Triton大会@硅谷:芯片、AI大厂齐站台
此次大会,包括 Nvidia、AMD、Intel、Qualcomm 在内的各大芯片厂商,以及Google、微软、OpenAI、AWS 和 Meta 等 AI 领域的领军企业,均将 Triton 视为构建开放 AI 软件栈的关键技术,尤其是 Meta 都把 Triton 作为打造开放 AI 软件栈的必需品。Triton 的社区生态建设呈现出一种独特的活力,核心团队虽不张扬,但众多芯片厂商和用户厂商表
9月 17 日,一年一度的 Triton 大会在硅谷举办。智源研究院联合多个团队,基于 Triton 打造面向多元异构 AI 芯片的统一、开源算子库和社区生态,成为 Triton 生态系统中不可或缺的一部分。今年,我们亲临现场,第一时间为您带来大会的精彩内容。智源研究院牵头打造的基于 Triton 的开源算子库 FlagGems/FlagAttention 将在明天开始的 9 月 18 日-19 日的 Pytorch 大会亮相。

今年的 Triton 大会再次在 PyTorch 大会的前夕举行,这一安排凸显了 Triton 与 PyTorch 紧密的合作关系。由 Meta 主办的 Triton 大会,不仅未收取参会费用,也未接受任何厂商赞助,展现了其开放和包容的姿态。大会吸引了逾 300 名专业人士参加,包括来自美国各大芯片制造商的代表,无论是业界巨头还是新兴企业;同时,也包括了 Meta、微软、Google 等 AI 领域的领军企业,以及众多专注于编译器工具链的创新型初创公司。此外,来自湾区各高校的教师和学生也积极参与,特别是斯坦福大学的师生,他们的出席尤为引人注目。
大会亮点
Triton:全球认可的 CUDA 替代方案
Triton 成为全球公认的 CUDA 平替 —— 在智源与国内外众多厂商共同推动统一、开源 AI 芯片软件生态的过程中,Triton 展现出成为 CUDA 替代方案的巨大潜力。此次大会,包括 Nvidia、AMD、Intel、Qualcomm 在内的各大芯片厂商,以及Google、微软、OpenAI、AWS 和 Meta 等 AI 领域的领军企业,均将 Triton 视为构建开放 AI 软件栈的关键技术,尤其是 Meta 都把 Triton 作为打造开放 AI 软件栈的必需品。Nvidia 和 Meta 的积极参与,进一步坚定了我们对 Triton 的信心。
Triton 社区生态的蓬勃发展
Triton 的社区生态建设呈现出一种独特的活力,核心团队虽不张扬,但众多芯片厂商和用户厂商表现出极高的热情和积极性,Triton 社区有种被大家推着往前走的“幸福”感。这种由社区推动的发展态势,也从侧面反映了工业界对 Triton 的高度认可。整个大会下来,几乎忘了 OpenAI 是主导者。
