CUDA基础知识点
CUDA知识点CUDA设备属性内存读写修饰符\_\_global\_\_\_\_device\_\_修饰函数修饰变量\_\_constant\_\_\_\_shared\_\_并行编程An example内置变量用事件测量性能插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaT
CUDA知识点
CUDA设备属性
struct cudaDeviceProp
{
char name[256]; /**< 设备的ASCII标识 */
size_t totalGlobalMem; /**< 可用的全局内存量,单位字节 */
size_t sharedMemPerBlock; /**< 每个block可用的共享内存量,单位字节 */
int regsPerBlock; /**< 每个block里可用32位寄存器数量 */
int warpSize; /**< 线程束大小*/
size_t memPitch; /**< 允许的内存复制最大修正,单位字节*/
int maxThreadsPerBlock; /**< 每个block最大线程数量 */
int maxThreadsDim[3]; /**< 每个block里每个维度最大线程量 */
int maxGridSize[3]; /**< 一格里每个维度最大数量 */
int clockRate; /**< 时钟频率,单位千赫khz */
size_t totalConstMem; /**< 设备上可用的常量内存,单位字节 */
int major; /**< 计算功能主版本号*/
int minor; /**< 计算功能次版本号*/
size_t textureAlignment; /**< 对齐要求的纹理 */
int deviceOverlap; /**< 判断设备是否可以同时拷贝内存和执行内核。已过时。改用asyncEngineCount */
int multiProcessorCount; /**< 设备上的处理器数量 */
int kernelExecTimeoutEnabled; /**< 内核函数是否运行受时间限制*/
int integrated; /**< 设备是不是独立的 */
int canMapHostMemory; /**< 设备能否映射主机cudaHostAlloc/cudaHostGetDevicePointer */
int computeMode; /**< 计算模式,有默认,独占,禁止,独占进程(See ::cudaComputeMode) */
int maxTexture1D; /**< 1D纹理最大值 */
int maxTexture2D[2]; /**< 2D纹理最大维数*/
int maxTexture3D[3]; /**< 3D纹理最大维数 */
int maxTexture1DLayered[2]; /**< 最大的1D分层纹理尺寸 */
int maxTexture2DLayered[3]; /**< 最大的2D分层纹理尺寸 */
size_t surfaceAlignment; /**< 表面的对齐要求*/
int concurrentKernels; /**< 设备是否能同时执行多个内核*/
int ECCEnabled; /**< 设备是否支持ECC */
int pciBusID; /**< 设备的PCI总线ID */
int pciDeviceID; /**< PCI设备的设备ID*/
int pciDomainID; /**<PCI设备的域ID*/
int tccDriver; /**< 如果设备是使用了TCC驱动的Tesla设备则为1,否则就是0 */
int asyncEngineCount; /**< 异步Engine数量 */
int unifiedAddressing; /**< 设备是否与主机共享统一的地址空间*/
int memoryClockRate; /**<峰值内存时钟频率,单位khz*/
int memoryBusWidth; /**< 全局内存总线宽度,单位bit*/
int l2CacheSize; /**< L2 cache大小,单位字节 */
int maxThreadsPerMultiProcessor;/**< 每个多处理器的最大的常驻线程 */
};
#include "stdio.h"
#include <cuda_runtime.h>
int main(){
cudaDeviceProp prop;
int count;
cudaGetDeviceCount(&count);
for(int i=0;i<count;i++){
cudaGetDeviceProperties(&prop,i);
printf("Name: %s\n",prop.name);
}
return 0;
}
内存读写
- 在主机代码中调用cudaMalloc分配设备内存,并可以将指向设备内存的指针传递给设备函数或者主机函数,但不可在主机代码中访问设备内存
- 主机代码中只能访问主机内存(堆,栈)
- 要访问已经分配的设备内存,只有将设备内存的指针传递给设备函数,在设备函数上进行访问
- 设备函数中无法访问主机内存,所以不能给设备函数传递指向主机内存的指针,但是可以直接值传递数值参数
