使用perf_analyzer和model-analyzer测试tritonserver的模型性能超详细完整版
在使用triton-server部署模型完成之后,我们需要测试一下模型服务的能力,这篇文章详细介绍了如何通过perf_analyzer和model-analyzer两款测试工具来测试模型服务的吞吐量
导读
当我们在使用tritonserver部署模型之后,通常需要测试一下模型的服务QPS的能力,也就是1s我们的模型能处理多少的请求,也被称为吞吐量。
测试tritonserver模型服务的QPS通常有两种方法,一种是使用perf_analyzer 来测试,另一种是通过model-analyzer来获取更为详细的模型服务启动的参数,使得模型的QPS达到最大,下面我们将分别来介绍如何通过这两种工具来测试tritonserver模型服务的吞吐量。
环境准备
使用docker镜像来进行测试非常的方便,一般对应版本的tritonserver都会有一个tritonserver-sdk的版本,例如21.10需要准备的镜像如下
nvcr.io/nvidia/tritonserver:21.10-py3
nvcr.io/nvidia/tritonserver:21.10-py3-sdk
nvcr.io/nvidia/tensorrt:21.10-py3
- tritonserver:tritonserver模型启动服务所需要的镜像
- tritonserver-py3-sdk:包含
perf_analyzer和model-analyzer可以用于做性能测试的镜像 - tensorrt:包含与tritonserver镜像中一样的
tensorrt版本,该镜像主要用来将onnx模型转换为engine用于tritonserver启动模型服务时所需要的模型文件
注:不同版本的版本的镜像所需要的nvidia-driver的版本不一样,21.10所需要的nvida-driver版本为>=470.82(cuda11.4),如果低于该版本时,在启动镜像的时候会提示不兼容。在准备上面镜像的时候tritonserver和tensorrt版本一定要一致,因为不同的版本依赖库以及tensorrt的版本可能会不一样,导致模型可能无法通用
perf_analyzer
- 启动tritonserver模型服务
docker run --gpus all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v triton_models:/models nvcr.io/nvidia/tritonserver:21.10-py3 tritonserver --model-repository=/models
- –gpus:表示启动tritonserver服务是否使用gpu
- –rm:当退出容器的时候会自动删除容器
- -p:用于容器内和宿主机之间的端口映射
- –model-repository:指定tritonserver运行的时候所需要的模型文件

启动之后输出上面的信息就表示tritonserver模型服务启动成功
- 运行
tritonserver-sdk镜像
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:21.10-py3-sdk
因为这里我们只是使用了perf_analyzer性能测试工具,所以其他的启动参数可以不用管
3. 性能测试
perf_analyzer -m resnet34 --percentile=95 --concurrency-range 100
- -m:指定测试的模型
- –percentile:以百分位数表示置信度值用于确定测量结果是否稳定
- –concurrency-range:指定并发量参数,还可以使用,100:120:10表示并发量在100到120之间以10作为间隔测试所有并发量情况下的吞吐量
- -b:指定请求的batch-size,默认为1
- -i:指定请求所使用的协议,参数可以为
http或grpc
其他更多的参数可以通过perf_analyzer -h查看
执行成功之后会输出模型所能承受的吞吐量以及时延
*** Measurement Settings ***
Batch size: 1
Using “time_windows” mode for stabilization
Measurement window: 5000 msec
Using synchronous calls for inference
Stabilizing using p95 latency
Request concurrency: 100
Client:
Request count: 11155
Throughput: 2231 infer/sec
p50 latency: 43684 usec
p90 latency: 61824 usec
p95 latency: 67900 usec
p99 latency: 76275 usec
Avg HTTP time: 45183 usec (send/recv 161 usec + response wait 45022 usec)
Server:
Inference count: 13235
Execution count: 722
Successful request count: 722
Avg request latency: 29032 usec (overhead 629 usec + queue 11130 usec + compute input 7317 usec + compute infer 9889 usec + compute output 67 usec)
Inferences/Second vs. Client p95 Batch Latency
Concurrency: 100, throughput: 2231 infer/sec, latency 67900 usec
在使用http协议进行测试的时候,可能会存在比较大的波动,小伙伴们可以多测试几组来取平均值,grpc协议相对来说更加稳定一些。
我们最重要的是关注最后一行的输出信息,表示在100并发的请求下,tritonserver的吞吐量可以达到2231请求/s,时延是67900微秒。可以看出tritonserver模型服务的推理能力还是很强的,显卡是RTX3090,在只使用了一个count的情况下ResNet34可以达到2200FPS
model-analyzer
- 启动
tritonserver-sdk
docker run --gpus 1 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -ti -v /var/run/docker.sock:/var/run/docker.sock --net host --privileged --rm -v /home/***/triton_models:/models -v /data/reports:/data/reports nvcr.io/nvidia/tritonserver:21.10-py3-sdk bash
这里需要注意的是,我们在这里不需要再去启动tritonserver模型服务了,但是启动的参数多了很多,上面这些参数都是必要的
- v指定docker.sock是让容器能够启动tritonser模型服务容器
- /data/reports:/data/reports:指定模型测试报告存储的路径,这里容器内外的路径需要保持一致,否则后面再使用model-analyzer的时候会报错
- 创建tritonserver可执行文件
touch /opt/tritonserver
chmod +x /opt/tritonserver
- 启动model-analyzer测试
model-analyzer profile --model-repository /models --profile-models resnet34 --run-config-search-max-concurrency 2 --run-config-search-max-instance-count 2 --gpus '0' --triton-launch-mode=docker --output-model-repository=/data/reports/resnet34 --triton-server-path=/opt/tritonserver --override-output-model-repository
- profile:
- model-repository:指定模型保存的目录,这里可以是包含多个模型的目录
- profile-models :指定测试模型的名字
- run-config-search-max-concurrency:最大的并发数
- run-config-search-max-instance-count:最大的count也就是模型实例数
- triton-launch-mode:docker或local,如果是local的时候需要容器内安装tritonserver,这里使用的是docker
- output-model-repository:测试报告保存的目录
- override-output-model-repository:每次测试的时候都会覆盖之前的测试报告
为了加快测试的速度,这里我将count设置为2,concurrency 也设置为2,在实际使用的过程中小伙伴们可以设置一个范围,使用min和max来进行控制,而不要直接固定住这些参数。因为我们最终需要的是得到count、concurrency、batch-size这些参数的最优值。
注:需要注意triton-model-analyzer的版本,不同的版本指定的参数会不一样,这里triton-model-analyzer==1.9.0,小伙伴们可以通过model-analyzer -h来查看参数。