Triton 的性能与易用性
与会者普遍反馈 Triton 在性能上表现优异,且易于上手。在跨平台原型开发中,Triton 能快速展现出性能效果。然而,在大规模、高质量要求的产品部署场景中,Triton 仍需进一步提升。
Triton 的未来方向
Triton 的下一步重点是加强对非 GPU 架构硬件的支持,统一高层次硬件架构的抽象设计,并加强对多后端的软件架构支持。
重要内容记录
以下是对这次 Triton 大会一些重要内容的记录。
Triton profile 工具 Proton
大会首日的两个 Tutorial 环节中。其中一个比较重要的是 Triton 的 profiler 工具 —— Proton。介绍这个工作的是来自Open AI 和 George Mason University 的华人 Keren Zhou。OpenAI 和 Meta 都一表达了 Proton 这个工具项目的重要性。
Proton 跟现有在 NVIDIA 上面的另外两个 profile 工具的比较展现出显著优势。

Keren 在介绍的时候,提供了许多入门动手的例子,大家可以参照下方地址获取。
-
All codes are available on Github: https://tinyurl.com/3uxsd5up
-
Option 1:install using pip wheel: Not all features are available
-
Option 2:install from source: May take a while(~10 mins on an M3 macbook)
OpenAI Keynote Speech 介绍 Triton
来自 OpenAI 的 Philippe Tillet,Triton 项目的最核心贡献者,大家可以通过照片认识一下他本人:)

Phillippe 上来先回顾了去年大会上 Triton 的 codebase 被吐槽,指出其根本问题是对缺乏对于不同 backend 硬件的通用性。

所以新的一年,Triton 在软件结构上加强了“sharing a core infrastructure”的设计。

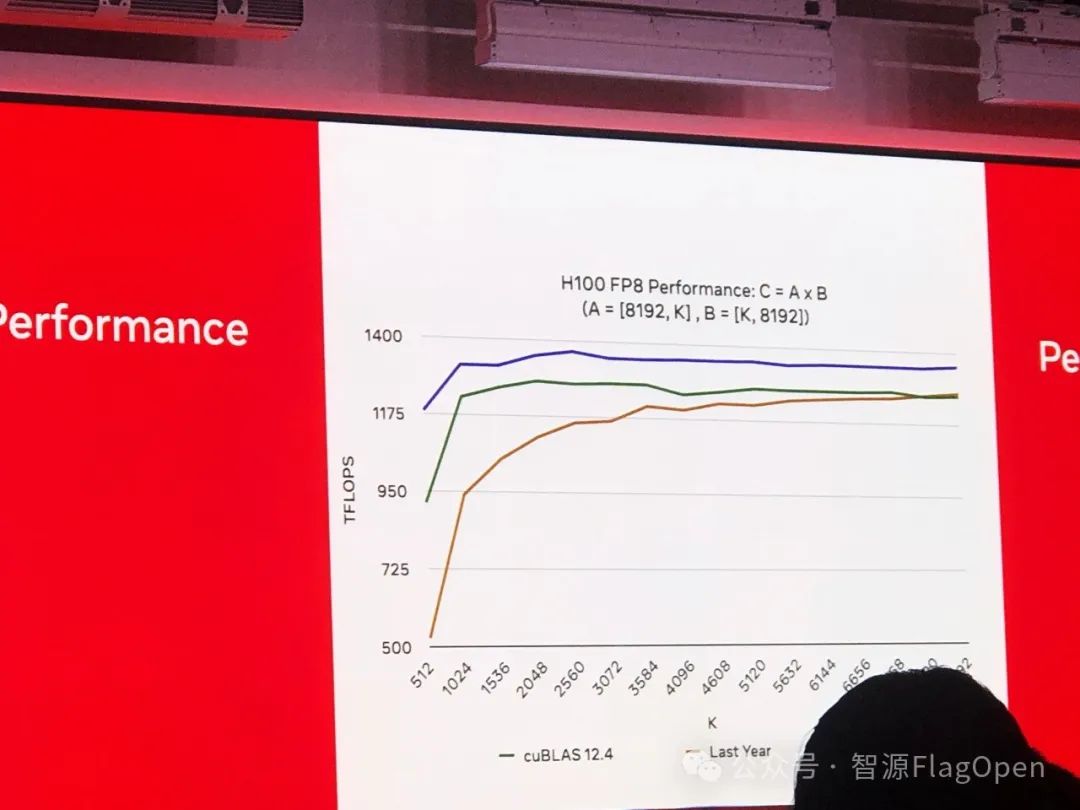
同时,最近 Triton 在 Hopper 架构上做了不少优化,FP8 在 H100 的性能已经明显超过了 cuBLAS。
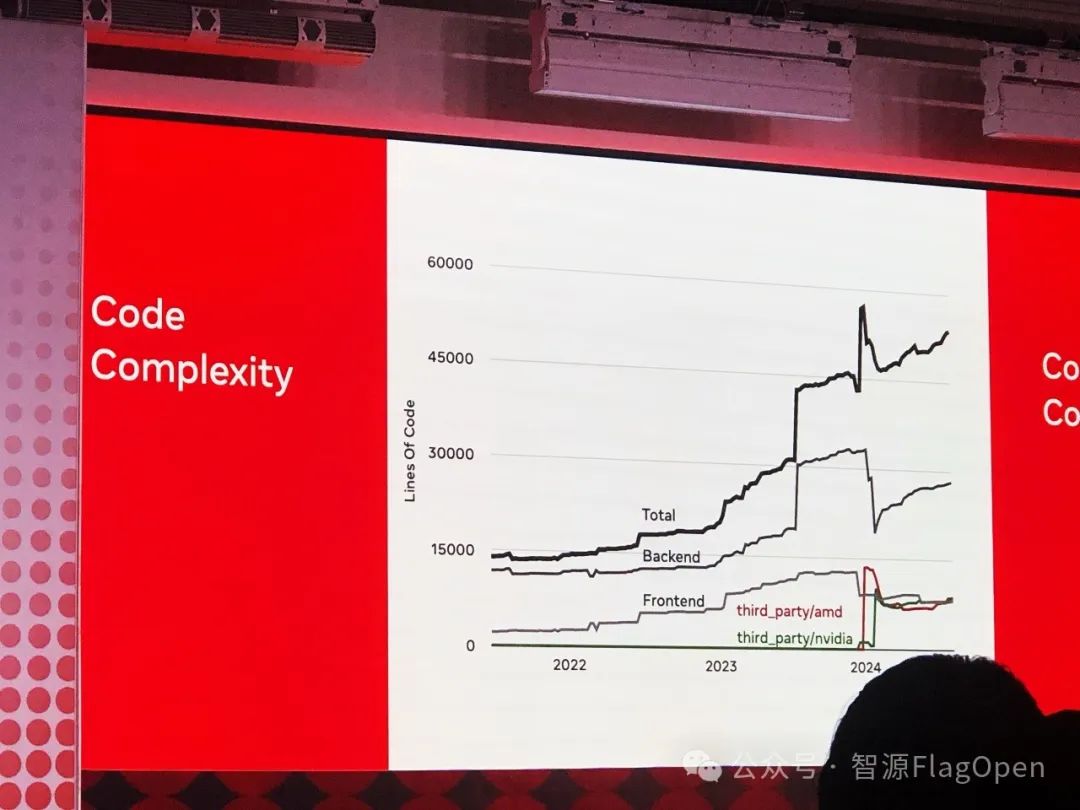
当然,Triton的代码复杂度也不断攀升...