- 设备函数中无法调用主机函数,但是计算功能集大于等于2.0支持在设备函数中调用printf函数
- 要使用设备函数处理主机内存中的数据,可使用cudaMemcpy函数将主机内存中的数据拷贝到设备内存进行处理,处理好之后再拷贝回主机内存
- 使用cudaMalloc和malloc分配的内存一定要用cudaFree和free进行释放
修饰符
__global__
- 函数仅可在设备上执行,仅可被主机函数调用
- 函数不支持递归
- 函数体内无法声明静态变量
- 函数参数数量不可变
- 函数返回值必须为void
- 函数的调用是异步的,也就是说它会在设备执行完成之前返回
- 函数执行后需要调用函数cudaDeviceSynchronize进行同步,函数cudaMemcpy会隐式自动同步
- 函数参数将同时通过共享存储器传递给设备,且限制为 256 字节(不理解)
__device__
修饰函数
- 函数仅可在设备上执行,仅可被设备函数调用
- 函数不支持递归
- 函数体内无法声明静态变量
- 函数参数数量不可变
- 函数的地址无法获取
修饰变量
- 变量位于全局存储器空间中,与应用程序具有相同的生命周期
- 变量可被所有线程访问
- 变量值可通过函数cudaMemcpyToSymbol和cudaMemcpyFromSymbol进行拷贝传递
__constant__
- 变量位于固定存储器空间中,与应用程序具有相同的生命周期
- 变量可被所有线程访问,访问权限为只读,所以不能在设备函数中进行初始化,只能在主机函数中进行初始化
- 变量值可通过函数cudaMemcpyToSymbol进行初始化,初始化后不可改变,用函数cudaMemcpyFromSymbol进行拷贝
- 性能提升原因:
- 线程束指一个包含32个线程的集合,每个线程集合步调一致地执行,线程束中的每个线程都将在不同的数据上执行相同的指令
- 硬件能够将单次读取常量内存的值广播到半个线程束,即16个线程。如果半个线程束都读取相同地址的数据,则只要一次读操作,再将数据广播到其他”邻近“线程,从而节约15次读操作
- 常量内存的数据将缓存起来,对相同地址的连续读操作不会产生额外的内存通信量
__shared__
- 变量位于线程块的共享存储器空间中
- 变量与块具有相同的生命周期
- 变量可被块内的所有线程访问
- 访问共享内存的延迟要远低于访问普通缓冲区的延迟
- 使用函数__syncthreads()保证对一个线程块中所有线程对共享数组的写入操作在读取之前完成
并行编程
样例代码
#define DIM 128
__global__ kernel(const float *a, float *b){
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
//......
}
int main(){
dim3 blocks(DIM/16, DIM/16);
dim3 threads(16, 16);
floag *a, *b;
CHECK(cudaMalloc((void **)&a, DIM * sizeof(float)));
CHECK(cudaMalloc((void **)&b, DIM * sizeof(float)));
kernel<<<blocks, threads>>>(a, b);
//......
CHECK(cudaFree(a));
CHECK(cudaFree(b));
}
内置变量
- threadIdx.x: 线程块中的x方向的线程号
- blockIdx.x: 线程格中的x方向的线程块号
- blockDim.x: 线程块中的x方向的线程的数量
- gridDim.x: 线程格中的x方向的线程块的数量
- y同理
- 不同线程根据各自不同的内置变量值获得各自需要处理的数据位置,从而实现对一个数组所有元素的并行处理
用事件测量性能
事件的本质是一个GPU时间戳
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start, 0));
//......
CHECK(cudaEventRecord(stop, 0));
CHECK(cudaEventSynchronize(stop));
float time_diff;
CHECK(cudaEventElapsedTime(&time_diff, start, stop));
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
cudaEventSynchronize(stop)的作用:确保stop事件之前的所有GPU工作已经完成
纹理内存
简介
纹理内存是一种只读内存,能够为内存访问存在大量空间局部性的程序减少对内存的请求并提供更高效的内存带宽。
空间局部性:同一个线程或邻近多个线程读取数据的地址相近。
使用
一维纹理内存
//主机函数中初始化纹理内存
//......
texture<float> tex;
CHECK(cudaMalloc((void **)&a, sizeof(float) * N));
CHECK(cudaBindTexture(NULL, tex, a, N));
//......
