OpenAI Triton优化pass | Optimizer
0.Triton Optimizer OpenAI Triton简介中提到Optimizer,其主要用于分析和优化前端传入的Triton IR,通过各类 Transformation 和 Conversion (Pass) 策略,最终传递给 Backend 做 translate,IR的整个经过的流程如下: 从图中可以看出主要有
·
0.Triton Optimizer
OpenAI Triton简介中提到Optimizer,其主要用于分析和优化前端传入的Triton IR,通过各类 Transformation 和 Conversion (Pass) 策略,最终传递给 Backend 做 translate,IR的整个经过的流程如下:
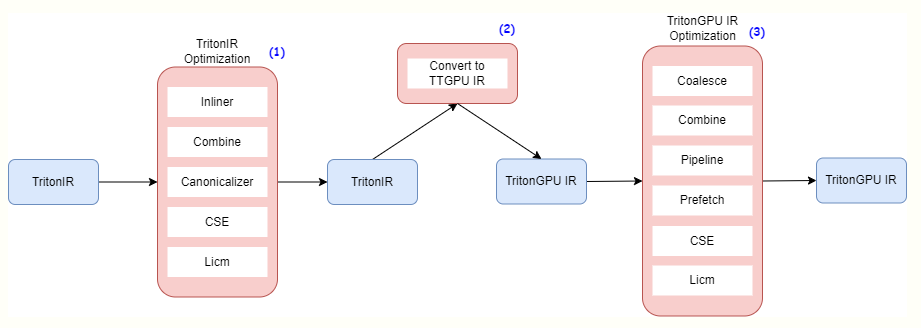
从图中可以看出主要有三个部分的优化:
- Triton IR的优化;
- Triton IR到TritonGPU IR的转换;
- TritonGPU IR的优化;
其中与硬件GPU相关的IR为TritonGPU IR,该IR包含了与GPU 相关的信息,如硬件相关的Op以及layout信息。
(OpenAI triton分享:triton源码结构_哔哩哔哩_bilibili)
1.Triton IR优化pass
Triton IR 上的优化主要是计算本身的,与硬件无关的优化,包含了如下 Pass:
- Inliner Pass:将 Kernel 内调用的子函数 Inline 展开;
- Combine Pass:将一些特定的case进行op的融合,如:
select(cond, load(ptrs, broadcast(cond), ???), other) => load(ptrs, broadcast(cond), other) - Canonicalizer Pass:通过应用一系列的规则来简化和标准化IR;
- CSE Pass:MLIR 的 cse Pass,公共子表达式消除;
- LICM Pass:MLIR 的LoopInvariantCodeMotion Pass(https://mlir.llvm.org/doxygen/LoopInvariantCodeMotion_8cpp_source.html),将循环无关的变量挪到for循环外;
2.TritonGPU IR 的优化
TritonGPU IR 上的优化在计算本身优化外,新增了 GPU 硬件相关的优化,具体的 Pass如下:
- ConvertTritonToTritonGPU Pass:将 Triton IR 转换为 TritonGPU IR,主要是增加 TritonGPU 硬件相关信息的 layout;
- Coalesce Pass:访存合并pass,重排order,使得最大contiguity 的维度排在最前面(pass原理解析可以参考:https://zhuanlan.zhihu.com/p/687394750);
- Combine Pass:和Triton IR优化pass功能一致;
- Pipeline Pass:MMA 指令(对应功能部件为NVIDIA的Tensor Core)对应的 global memory 到 shared memory 的 N-Buffer 多缓冲优化;
- Prefetch Pass:MMA 指令对应的 shared memory 到 register file 的 N-Buffer 多缓冲优化;
- Canonicalizer:和Triton IR优化pass功能一致;
- CSE Pass:和Triton IR优化pass功能一致;
- LICM Pass:和Triton IR优化pass功能一致;
MMA指令实现原理可以参考(https://zhuanlan.zhihu.com/p/455166274)

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)