Phillippe 在他的演讲中,分享了目前 Triton 还缺少哪些很有用的工具。

芯片厂商齐上阵
Intel、AMD、微软、AWS、高通和 Nvidia 等芯片厂商分享了他们在 Triton 上的进展和性能成果,展示了 Triton 在不同硬件平台上的广泛应用。
首先上台的是 Intel。

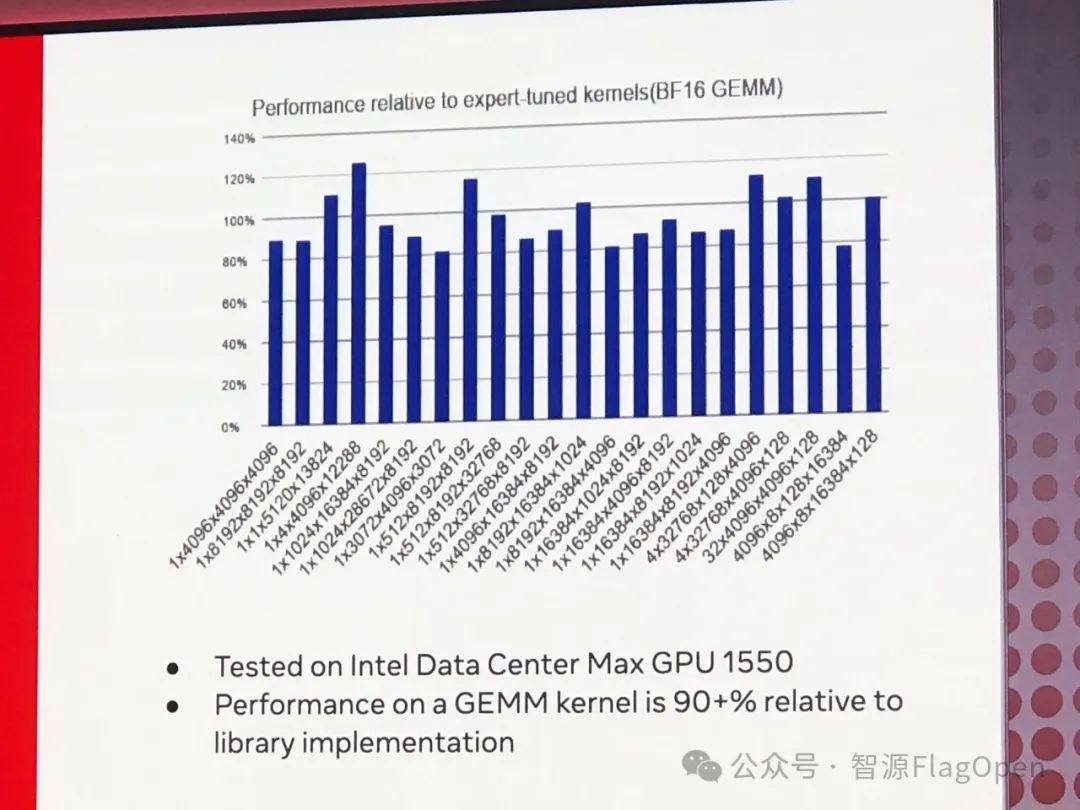
Intel 的分享中很有诚意地给出 Triton 在 Intel 平台上获得的 GEMM 测试性能,目前达到 Intel 专家优化的 GEMM 算子性能超过 90%,这是一个很不错的结果,再接再厉!