//设备函数中对纹理内存进行读取
//......
float t = tex1Dfetch(tex, index);
//......
//在主机函数中释放纹理内存
//......
cudaUnbindTexture(tex);
//......
二维纹理内存
//主机函数中初始化纹理内存
//......
texture<float> tex;
CHECK(cudaMalloc((void **)&a, sizeof(float) * N));
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>(); //通道格式描述符
CHECK(cudaBindTexture(NULL, tex, a, desc, DIM, DIM, sizeof(float) * DIM));
//......
//设备函数中对纹理内存进行读取
//......
float t = tex2Dfetch(tex, x, y);
//......
//在主机函数中释放纹理内存
//......
cudaUnbindTexture(tex);
//......
原子性
计算功能集
NVIDIA将GPU支持的各种功能统称为计算功能集
编译指定计算功能集不能低于某一个版本:
nvcc -arch=sm_12
原子操作
原子性:一次性对某个内存空间进行读写操作,在执行过程中不会被其他线程中断
atomicAdd(&a, 1); //+1
注意:当数千个线程尝试访问少量内存时,将发生大量竞争,为保持原子性需要付出大量开销,所以会降低性能
解决措施:在线程块内设置一个共享内存,只让块内的多个线程竞争,将结果暂时存在共享内存中,最后将所有线程块中共享内存中的结果综合到全局内存中
页锁定主机内存
malloc():分配可分页的主机内存
cudaHostAlloc():分配不可分页的主机内存