执行成功之后我们会得到一个ckpt的文件
- 导出模型的性能报告
mkdir analysis_results
model-analyzer analyze --analysis-models resnet34 -e analysis_results

5. 查看结果
拷贝报告,将容器内的报告拷贝到宿主机上,通过docker ps -a来查看容器的id
docker cp 5610298c2c93:/workspace/analysis_results ./
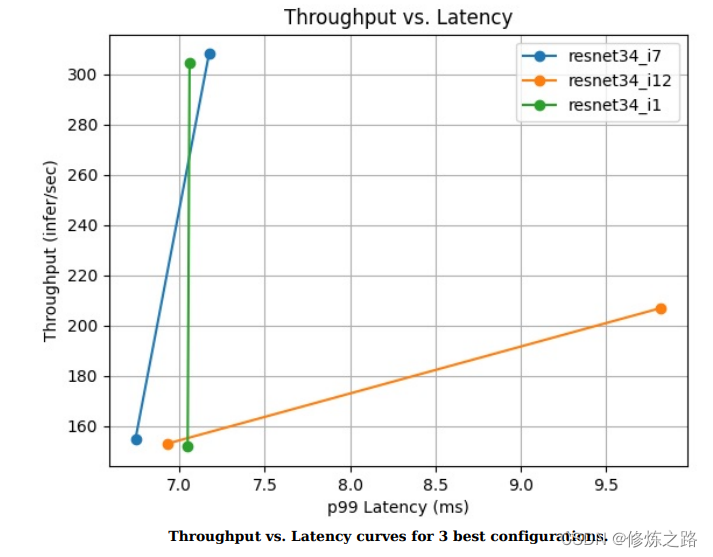
在/analysis_results/reports/summaries/resnet34目录下有一个result_summary.pdf文件里面记录了模型的性能参数

这里吞吐量低的主要原因是因为我们把最大的并发数设置为2了,大家在使用的时候可以设置大一点,参数搜索的范围越大所需要的时间就会越长
相关错误以及解决办法
- 启动
tritonserver服务失败
I0903 13:53:33.877351 1 server.cc:233] Waiting for in-flight requests to complete.
I0903 13:53:33.877375 1 server.cc:248] Timeout 30: Found 0 live models and 0 in-flight non-inference requests
error: creating server: Internal - failed to load all models
模型服务启动失败时,注意看前面的错误信息,前面会有显示每个模型的加载状态以及加载失败的原因