Intel 之后是 AMD 的两位华人工程师介绍 AMD 在 Triton 的各种工作。

微软商场先介绍了一下新发布的 AI 芯片 Maia-100。
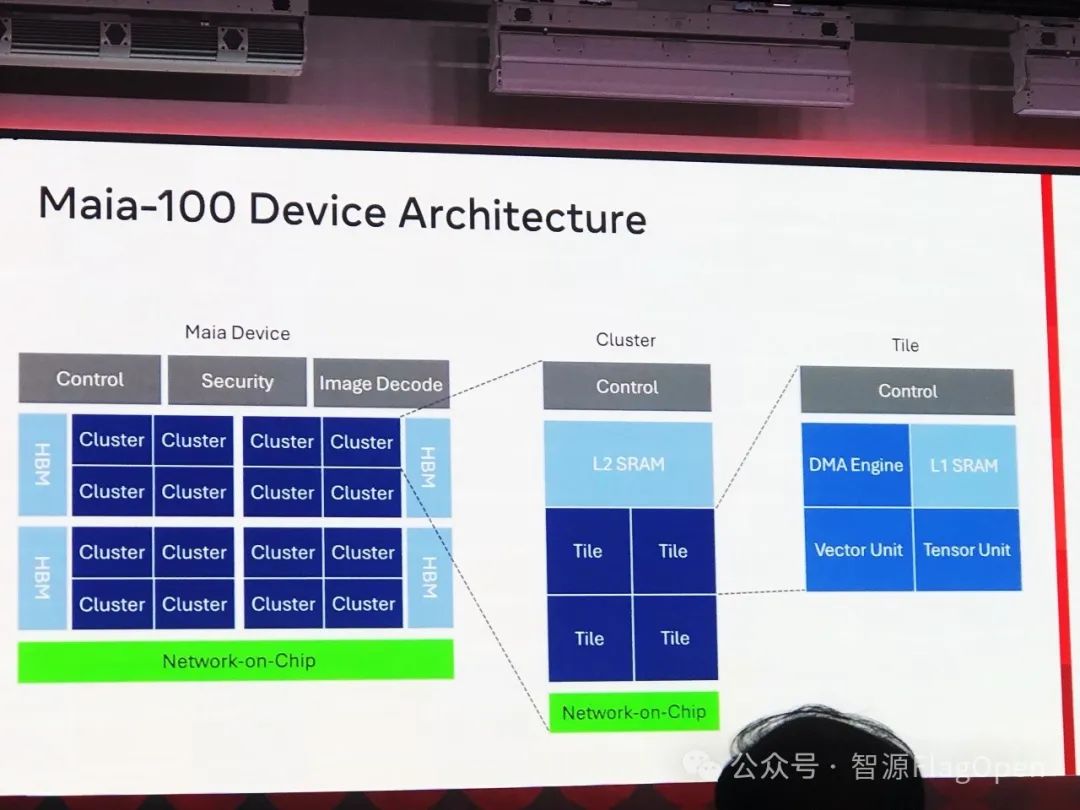
微软也给出了 Triton 在 Maia 上面的性能对比。
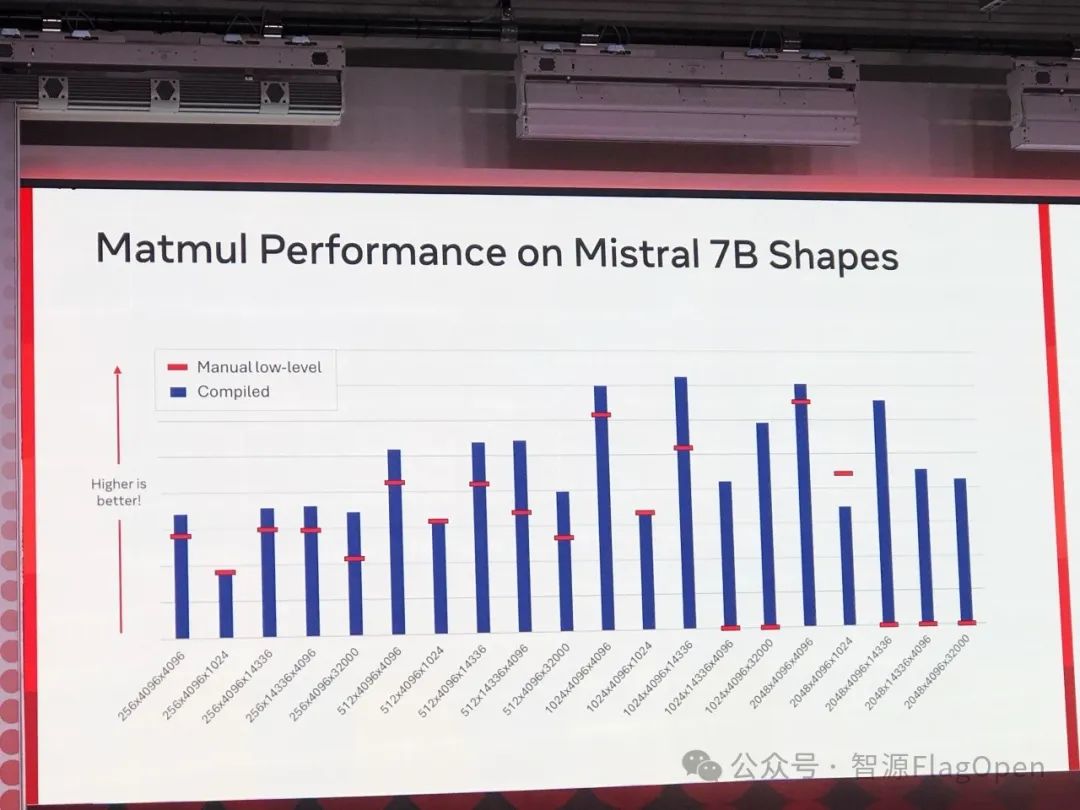
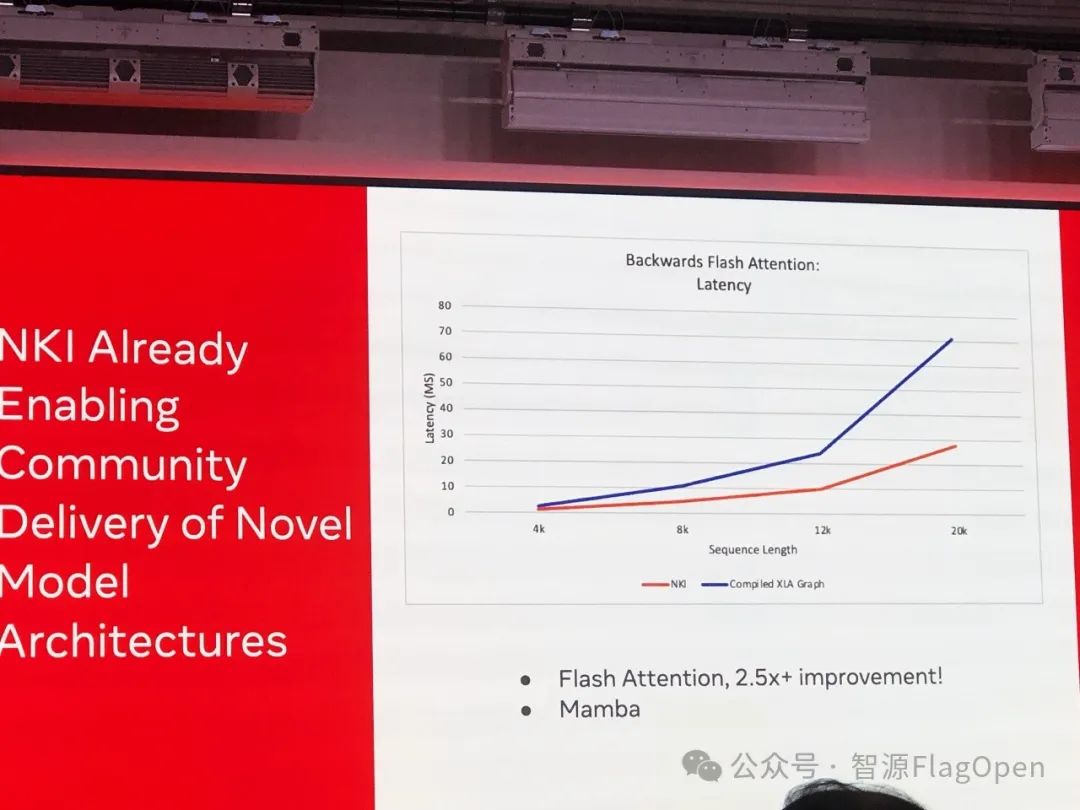