不可分页主机内存:操作系统不会对这块内存分页并交换到磁盘上,确保该内存始终驻留在物理内存中
用cudaHostAlloc()提升性能的原因:GPU知道内存的物理地址,可以通过直接内存访问(DMA)技术在GPU和主机之间复制数据,无需CPU介入。当内存为分页内存时,CPU可能会在DMA执行过程中将目标内存交换到磁盘上,或通过更新操作系统的可分页表来 重新定位目标内存的物理地址,从而对DMA操作造成延时。而不可分页内存的使用不会造成延时,提高了性能。另一方面,在可分页内存数据拷贝到GPU的过程中,复制操作会执行两次,第一次是将可分页内存复制到一块临时的页锁定内存,再从这个页锁定内存复制到GPU上,两次复制增大了开销
注意:过多不可分页内存的使用会使主机内存耗尽,影响其他程序运行
float *a;
CHECK(cudaHostAlloc((void **)&a, sizeof(float) * N));
//......
CHECK(cudaFreeHost(a));
CUDA流
cudaMemcpy():同步复制,函数返回时复制操作已经完成
cudaMemcpyAsync():异步复制,函数返回时复制操作不一定完成,结合stream使用
stream的作用:在主机函数有序调用多个异步设备函数时,保证这些异步设备函数能够有序执行
cudaStreamSynchronize(stream):保证异步方式在stream流中执行的设备函数全部完成
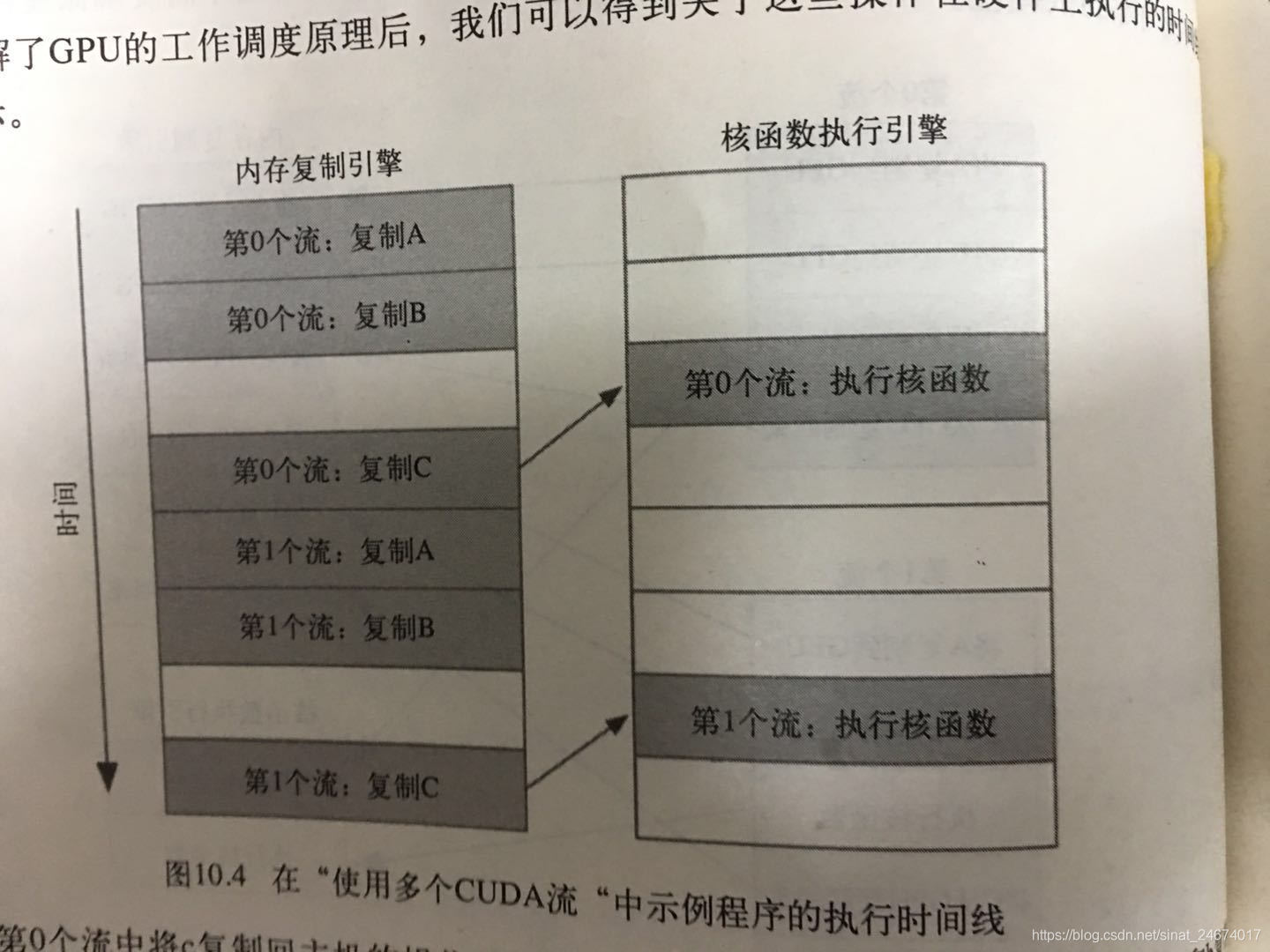
stream0中复制C的操作要等待核函数执行完成,所以阻塞了stream1中复制A的操作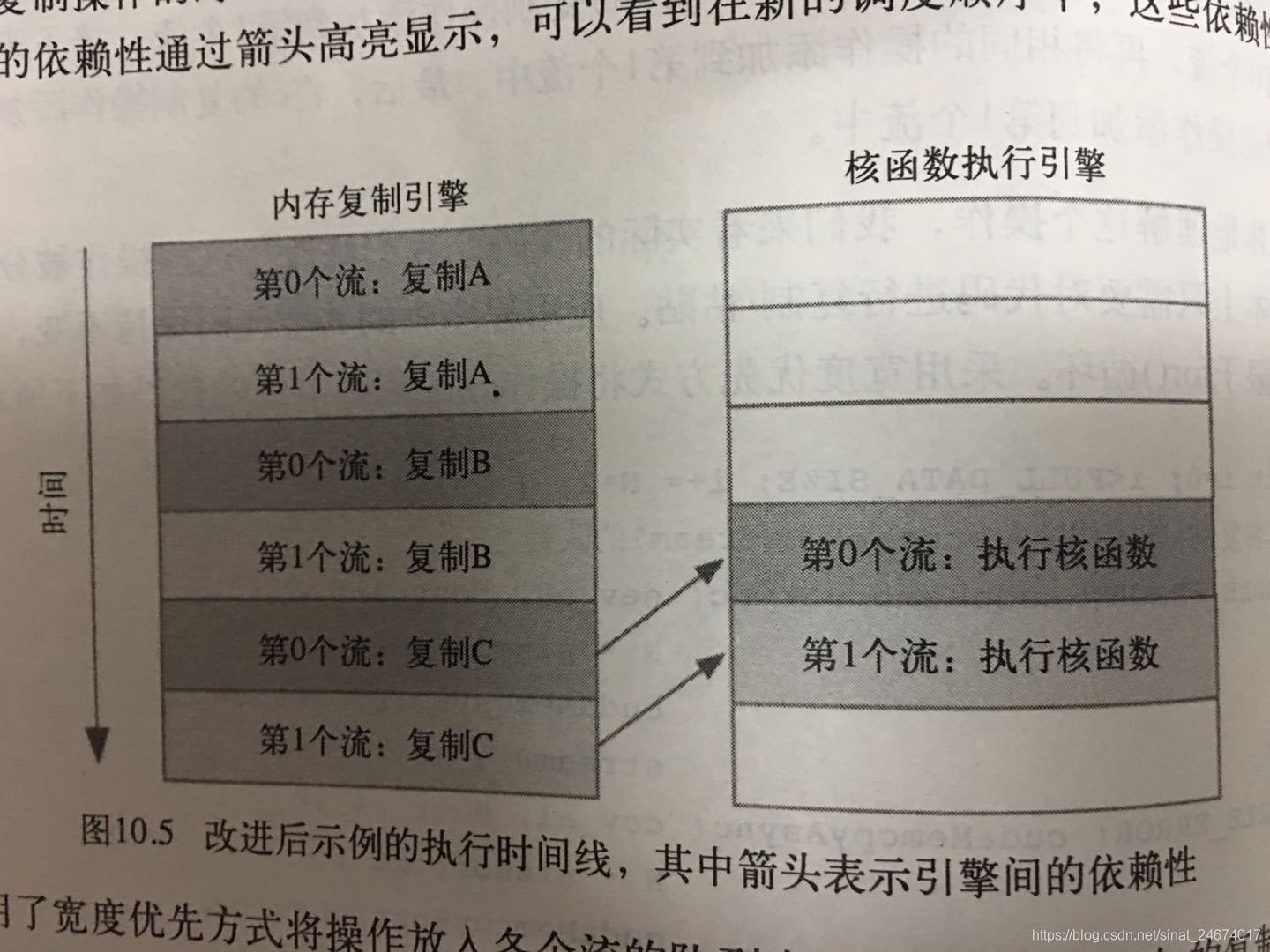
改进:使用宽度优先方式将操作放入各个流的队列,加速运行速度
零拷贝主机内存
简介
