开启大模型时代新纪元:Triton的演变与影响力
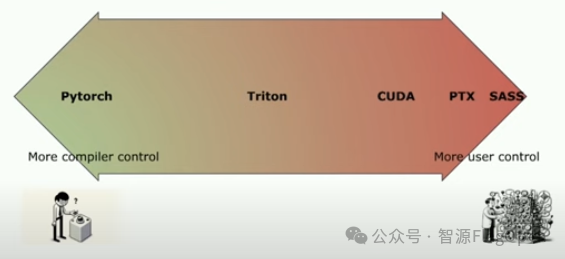
而相比更底层的CUDA C甚至PTX、SASS等,Triton则隐藏了一些线程块粒度以下的调度功能,改由编译器自动接管共享存储、线程并行、合并访存、张量布局等细节,降低了并行编程模型的难度,同时提高了用户的生产效率。同时,厂商能够及时跟进Triton的更新,保持在硬件适配的前沿序列,也可以提出多芯片适用的共性技术创新,并贡献到Triton的开放社区中,继而成为Triton生态发展的引领者。与CUD
从Attention推开大模型时代的大门起,AI领域衍生出崭新多样的计算特性,由厂商算子库和优化专家主导的传统格局正在面临开发难度和需求更新的挑战。如何快速开发和验证新算法?如何低成本地将应用迁移到多元AI芯片上?非编译专家能否进行性能优化?我们的答案是:使用Triton,一款高效、易用的并行编程语言。
Triton的诞生和演进
Triton由哈佛大学的Tillet等人在2019年提出,其论文《Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations》奠定了基础设计,包括线程块级并行编程、基于LLVM的中间表示和分阶段优化pass等。2020年OpenAI启动了Triton(https://github.com/triton-lang/triton)的全面开发,经历多年打磨,目前已经推出了3.0版本,包括PyTorch、Unsloth、FlagGems等在内的开源项目都已采用Triton为其开发部分或全部算子。
Triton最初的工作仅在英伟达的消费型显卡上开展,逐渐扩展到了计算能力更强、架构版本更新的其他GPU上,如工业界常用的A100、H100等。而其他品牌也有多种AI芯片支持了Triton语言,如GPGPU、DSA加速器等国内外不同架构、不同类型的硬件平台。特别的是,Triton现今已经开启了适配CPU的探索,再度提高硬件兼容性的技术支持指日可待。
Triton的核心优势
Triton是一种比较抽象的编程语言和该语言相应的编译器,它在硬件上面向CTA、在软件上面向线程块的并行层次进行编程。Triton相比更高级语言或PyTorch框架提供的功能接口更加专注于计算操作的具体实现,允许开发者灵活地操作Tile级别数据读写、执行计算原语及定义线程块切分方式,特别适宜开发算子融合、参数调优等性能优化策略;而相比更底层的CUDA C甚至PTX、SASS等,Triton则隐藏了一些线程块粒度以下的调度功能,改由编译器自动接管共享存储、线程并行、合并访存、张量布局等细节,降低了并行编程模型的难度,同时提高了用户的生产效率。如此一来,开发者可以集中于算法的设计实现,而无需过度关心编译技巧和性能影响,只要理解简单的并行编程原理,即可快速编写出性能尚可的核函数。
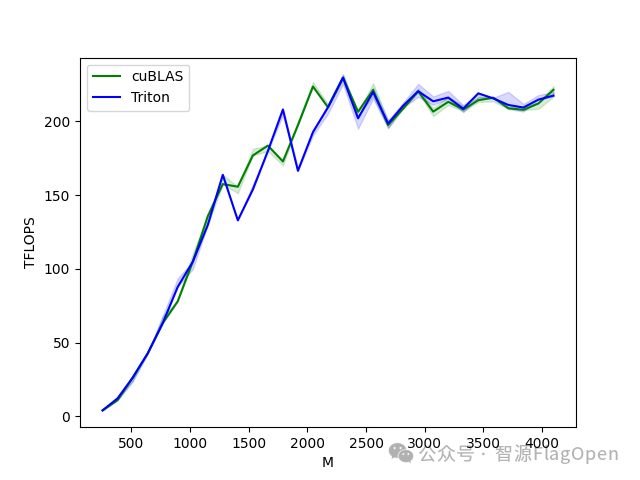