随后,AWS 的代表上台,向与会者介绍了 Triton 在 AWS Trainium 以及 Inferentia 加速芯片上的应用进展。并同步展示了 Triton 在 Flash Attention 任务上取得的不错的加速效果。
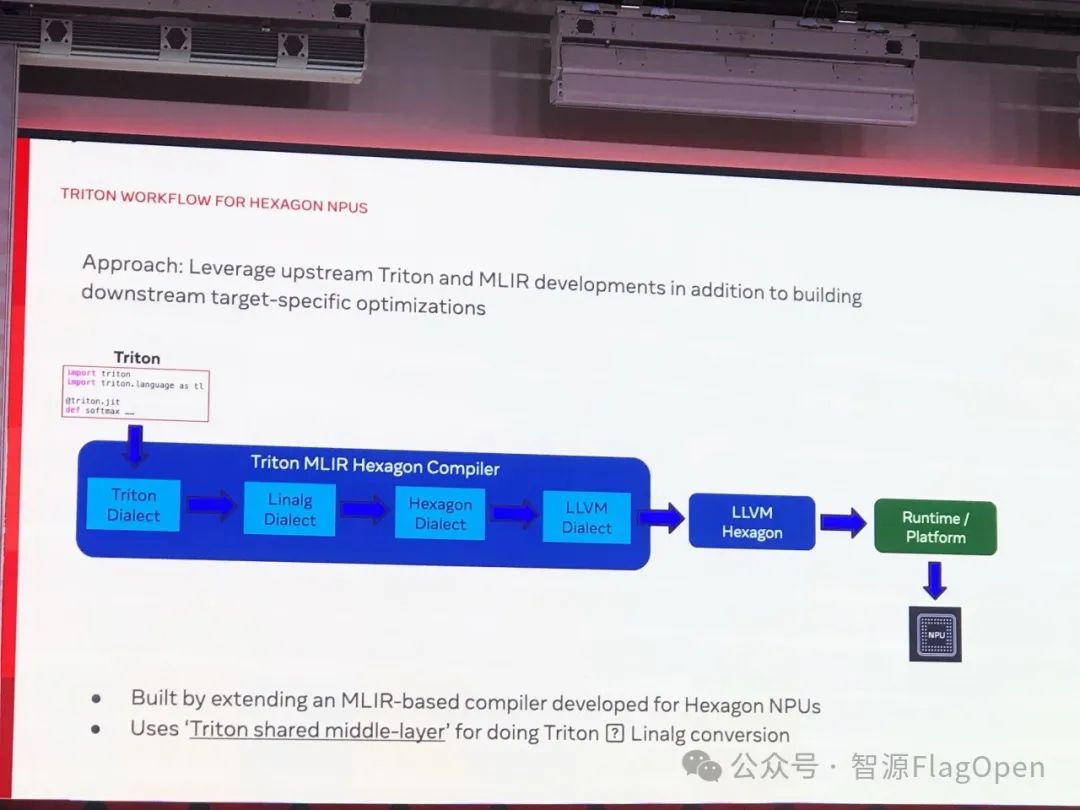
接下来是高通的代表上台。


作为大会的压轴环节,NVIDIA 的代表详细介绍了 Triton 在其最新架构 Blackwell 上的应用和优化工作。