在cudaHostAlloc()函数中传入cudaHostAllocMapped参数,能够分配得到在设备函数中直接访问的页锁定主机内存,从而可以免去主机和设备之间的数据拷贝
使用
CHECK(cudaSetDeviceFlags(cudaDeviceMapHost)); //设置为设备映射主机内存
float *a, *dev_a;
CHECK(cudaHostAlloc((void**)&a, size * sizeof(float), cudaHostALlocWriteCombined | cudaHostAllocMapped)); //分配可在设备函数访问的页锁定主机内存
CHECK(cudaHostGetDevicePointer(&dev_a, a, 0)); //获得在GPU上的有效指针
//......
CHECK(cudaFreeHost(a));
标志cudaHostAllocWriteCombined:将内存分配为“合并式写入”内存,主要用于主机到设备的传输或者通过映射页锁定空间CPU写而设备读的情况,可以显著提升GPU读取内存的性能,但CPU读取该内存时会比较低效
标志cudaHostAllocMapped:将主机内存分配为GPU可访问的内存
零拷贝内存的性能
集成GPU:设备内存和主机内存在物理上共享,所以使用零拷贝内存可避免不必要的数据拷贝,提升性能
独立GPU:当程序满足“仅读取/写入一次”这个约束条件时,在独立GPU上使用零拷贝内存可以获得性能提升。但是由于GPU不会缓存零拷贝内存,当设备函数需要多次读写内存时,会降低性能,还不如把数据复制到GPU上
注意:由于零拷贝内存时页锁定内存,所以申请过多零拷贝内存会减少可使用的物理内存,影响其他程序的运行
使用多个GPU
样例代码
/*
* Copyright 1993-2010 NVIDIA Corporation. All rights reserved.