与CUDA相对而言,Triton隐藏了线程级别的操作控制权,在编程灵活性上有所牺牲,以达到开发效率和计算能效的均衡。但Triton通过多层编译和多步优化,其程序性能依然可与CUDA媲美。以计算密集型的标杆算子矩阵乘法(MatrixMultiplication)为例,如下图所示,Triton官方提供的教程代码能够在指定测试环境下追平cuBLAS,充分地调动硬件平台的算力,达到不俗的性能表现。
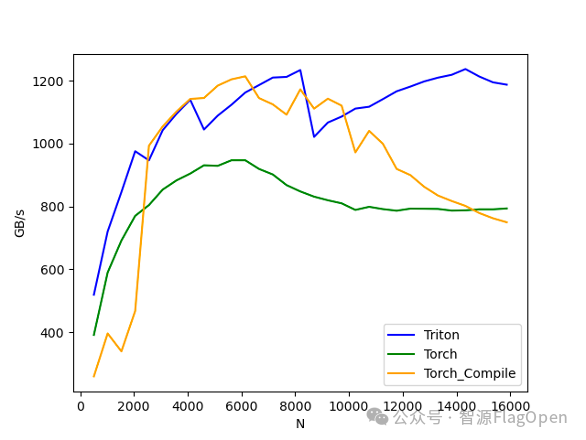
而在下图LayerNorm的例子中,使用Triton手动编写的算子代码,则能够领先torch.compile的生成结果,全面超越Torch原生算子库的算力性能。
Triton的生态融合与硬件迁移
此外,Triton的易用性还体现在与既有生态的无障碍融合上。Triton基于Python语言环境,使用PyTorch定义的张量数据类型,Triton函数可以顺畅地应用到PyTorch框架下的网络模型当中,这也是Torch Inductor选择Triton来作为图优化和代码生成的中间语言的原因之一。
而从硬件迁移的角度来看,Triton的全面开源特性也为AI芯片厂商的适配工作提供了便利。相较于CUDA封闭工具链,Triton的代码开源和生态开放,也正处于持续迭代、广泛吸纳的开发进程当中。厂商能够将体量较小的Triton编译器以较低成本移植到自研芯片上,并能根据自研芯片的架构特征和独有的硬件设计来灵活调整编译器的行为,从而快速添加后端并实际支持基于Triton的丰富的软件项目;同时,厂商能够及时跟进Triton的更新,保持在硬件适配的前沿序列,也可以提出多芯片适用的共性技术创新,并贡献到Triton的开放社区中,继而成为Triton生态发展的引领者。
Triton的实践成果
迄今为止,PyTorch通过Triton来执行计算图的融合优化,仅由一行代码即可应用到整个模型;FlashAttention在第二版中同步推出的Triton版本,部分性能甚至超越了精心打磨的CUDA实现;而来自智源的FlagGems也在多种算子上突破了CUDA算子库的性能水准,整体达到了约30%的加速。Triton因其开放易用的背景受到开发者青睐,又在实践中屡次证明自身的性能实力,我们有理由相信,在AI日渐风靡的大势下,Triton也在奔向更大的舞台。
参考资料:
1.https://triton-lang.org/main/index.html
2.Lightning Talk: Triton Compiler - Thomas Raoux, OpenAI:https://www.youtube.com/watch?v=AtbnRIzpwho
3.Computationshttps://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf

扫码回复“Triton”
加入Triton中文社区交流群
文章转自公众号智源FlagOpen,作者李之昕

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 0
0 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)