首先,NVIDIA 还是先提了一下 Blackwell 率先支持的 FP6 和 FP4。
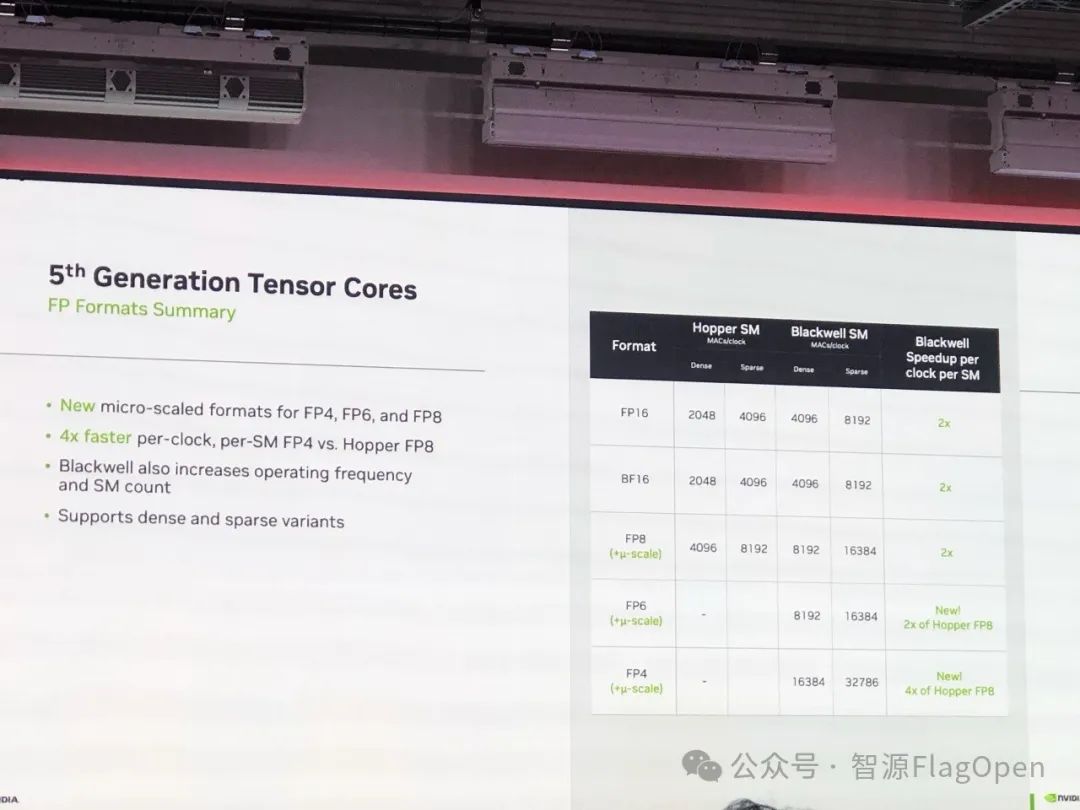
NVIDIA 提到,短短 4 周,通过跟 OpenAI 合作,Triton 在 Blackwell 上面的 GEMMs 性能获得 6 倍提升。当然,他们也很谦虚的说,可能是 CUDA 在 Blackwell 上面还没有好好优化...