*
* NVIDIA Corporation and its licensors retain all intellectual property and
* proprietary rights in and to this software and related documentation.
* Any use, reproduction, disclosure, or distribution of this software
* and related documentation without an express license agreement from
* NVIDIA Corporation is strictly prohibited.
*
* Please refer to the applicable NVIDIA end user license agreement (EULA)
* associated with this source code for terms and conditions that govern
* your use of this NVIDIA software.
*
*/
#include <book.h>
#define imin(a,b) (a<b?a:b)
#define N (33*1024*1024)
const int threadsPerBlock = 256;
const int blocksPerGrid =
imin( 32, (N/2+threadsPerBlock-1) / threadsPerBlock );
__global__ void dot( int size, float *a, float *b, float *c ) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < size) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// set the cache values
cache[cacheIndex] = temp;
// synchronize threads in this block
__syncthreads();
// for reductions, threadsPerBlock must be a power of 2
// because of the following code
int i = blockDim.x/2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
struct DataStruct {
int deviceID;
int size;
float *a;
float *b;
float returnValue;
};
void* routine( void *pvoidData ) {
DataStruct *data = (DataStruct*)pvoidData;
HANDLE_ERROR( cudaSetDevice( data->deviceID ) ); //为每个线程指定执行的GPU
int size = data->size;
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// allocate memory on the CPU side
a = data->a;
b = data->b;
partial_c = (float*)malloc( blocksPerGrid*sizeof(float) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a,
size*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b,
size*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_partial_c,
blocksPerGrid*sizeof(float) ) );
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR( cudaMemcpy( dev_a, a, size*sizeof(float),
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMemcpy( dev_b, b, size*sizeof(float),
cudaMemcpyHostToDevice ) );
dot<<<blocksPerGrid,threadsPerBlock>>>( size, dev_a, dev_b,
dev_partial_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( partial_c, dev_partial_c,
blocksPerGrid*sizeof(float),
cudaMemcpyDeviceToHost ) );
// finish up on the CPU side
c = 0;
for (int i=0; i<blocksPerGrid; i++) {
c += partial_c[i];
}
HANDLE_ERROR( cudaFree( dev_a ) );
HANDLE_ERROR( cudaFree( dev_b ) );
HANDLE_ERROR( cudaFree( dev_partial_c ) );
// free memory on the CPU side
free( partial_c );
data->returnValue = c;
return 0;
}
int main( void ) {
int deviceCount;
HANDLE_ERROR( cudaGetDeviceCount( &deviceCount ) );
if (deviceCount < 2) {
printf( "We need at least two compute 1.0 or greater "
"devices, but only found %d\n", deviceCount );
return 0;
}
float *a = (float*)malloc( sizeof(float) * N );
HANDLE_NULL( a );
float *b = (float*)malloc( sizeof(float) * N );
HANDLE_NULL( b );
// fill in the host memory with data
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = i*2;
}
// prepare for multithread
DataStruct data[2];
data[0].deviceID = 0;
data[0].size = N/2;
data[0].a = a;
data[0].b = b;
data[1].deviceID = 1;
data[1].size = N/2;
data[1].a = a + N/2;
data[1].b = b + N/2;
CUTThread thread = start_thread( routine, &(data[0]) ); //创建一个新线程,在新线程中调用routine函数
routine( &(data[1]) ); //在主线程中调用routine函数
end_thread( thread ); //等待两个线程的routine函数执行完成
// free memory on the CPU side
free( a );
free( b );
printf( "Value calculated: %f\n",
data[0].returnValue + data[1].returnValue );
return 0;
}
可移动的页锁定内存
在使用多个GPU时,cudaHostAlloc分配的页锁定内存只对于分配它们的线程来说是页锁定的,而其他线程依然把这块内存当作可分页内存。当其他线程复制这块内存数据时,会当作可分页内存进行复制,降低性能
解决方案:cudaHostAlloc((void **)&a, N * sizeof(float), cudaHostAllocPortable);

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)