上面错误的原因是因为在转换启动模型文件的时候,所使用的tensorrt版本与容器内tensorrt的版本不一致导致加载失败,通过使用与tritonserver版本一致的tensorrt进行将onnx模型重新转换一下即可。
2. Failed to set the value for field “triton_server_path”
2023-09-03 14:45:35.892 ERROR[entrypoint.py:214] Model Analyzer encountered an error: Failed to set the value for field “triton_server_path”. Error: Either the binary ‘tritonserver’ is not on the PATH, or Model Analyzer does not have permissions to execute os.stat on this path.
touch /opt/tritonserver
chmod +x /opt/tritonserver
- OSError: [Errno 16] Device or resource busy: ‘/data/reports’
在执行model-analyzer的时候提示resource busy,详细错误信息如下
2023-09-04 02:52:07.192 ERROR[entrypoint.py:214] Model Analyzer encountered an error: Failed to set the value for field “triton_server_path”. Error: Either the binary ‘/opt/tritonserver’ is not on the PATH, or Model Analyzer does not have permissions to execute os.stat on this path.
root@zhouwen3090:/workspace# touch /opt/tritonserver
root@zhouwen3090:/workspace# chmod +x /opt/tritonserver
root@zhouwen3090:/workspace# model-analyzer profile --model-repository /models --profile-models resnet34 --run-config-search-max-concurrency 1 --run-config-search-max-instance-count 1 --gpus ‘0’ --triton-launch-mode=docker --output-model-repository=/data/models/reports --triton-server-path=/opt/tritonserver --override-output-model-repository
2023-09-04 02:52:22.668 INFO[gpu_device_factory.py:50] Initiliazing GPUDevice handles…
2023-09-04 02:52:23.764 INFO[gpu_device_factory.py:246] Using GPU 0 NVIDIA GeForce RTX 3090 with UUID GPU-82eb2e4d-c579-7908-39c9-92201438f73c
Traceback (most recent call last):
File “/usr/local/bin/model-analyzer”, line 8, in
sys.exit(main())
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 289, in main
create_output_model_repository(config)
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 249, in create_output_model_repository
os.mkdir(config.output_model_repository_path)
FileNotFoundError: [Errno 2] No such file or directory: ‘/data/models/reports’
root@zhouwen3090:/workspace# model-analyzer profile --model-repository /models --profile-models resnet34 --run-config-search-max-concurrency 1 --run-config-search-max-instance-count 1 --gpus ‘0’ --triton-launch-mode=docker --output-model-repository=/data/reports --triton-server-path=/opt/tritonserver --override-output-model-repository
2023-09-04 02:53:38.665 INFO[gpu_device_factory.py:50] Initiliazing GPUDevice handles…
2023-09-04 02:53:39.750 INFO[gpu_device_factory.py:246] Using GPU 0 NVIDIA GeForce RTX 3090 with UUID GPU-82eb2e4d-c579-7908-39c9-92201438f73c
Traceback (most recent call last):
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 249, in create_output_model_repository
os.mkdir(config.output_model_repository_path)
FileExistsError: [Errno 17] File exists: ‘/data/reports’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/usr/local/bin/model-analyzer”, line 8, in
sys.exit(main())
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 289, in main
create_output_model_repository(config)
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 258, in create_output_model_repository
shutil.rmtree(config.output_model_repository_path)
File “/usr/lib/python3.8/shutil.py”, line 722, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File “/usr/lib/python3.8/shutil.py”, line 720, in rmtree
os.rmdir(path)
OSError: [Errno 16] Device or resource busy: ‘/data/reports’
只需要修改一下--output-model-repository=/data/reports指定的路径即可,在后面增加一个模型的名称修改为--output-model-repository=/data/reports/resnet34
4. /usr/bin/wkhtmltopdf: error while loading shared libraries: libQt5Core.so.5: cannot open shared object file: No such file or directory
strip --remove-section=.note.ABI-tag /usr/lib/x86_64-linux-gnu/libQt5Core.so.5
参考
- https://github.com/triton-inference-server/client/blob/main/src/c%2B%2B/perf_analyzer/docs/cli.md
- https://github.com/triton-inference-server/model_analyzer/tree/main/docs
- https://github.com/triton-inference-server/model_analyzer/blob/main/docs/quick_start.md
- https://github.com/triton-inference-server/model_analyzer/blob/main/docs/install.md
- https://github.com/triton-inference-server/model_analyzer/issues/120

欢迎来到由智源人工智能研究院发起的Triton中文社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)