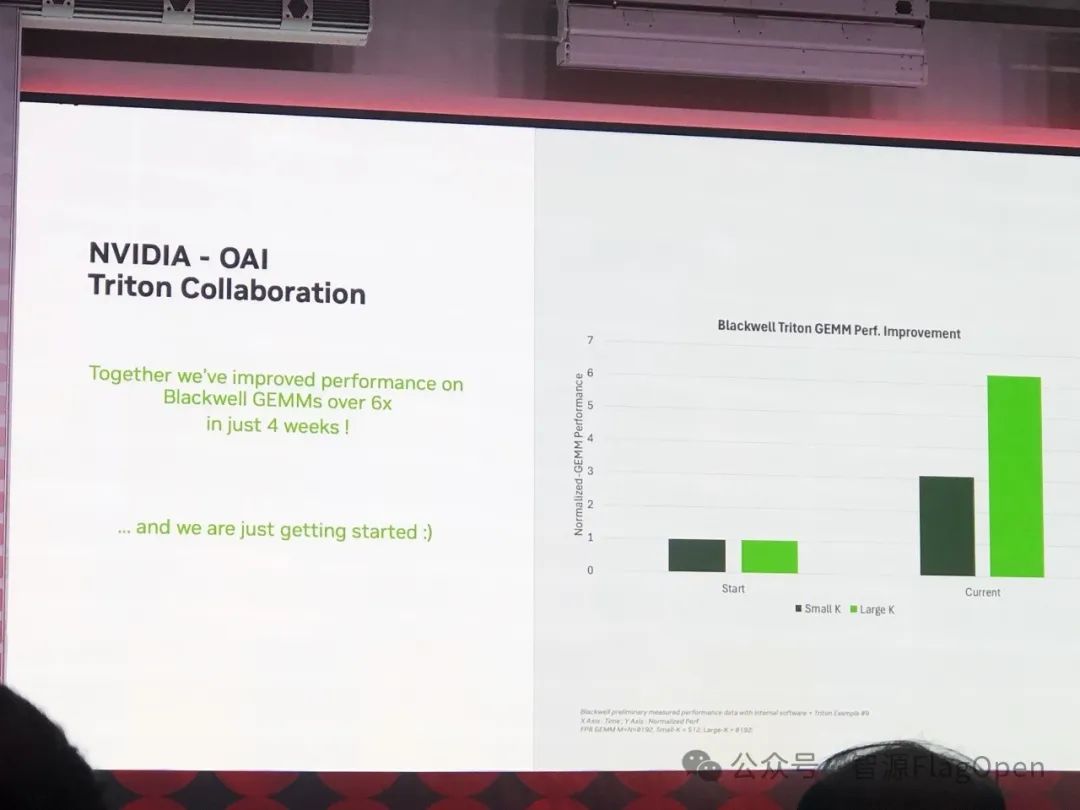

NVIDIA 最后分享了一张有意思的对比图。是不是使用了 FP4,兔子看着比 FP16 还更好呢?:)

Triton for CPU ?
把 Triton 应用到通用CPU领域,这又将撕开一个大的应用场景赛道。Meta 和 Intel 的两位工程师共同介绍了这一有意思的工作。




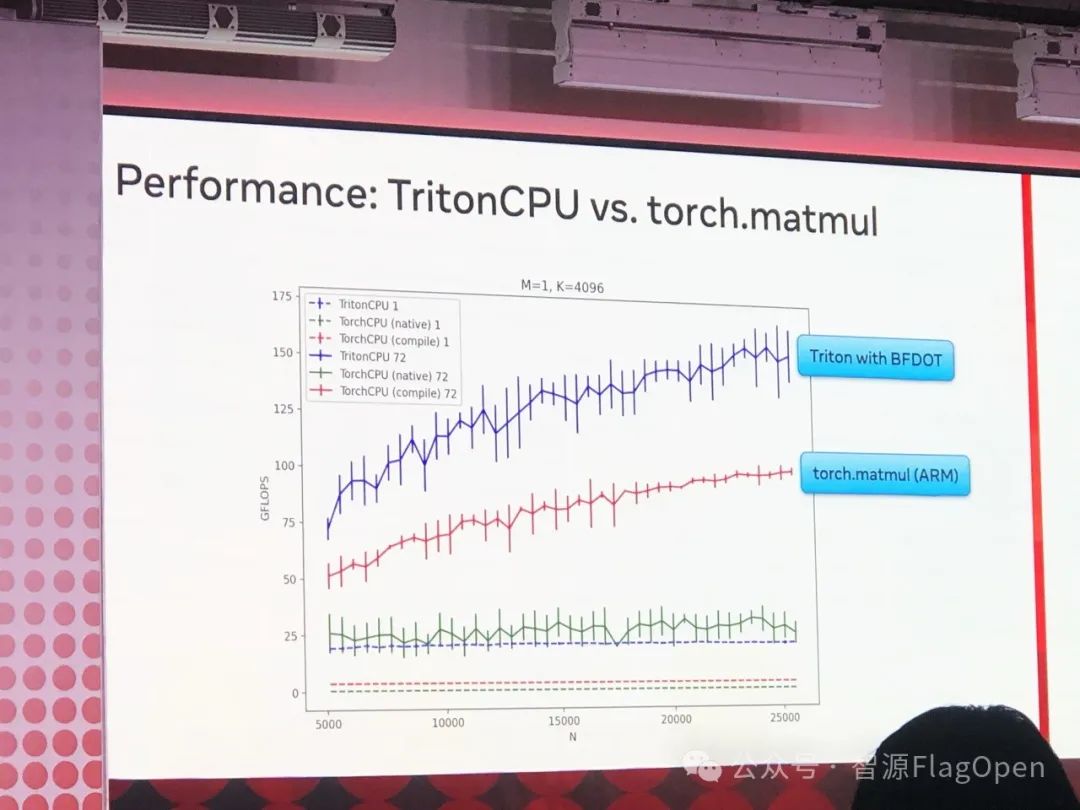
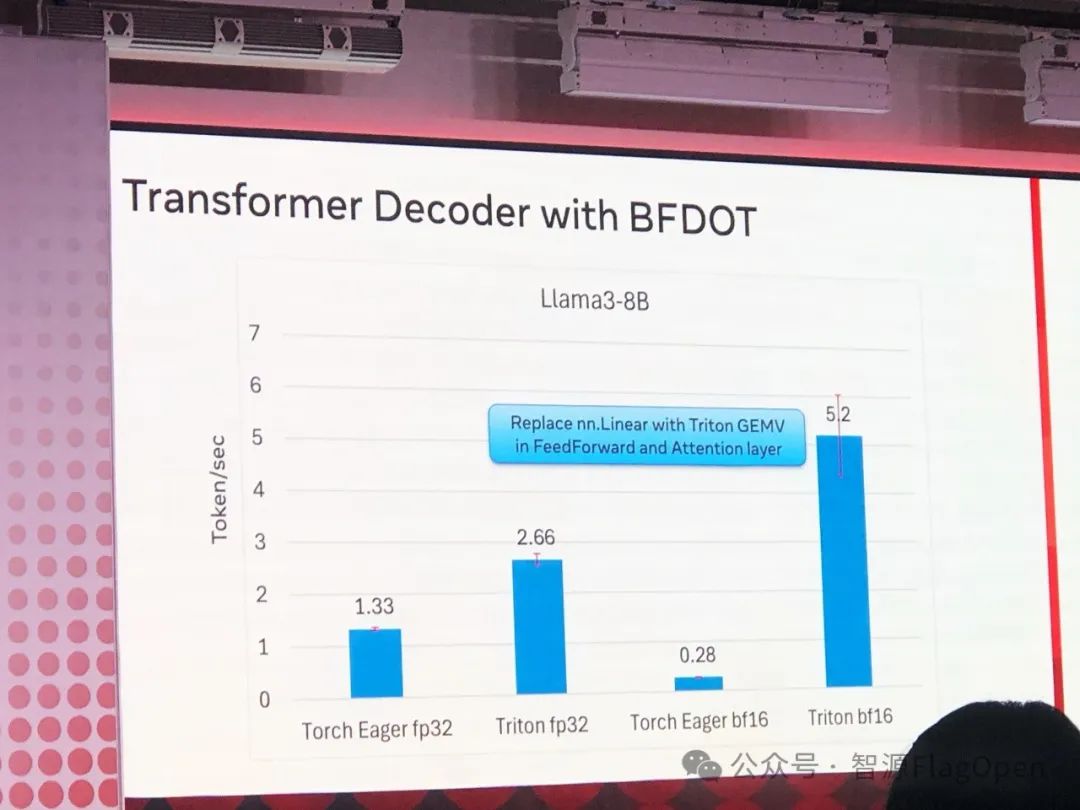
在紧凑的一天会议中,我们经历了信息量巨大的演讲和讨论。在此,我筛选了一些关键的亮点与大家及时分享。同时,我也非常期待地预告,智源将在明后天的 PyTorch 2024 大会上,向各位展示我们的两项重要成果:FlagGems 和 FlagAttention。敬请期待我们的精彩内容!
扫码回复“Ttiton”
加入Triton中文社区交流群


欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 22
22 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)