOCK_SIZE加上一个从0到 BLOCK_SIZE-1的范围来得到。
(3). 使用tl.load函数根据掩码从x_ptr和y_ptr加载有效的元素值到x_val和y_val。然后,将这两个值相加得到out_val。
(4). 使用tl.store函数将计算结果out_val存储到out_ptr指向的位置。

扫码回复“Triton”
加入Triton中文社区交流群

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 25
25 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)